
Bạn sẽ hiểu rõ hơn nếu đã đọc các bài:
Trong trang này:
- 1. Giới thiệu
- 2. Xây dựng hàm mất mát cho Multi-class Support Vector Machine
- 3. Tinh toán hàm mất mát và đạo hàm của nó
- 4. Thảo luận
- 5. Tài liệu tham khảo
1. Giới thiệu
1.1.Từ Binary classification tới multi-class classification
Các phương pháp Support Vector Machine đã đề cập (Hard Margin, Soft Margin, Kernel) đều được xây dựng nhằm giải quyết bài toán Binary Classification, tức bài toán phân lớp với chỉ hai classes. Việc này cũng tương tự như Percetron Learning Algorithm hay Logistic Regression vậy. Các mô hình làm việc với bài toán có 2 classes còn được gọi là Binary classifiers. Một cách tự nhiên để mở rộng các mô hình này áp dụng cho các bài toán multi-class classification, tức có nhiều classes dữ liệu khác nhau, là sử dụng nhiều binary classifiers và các kỹ thuật như one-vs-one hoặc one-vs-rest. Cách làm này có những hạn chế như đã trình bày trong bài Softmax Regression.
1.2. Mô hình end-to-end
Softmax Regression là mở rộng của Logistic Regression cho bài toán multi-class classification, có thể được coi là một layer của Neural Networks. Nhờ đó, Softmax Regression thường đươc sử dụng rất nhiều trong các bộ phân lớp hiện nay. Các bộ phân lớp cho kết quả cao nhất thường là một Neural Network với rất nhiều layers và layer cuối là một softmax regression, đặc biệt là các Convolutional Neural Networks. Các layer trước thường là kết hợp của các Convolutional layers và các nonlinear activation functions và pooling, các bạn tạm thời chưa cần quan tâm đến các layers phía trước này, tôi sẽ giới thiệu khi có dịp. Có thể coi các layer trước layer cuối là một công cụ giúp trích chọn đặc trưng của dữ liệu (Feature extraction), layer cuối là softmax regression, là một bộ phân lớp tuyến tính đơn giản nhưng rất hiệu quả. Bằng cách này, ta có thể coi là nhiều one-vs-rest classifers được huấn luyện cùng nhau, hỗ trợ lẫn nhau, vì vậy, một cách tự nhiên, sẽ có thể tốt hơn là huấn luyện từng classifier riêng lẻ.
Sự hiệu quả của Softmax Regression nói riêng và Convolutional Neural Networks nói chung là cả bộ trích chọn đặc trưng (feature extractor) và bộ phân lớp (classifier) được huấn luyện đồng thời. Điều này nghĩa là hai bộ phận này bổ trợ cho nhau trong quá trình huấn luyện. Classifier giúp tìm ra các hệ số hợp lý phù hợp với feature vector tìm được, ngược lại, feature extractor lại điều chỉnh các hệ số của các convolutional layer sao cho feature thu được là tuyến tính, phù hợp với classifier ở layer cuối cùng.
Tôi viết đến đây không phải là để giới thiệu về Softmax Regression, mà là đang nói chung đến các mô hình phân lớp hiện đại. Đặc điểm chung của chúng là feature extractor và classifier được huấn luyện một cách đồng thời. Những mô hình như thế này còn được gọi là end-to-end. Cùng xem lại mô hình chung cho các bài toán Machine Learning mà tôi đã đề cập trong Bài 11:

Trong Hình 1, phần TRAINING PHASE, chúng ta có thể thấy rằng có hai khối chính là Feature Extraction và Classification/Regression/Clustering… Các phương pháp truyền thống thường xây dựng hai khối này qua các bước riêng rẽ. Phần Feature Extraction với dữ liệu ảnh có thể dùng các feature descriptor như SIFT, SURF, HOG; với dữ liệu văn bản thì có thể là Bag of Words hoặc TF-IDF. Nếu là các bài toán classification, phần còn lại có thể là SVM thông thường hay các bộ phân lớp truyền thống khác.
Với sự phát triển của Deep Learning trong những năm gần đây, người ta cho rằng các hệ thống end-to-end (từ đầu đến cuối) mang lại kết quả tốt hơn nhờ và việc các hai khối phía trên được huấn luyện cùng nhau, bổ trợ lẫn nhau. Thực tế cho thấy, các phương pháp state-of-the-art thường là các mô hình end-to-end.
Các phương pháp Support Vector Machine được chứng minh là tốt hơn Logistic Regression vì chúng có quan tâm đến việc tạo margin lớn nhất giữa các classes. Câu hỏi đặt ra là:
Liệu có cách nào giúp kết hợp SVM với Neural Networks để tạo ra một bộ phân lớp tốt với bài toán multi-class classification? Hơn nữa, toàn bộ hệ thống có thể được huấn luyện theo kiểu end-to-end?
Câu trả lời sẽ được tìm thấy trong bài viết này, bằng một phương pháp được gọi là Multi-class Support Vector Machine.
Và để cho bài viết hấp dẫn hơn, tôi xin giới thiệu luôn, ở phần cuối, chúng ta sẽ cùng lập trình từ đầu đến cuối để giải quyết bài toán phân lớp với bộ cơ sở dữ liệu nổi tiếng: CIFAR10.
1.3. Bộ cơ sở dữ liệu CIFAR10
Bộ cơ sở dữ liệu CIFAR10 gồm 51000 ảnh khác nhau thuộc 10 classes: plane, car, bird, cat, deer, dog, frog, horse, ship, và truck. Mỗi bức ảnh có kích thước \(32 \times 32\) pixel. Một vài ví dụ cho mỗi class được cho trong Hình 2 dưới đây. 50000 ảnh được sử dụng cho training, 1000 ảnh còn lại được dùng cho test. Trong số 50000 ảnh training, 1000 ảnh sẽ được lấy ra ngẫu nghiên để làm validation set.

Đây là một bộ cơ sở dữ liệu tương đối khó vì ảnh nhỏ và object trong cùng một class cũng biến đổi rất nhiều về màu sắc, hình dáng, kích thước. Thuật toán tốt nhất hiện nay cho bài toán này đã đạt được độ chính xác trên 90%, sử dụng một Convolutional Neural Network nhiều lớp kết hợp với Softmax regression ở layer cuối cùng. Trong bài này, chúng ta sẽ sử dụng một mô hình neural network đơn giản không có hidden layer nào để giải quyết, kết quả đạt được là khoảng 40%, nhưng cũng là đã rất ấn tượng. Layer cuối là một layer Multi-class SVM. Tôi sẽ hướng dẫn các bạn lập trình cho mô hình này từ đầu đến cuối mà không sử dụng một thư viện đặc biệt nào ngoài numpy.
Bài toán này cũng như nội dung chính của bài viết được lấy từ Lecture notes: Linear Classifier II và Assignment #1 trong khoá học CS231n: Convolutional Neural Networks for Visual Recognition kỳ Winter 2016 của Stanford.
Trước khi đi vào mục xây dựng hàm mất mát cho Multi-class SVM, tôi muốn nhắc lại một chút về một chút feature engineering cho ảnh trong CIFAR-10 và bias trick nói chung trong Neural Networks.
1.4. Image data preprocessing
Để cho mọi thứ được đơn giản và có được một mô hình hoàn chỉnh, chúng ta sẽ sử dụng phương pháp feature engineering đơn giản nhất: lấy trực tiếp tất cả các pixel trong mỗi ảnh và thêm một chút normalization.
-
Mỗi ảnh của CