
Cho tới bây giờ, ngoài thuật toán lười K-nearest neighbors, tôi đã giới thiệu với bạn đọc hai thuật toán cho các bài toán Classification: Perceptron Learning Algorithm và Logistic Regression. Hai thuật toán này được xếp vào loại Binary Classifiers vì chúng được xây dựng dựa trên ý tưởng về các bài toán classification với chỉ hai classes. Trong bài viết này, tôi sẽ cùng các bạn làm một vài ví dụ nhỏ về ứng dụng đơn giản (nhưng thú vị) của các binary classifiers, và cách mở rộng chúng để áp dụng cho các bài toán với nhiều classes (multi-class classification problems).
Vì Logistic Regression chỉ yêu cầu các classes là nearly linearly separable (tức có thể có vài điểm làm phá vỡ tính linear separability), tôi sẽ sử dụng Logistic Regression để đại diện cho các binary classifiers. Chú ý rằng, có rất nhiều các thuật toán cho binary classification nữa mà tôi chưa giới thiệu. Tạm thời, với những gì đã viết, tôi chỉ sử dụng Logistic Regression cho các ví dụ với code mẫu. Các kỹ thuật trong bài viết này hoàn toàn có thể áp dụng cho các binary classifiers khác.
Trong trang này:
- 1. Bài toán phân biệt giới tính dựa trên ảnh khuôn mặt
- 2. Bài toán phân biệt hai chữ số viết tay
- 3. Binary Classifiers cho Multi-class Classification problems
- 4. Thảo luận
- 5. Tài liệu tham khảo
1. Bài toán phân biệt giới tính dựa trên ảnh khuôn mặt
Chúng ta cùng bắt đầu với bài toán phân biệt giới tính dựa trên ảnh khuôn mặt. Về ảnh khuôn mặt, bộ cơ sở dữ liệu AR Face Database được sử dụng rộng rãi.
Bộ cơ sở dữ liệu này bao gồm hơn 4000 ảnh màu tương ứng với khuôn mặt của 126 người (70 nam, 56 nữ). Với mỗi người, 26 bức ảnh được chụp ở các điều kiện ánh sáng khác nhau, sắc thái biểu cảm khuôn mặt khác nhau, và bị che mắt (bởi kính râm) hoặc miệng (bởi khăn); và được chụp tại hai thời điểm khác nhau cách nhau 2 tuần.
Để cho đơn giản, tôi sử dụng bộ cơ sử AR Face thu gọn (có thể tìm thấy trong cùng trang web phía trên, mục Other (relevant) downloads). Bộ cơ sở dữ liệu thu gọn này bao gồm 2600 bức ảnh từ 50 nam và 50 nữ. Hơn nữa, các khuôn mặt cũng đã được xác định chính xác và được cropped với kích thước 165 x 120 (pixel) bằng phương pháp được mô tả trong bài báo PCA veus LDA. Tôi xin bỏ qua phần xử lý này và trực tiếp sử dụng ảnh đã cropped như một số ví dụ dưới đây:

Lưu ý:
-
Vì lý do bản quyền, tôi không được phép chia sẻ với các bạn bộ dữ liệu này. Các bạn muốn sở hữu có thể liên lạc với tác giả như hướng dẫn ở trong website AR Face Database. Một khi các bạn đã có tài khoản để download, tôi mong các bạn tôn trọng tác giả và không chia sẻ trực tiếp với bạn bè.
-
Có một cách đơn giản và nhanh hơn để lấy được các feature vector (sau bước Feature Engineering) của cơ sở dữ liệu này mà không cần liên lạc với tác giả. Các bạn có thể tìm tại đây, phần Downloads, mục Random face features for AR database.
Mỗi bức ảnh trong AR Face thu gọn được đặt tên dưới dạng G-xxx-yy.bmp Trong đó: G nhận một trong hai giá trị M (man) hoặc W (woman); xxx là id của người, nhận gía trị từ 001 đến 050; yy là điều kiện chụp, nhận giá trị từ 01 đến 26, trong đó các điều kiện có số thứ tự từ 01 đến 07 và từ 14 đến 20 là các khuôn mặt không bị che bởi kính hoặc khăn. Tôi tạm gọi mỗi điều kiện này là một view.
Để làm ví dụ cho thuật toán Logistic Regression, tôi lấy ảnh của 25 nam và 25 nữ đầu tiên làm tập training set; 25 nam và 25 nữ còn lại làm test set. Với mỗi người, tôi chỉ lấy các khuôn mặt không bị che bởi kính và khăn.
Feature Extraction: vì mỗi bức ảnh có kích thước 3x165x120 (số channels 3, chiều cao 165, chiều rộng 120) là một số khá lớn nên ta sẽ làm thực hiện Feature Extraction bằng hai bước đơn giản sau (bạn đọc được khuyến khích đọc bài Giới thiệu về Feature Engineering):
-
Chuyển ảnh màu về ảnh xám theo công thức
Y' = 0.299 R + 0.587 G + 0.114 B(Xem thêm tại Grayscale - wiki). -
Kéo dài ảnh xám thu được thành 1 vector hàng có số chiều
165x120, sau đó sử dụng một random projection matrix để giảm số chiều về500. Bạn đọc có thể thay giá trị này bằng các số khác nhỏ hơn1000.
Chúng ta có thể bắt đầu làm việc với Python ngay bây giờ. Tôi sẽ sử dụng hàm sklearn.linear_model.LogisticRegression trong thư viện sklearn cho các ví dụ trong bài này. Nếu không muốn đọc phần này, bạn có thể lấy source code ở dây.
Chú ý: Hàm sklearn.linear_model.LogisticRegression nhận dữ liệu ở dạng vector hàng.
Làm việc với Python
Khai báo thư viện
import numpy as np
from sklearn import linear_model # for logistic regression
from sklearn.metrics import accuracy_score # for evaluation
from scipy import misc # for loading image
np.random.seed(1) # for fixing random values
Phân chia training set và test set, lựa chọn các views.
path = '../data/AR/' # path to the database
train_ids = np.arange(1, 26)
test_ids = np.arange(26, 50)
view_ids = np.hstack((np.arange(1, 8), np.arange(14, 21)))
Tạo random projection matrix.
D = 165*120 # original dimension
d = 500 # new dimension
# generate the projection matrix
ProjectionMatrix = np.random.randn(D, d)
Xây dựng danh sách các tên files.
def build_list_fn(pre, img_ids, view_ids):
"""
INPUT:
pre = 'M-' or 'W-'
img_ids: indexes of images
view_ids: indexes of views
OUTPUT:
a list of filenames
"""
list_fn = []
for im_id in img_ids:
for v_id in view_ids:
fn = path + pre + str(im_id).zfill(3) + '-' + \
str(v_id).zfill(2) + '.bmp'
list_fn.append(fn)
return list_fn
Feature Extraction: Xây dựng dữ liệu cho training set và test set.
def rgb2gray(rgb):
# Y' = 0.299 R + 0.587 G + 0.114 B
return rgb[:,:,0]*.299 + rgb[:, :, 1]*.587 + rgb[:, :, 2]*.114
# feature extraction
def vectorize_img(filename):
# load image
rgb = misc.imread(filename)
# convert to gray scale
gray = rgb2gray(rgb)
# vectorization each row is a data point
im_vec = gray.reshape(1, D)
return im_vec
def build_data_matrix(img_ids, view_ids):
total_imgs = img_ids.shape[0]*view_ids.shape[0]*2
X_full = np.zeros((total_imgs, D))
y = np.hstack((np.zeros((total_imgs/2, )), np.ones((total_imgs/2, ))))
list_fn_m = build_list_fn('M-', img_ids, view_ids)
list_fn_w = build_list_fn('W-', img_ids, view_ids)
list_fn = list_fn_m + list_fn_w
for i in range(len(list_fn)):
X_full[i, :] = vectorize_img(list_fn[i])
X = np.dot(X_full, ProjectionMatrix)
return (X, y)
(X_train_full, y_train) = build_data_matrix(train_ids, view_ids)
x_mean = X_train_full.mean(axis = 0)
x_var = X_train_full.var(axis = 0)
def feature_extraction(X):
return (X - x_mean)/x_var
X_train = feature_extraction(X_train_full)
X_train_full = None ## free this variable
(X_test_full, y_test) = build_data_matrix(test_ids, view_ids)
X_test = feature_extraction(X_test_full)
X_test_full = None
Chú ý: Trong đoạn code trên tôi có sử dụng phương pháp chuẩn hóa dữ liệu Standardization. Trong đó x_mean và x_var lần lượt là vector kỳ vọng và phương sai của toàn bộ dữ liệu training. X_train_full, X_test_full là các ma trận dữ liệu đã được giảm số chiều nhưng chưa được chuẩn hóa. Hàm feature_extraction giúp chuẩn hóa dữ liệu dựa vào x_mean và x_var của X_train_full.
Đoạn code dưới đây thực hiện thuật toán Logistic Regression, dự đoán output của test data và đánh giá kết quả. Một chú ý nhỏ, hàm Logistic Regression trong thư viện sklearn có nhiều biến thể khác nhau. Để sử dụng thuật toán Logistic Regression thuần mà tôi đã giới thiệu trong bài Logistic Regression, chúng ta cần đặt giá trị cho C là một số lớn (để nghịch đảo của nó gần với 0. Tạm thời các bạn chưa cần quan tâm tới điều này, chỉ cần chọn C lớn là được).
logreg = linear_model.LogisticRegression(C=1e5) # just a big number
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
print "Accuracy: %.2f %%" %(100*accuracy_score(y_test, y_pred))
Accuracy: 90.33 %
90.33%, tức là cứ 10 bức ảnh trong test set thì có trung bình hơn 9 bức được nhận dạng đúng. Không tệ, nhất là khi chúng ta vẫn chưa phải làm gì nhiều!
Để xác định nhãn của một ảnh, đầu ra của hàm sigmoid được so sánh với 0.5. Nếu giá trị đó lớn hơn 0.5, ta kết luận đó là ảnh của nam, ngược lại, đó là ảnh của nữ. Để xem giá trị sau hàm sigmoid (tức xác suất để ảnh đó là nam), chúng ta sử dụng hàm predict_proba như sau:
def feature_extraction_fn(fn):
"""
extract feature from filename
"""
# vectorize
im = vectorize_img(fn)
# project
im1 = np.dot(im, ProjectionMatrix)
# standardization
return feature_extraction(im1)
fn1 = path + 'M-036-18.bmp'
fn2 = path + 'W-045-01.bmp'
fn3 = path + 'M-048-01.bmp'
fn4 = path + 'W-027-02.bmp'
x1 = feature_extraction_fn(fn1)
p1 = logreg.predict_proba(x1)
print(p1)
x2 = feature_extraction_fn(fn2)
p2 = logreg.predict_proba(x2)
print(p2)
x3 = feature_extraction_fn(fn3)
p3 = logreg.predict_proba(x3)
print(p3)
x4 = feature_extraction_fn(fn4)
p4 = logreg.predict_proba(x4)
print(p4)
[[ 0.87940218 0.12059782]]
[[ 0.0172217 0.9827783]]
[[ 0.30458761 0.69541239]]
[[ 0.83989242 0.16010758]]
Kết quả thu được là xác suất để bức ảnh đó là ảnh của nam (cột thứ nhất) và của nữ (cột thứ hai). Dưới đây là hình minh họa:

Hàng trên gồm các hình được phân loại đúng, hàng dưới gồm các hình bị phân loại sai. Có một vài nhận xét về hàng dưới. Từ hai bức ảnh hàng dưới, chúng ta có thể đoán rằng Logistic Regression quan tâm đến tóc phía sau gáy nhiều hơn là râu! Việc thuật toán dựa trên những đặc trưng nào của mỗi class phụ thuộc rất nhiều vào training data. Nếu trong training data, hầu hết nam không có râu và hầu hết nữ có tóc dài thì kết quả này là có thể lý giải được.
Trong Machine Learning, thuật toán là quan trọng, nhưng thuật toán tốt mà dữ liệu không tốt thì sẽ dẫn đến những tác dụng ngược!
(Source code cho ví dụ này có thể tìm thấy ở dây.)
2. Bài toán phân biệt hai chữ số viết tay
Chúng ta cùng sang ví dụ thứ hai về phân biệt hai chữ số trong bộ cơ sở dữ liệu MNIST. Cụ thể, tôi sẽ làm việc với hai chữ số 0 và 1. Bạn đọc hoàn toàn có thể thử với các chữ số khác bằng cách thay đổi một dòng lệnh. Khác với AR Face, bộ dữ liệu này có thể dễ dàng được download về từ trang chủ của nó.
Chúng ta có thể bắt tay vào làm luôn.
Khai báo thư viện:
# %reset
import numpy as np
from mnist import MNIST
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.metrics import accuracy_score
from display_network import *
Load toàn bộ dữ liệu:
mntrain = MNIST('../MNIST/')
mntrain.load_training()
Xtrain_all = np.asarray(mntrain.train_images)
ytrain_all = np.array(mntrain.train_labels.tolist())
mntest = MNIST('../MNIST/')
mntest.load_testing()
Xtest_all = np.asarray(mntest.test_images)
ytest_all = np.array(mntest.test_labels.tolist())
Sau bưóc này, toàn bộ dữ liệu training data và test data được lưu ở hai ma trận X_train_all và X_test_all, mỗi hàng của các ma trận này chứa một điểm dữ liệu, tức một bức ảnh đã được vector hóa.
Để lấy các hàng tương ứng với chữ số 0 và chữ số 1, ta khai báo biến sau:
cls = [[0], [1]]
Nếu bạn muốn thử với cặp 3 và 4, chỉ cần thay dòng này bằng cls = [[3], [4]]. Nếu bạn muốn phân loại (4, 7) và (5, 6), chỉ cần thay dòng này bằng cls = [[4, 7], [5, 6]]. Các cặp bất kỳ khác đều có thể thực hiện bằng cách thay chỉ một dòng này.
Đoạn code dưới đây thực hiện việc extract toàn bộ dữ liệu cho các chữ số 0 và 1 trong tập training data và test data.
def extract_data(X, y, classes):
"""
X: numpy array, matrix of size (N, d), d is data dim
y: numpy array, size (N, )
cls: two lists of labels. For example:
cls = [[1, 4, 7], [5, 6, 8]]
return:
X: extracted data
y: extracted label
(0 and 1, corresponding to two lists in cls)
"""
y_res_id = np.array([])
for i in cls[0]:
y_res_id = np.hstack((y_res_id, np.where(y == i)[0]))
n0 = len(y_res_id)
for i in cls[1]:
y_res_id = np.hstack((y_res_id, np.where(y == i)[0]))
n1 = len(y_res_id) - n0
y_res_id = y_res_id.astype(int)
X_res = X[y_res_id, :]/255.0
y_res = np.asarray([0]*n0 + [1]*n1)
return (X_res, y_res)
# extract data for training
(X_train, y_train) = extract_data(Xtrain_all, ytrain_all, cls)
# extract data for test
(X_test, y_test) = extract_data(Xtest_all, ytest_all, cls)
Vì mỗi điểm dữ liệu có số phần tử là 784 (28x28), là một số khá nhỏ, nên ta không cần thêm bước giảm số chiều dữ liệu nữa. Tuy nhiên, tôi có thực hiện thêm một bước chuẩn hóa để đưa dữ liệu về đoạn [0, 1] bằng cách chia toàn bộ hai ma trận dữ liệu cho 255.0.
Tới đây ta có thể train mô hình Logistic Regression và đánh giá mô hình này.
# train the logistic regression model
logreg = linear_model.LogisticRegression(C=1e5) # just a big number
logreg.fit(X_train, y_train)
# predict
y_pred = logreg.predict(X_test)
print "Accuracy: %.2f %%" %(100*accuracy_score(y_test, y_pred.tolist()))
Accuracy: 99.95 %
Tuyệt vời, gần như 100% được phân loại chính xác. Điều này là dễ hiểu vì hai chữ số 0 và 1 khác nhau quá nhiều. Bộ cơ sở dữ liệu này với toàn bộ 10 classes hiện nay đã được phân loại với độ chính xác trên 99.7%.
Chúng ta cùng đi tìm những ảnh bị phân loại sai:
# display misclassified image(s)
mis = np.where((y_pred - y_test) != 0)[0]
Xmis = X_test[mis, :]
plt.axis('off')
A = display_network(Xmis.T)
f2 = plt.imshow(A, interpolation='nearest' )
plt.gray()
plt.show()

Như vậy là chỉ có một ảnh bị phân loại sai. Ảnh này là chữ số 0 nhưng bị misclassified thành chữ số 1, có thể vì nét đậm nhất của nó rất giống với chữ số 1.
Source code cho ví dụ này có thể được tìm thấy ở đây.
3. Binary Classifiers cho Multi-class Classification problems
Có lẽ nhiều bạn đang đặt câu hỏi: Các ví dụ trên đây đều làm với bài toán có hai classes. Vậy nếu có nhiều hơn hai classes, ví dụ như 10 classes của MNIST, thì làm thế nào?
Có nhiều thuật toán khác được xây dựng riêng cho các bài toán với nhiều classes (multi-class classification problems), tôi sẽ giới thiệu sau. Còn bây giờ, chúng ta vẫn có thể sử dụng các binary classifiers để thực hiện công việc này, với một chút thay đổi.
Có ít nhất bốn cách để áp dụng binary classifiers vào các bài toán multi-class classification:
One-vs-one
Xây dựng rất nhiều bộ binary classifiers cho từng cặp classes. Bộ thứ nhất phân biệt class 1 và class 2, bộ thứ hai phân biệt class 1 và class 3, … Khi có một dữ liệu mới vào, đưa nó vào toàn bộ các bộ binary classifiers trên. Kết quả cuối cùng có thể được xác định bằng cách xem class nào mà điểm dữ liệu đó được phân vào nhiều nhất (major voting). Hoặc với Logistic Regression thì ta có thể tính tổng các xác suất tìm được sau mỗi bộ binary classifier.
Như vậy, nếu có \(C\) classes thì tổng số binary classifiers phải dùng là \(\frac{n(n-1)}{2}\). Đây là một con số lớn, cách làm này không lợi về tính toán. Hơn nữa, nếu một chữ số thực ra là chữ số 1, nhưng lại được đưa vào bộ phân lớp giữa các chữ số 5 và 6, thì cả hai khả năng tìm được (là 5 hoặc 6) đều không hợp lý!
Hierarchical (phân tầng)
Các làm như one-vs-one sẽ mất rất nhiều thời gian training vì có quá nhiều bộ phân lớp cần được xây dựng. Một cách khác giúp tiết kiệm số binary classifiers hơn đó là hierarchical. Ý tưởng như sau:
Ví dụ với MNIST với 4 chữ số 4, 5, 6, 7. Vì ta thấy chữ số 4 và 7 khá giống nhau, chữ số 5 và 6 khá giống nhau nên trước tiên chúng ta xây dựng bộ phân lớp [4, 7] vs [5, 6]. Sau đó xây dựng thêm hai bộ 4 vs 7 và 5 vs 6 nữa. Tổng cộng, ta cần 3 bộ binary classifiers. Chú ý rằng có nhiều cách chia khác nhau, ví dụ [4, 5, 6] vs 7, [4, 5] vs 6, rồi 4 vs 5.
Ưu điểm của phương pháp này là sử dụng ít bộ binary classifiers hơn one-vs-one.
Hạn chế lớn nhất của nó là việc nếu chỉ một binary classifier cho kết quả sai thì kết quả cuối cùng chắc chắn sẽ sai. Ví dụ, nếu 1 ảnh chứa chữ số 5, nhưng ngay bước đầu tiên đã bị misclassifed sang nhánh [4, 7] thì kết quả cuối cùng sẽ là 4 hoặc 7, cả hai đều sai.
Binary coding
Có một cách giảm số binary classifiers hơn nữa là binary coding, tức mã hóa output của mỗi class bằng một số nhị phân. Ví dụ, nếu có 4 classes thì class thứ nhất được mã hóa là 00, ba class kia được mã hóa lần lượt là 01, 10 và 11. Với cách làm này, số bộ binary classifiers phải thực hiện chỉ là \(m = \left\lceil\log_2(C)\right\rceil\) trong đó \(C\) là số lượng class, \(\left\lceil a \right\rceil\) là số nguyên nhỏ nhất không nhỏ hơn \(a\). Class thứ nhất sẽ đi tìm bit đầu tiên của output (đã được mã hóa nhị phân), class thứ hai sẽ đi tìm bit thứ hai, …
Cách làm này sử dụng một số lượng nhỏ nhất các bộ binary classifiers. Nhưng nó có một hạn chế rất lớn là chỉ cần một bit bị phân loại sai sẽ dẫn đến dữ liệu bị phân loại sai. Hơn nữa, nếu số classes không phải là lũy thừa của hai, mã nhị phân nhận được có thể là một giá trị không tương ứng với class nào!
one-vs-rest hay one-hot coding
Phương pháp được sử dụng nhiều nhất là one-vs-rest (một số tài liệu gọi là ove-vs-all, one-against-rest, hoặc one-against-all) . Cụ thể, nếu có \(C\) classes thì ta sẽ xây dựng \(C\) classifiers, mỗi classifier tương ứng với một class. Classifier thứ nhất giúp phân biệt class 1 vs not class 1, tức xem một điểm có thuộc class 1 hay không, hoặc xác suất để một điểm rơi vào class 1 là bao nhiêu. Tương tự như thế, classifier thứ hai sẽ phân biệt class 2 vs not class 2, … Kết quả cuối cùng có thể được xác định bằng cách xác định class mà một điểm rơi vào với xác suất cao nhất.
Phương pháp này còn được gọi là one-hot coding (được sử dụng nhiều nên có rất nhiều tên) vì với cách mã hóa trên, giả sử có 4 classes, class 1, 2, 3, 4 sẽ lần lượt được mã hóa dưới dạng nhị phân bởi 1000, 0100, 0010 hoặc 0001. One-hot vì chỉ có one bit là hot (bằng 1).
Hàm Logistic Regression trong thư viện sklearn có thể được dùng trực tiếp để áp dụng vào các bài toán multi-class classification với phương pháp one-vs-rest. Với bài toán MNIST như nêu ở phần 2, ta có thể thêm ba dòng lệnh sau để chạy trên toàn bộ 10 classes:
logreg.fit(Xtrain_all, ytrain_all)
y_pred = logreg.predict(Xtest_all)
print "Accuracy: %.2f %%" %(100*accuracy_score(ytest_all, y_pred.tolist()))
Kết quả thu được khoảng 91% sau hơn 20 phút chạy (tùy thuộc vào máy). Đây vẫn là một kết quả quá thấp so với con số 99.7%. Thậm chí phương pháp học máy không học gì như K-neareast neighbors cũng đã đạt hơn 96% với thời gian chạy ngắn hơn một chút.
Một chú ý nhỏ: phương pháp mặc định cho các bài toán multi-class của hàm này được xác định bởi biến multi_class. Có hai lựa chọn cho biến này, trong đó lựa chọn mặc định là ovr tức one-vs-rest, lựa chọn còn lại sẽ được tôi đề cập trong một bài gần đây. Lựa chọn thứ hai không phải cho binary classifiers nên tôi không đề cập trong bài này, có thể sau một vài bài nữa (Xem thêm sklearn.linear_model.LogisticRegression)
4. Thảo luận
Kết hợp các phương pháp trên
Nhắc lại rằng các linear binary classifiers tôi đã trình bày yêu cầu dữ liệu là linearly separable hoặc nearly linearly separable. Ta cũng có thể mở rộng định nghĩa này cho các bài toán multi-class. Nếu hai class bất kỳ là linearly separable thì ta coi dữ liệu đó là linearly separable.
Thế nhưng, có những loại dữ liệu linearly separable mà chỉ một số trong 4 phương pháp trên đây là phù hợp, hoặc có những loại dữ liệu yêu cầu phải kết hợp nhiều phương pháp mới thực hiện được. Xét ba ví dụ sau:

-
Hình 4a): cả 4 phương pháp trên đây đều có thể áp dụng được.
-
Hình 4b): one-vs-rest không phù hợp vì class màu xanh lục và class rest (hợp của xanh lam và đỏ) là không linearly separable. Lúc này, one-vs-one hoặc hierarchical phù hợp hơn.
-
Hình 4c): Tương tự như trên, ba class lam, lục, đỏ thẳng hàng nên sẽ không dùng được one-vs-rét. one-vs-one vẫn làm việc vì từng đôi class một là linearly separable. Tương tự hierarchical cũng làm việc nếu ta phân chia các nhóm một cách hợp lý. Hoặc chúng ta có thể kết hợp nhiều phương pháp. Ví dụ: dùng one-vs-rest để tìm đỏ vs không đỏ. Nếu một điểm dữ liệu là không đỏ, với 3 class còn lại, chúng ta lại quay lại trường hợp Hình 4a) và có thể dùng các phương pháp khác. Nhưng khó khăn vẫn nằm ở việc phân nhóm như thế nào, liệu rằng những class nào có thể cho vào cùng một nhóm? Với những dữ liệu đơn giản, K-means clustering có thể là một giải pháp!
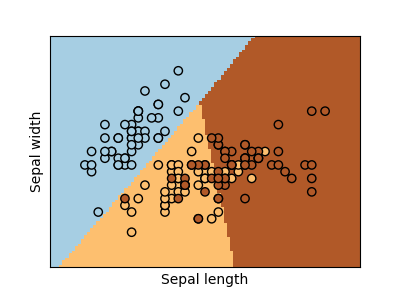
Bạn đọc có thể xem thêm ví dụ áp dụng Logistic Regression cho cơ sở dữ liệu Iris trong link này
Biểu diễn dưới dạng Neural Networks
Lấy ví dụ với bài toán có 4 classes 1, 2, 3, 4; ta có thể biểu diễn các mô hình được đề cập trong phần 3 dưới dạng sau đây (giả sử input có số chiều là 7 và node output màu đỏ biểu diễn chung cho cả PLA, Logistic Regression và các networks với activation function khác):

Lúc này, thay vì chỉ có 1 node output như các phương pháp tôi đề cập trước đây (Linear Regression, Perceptron Learning Algorithm, Logistic Regression), chúng ta thấy rằng các networks này đều có nhiều outputs. Và một vector trọng số \(\mathbf{w}\) bây giờ đã trở thành ma trận trọng số \(\mathbf{W}\) mà mỗi cột của nó tương ứng với vector trọng số của một node output. Việc tối ưu đồng thời các binary classifiers trong mỗi network cũng được tổng quát lên nhớ các phép tính với ma trận.
Lấy ví dụ với công thức cập nhật của logistic sigmoid regression :
\[ \mathbf{w} = \mathbf{w} + \eta(y_i - z_i)\mathbf{x}_i \]
Có thể tổng quát thành: \[ \mathbf{W} = \mathbf{W} + \eta\mathbf{x}_i(\mathbf{y}_i - \mathbf{z}_i)^T \]
Với \(\mathbf{W}, \mathbf{y}_i, \mathbf{z}_i\) lần lượt là ma trận trọng số, vector (cột) output thật với toàn bộ các binary classifiers tương ứng với điểm dữ liệu \(\mathbf{x}_i\), và vector output tìm được của networks tại thời điểm đang xét nếu đầu vào mỗi network là \(\mathbf{x}_i\). Chú ý rằng với Logistic Regression, vector \(\mathbf{y}_i\) là một binary vector, vector \(\mathbf{z}_i\) gồm các phần tử nằm trong khoảng \((0, 1)\).
Hạn chế của one-vs-rest
Xem xét lại phương pháp one-vs-rest theo góc nhìn xác suất, một điểm dữ liệu có thể được dự đoán thuộc vào class \(1, 2, \dots, C\) với xác suất lần lượt là \(p_1, p_2, \dots, p_C\). Tuy nhiên, tổng các xác suất này có thể không bằng 1! Có một phương pháp có thể làm cho nó hợp lý hơn, tức ép tổng các xác suất này bằng 1. Khi đó, với 1 điểm dữ liệu ta có thể nói xác suất nó rơi vào mỗi class là bao nhiêu. Phương pháp hấp dẫn này sẽ được đề cập trong bài Softmax Regression. Mời bạn đón đọc.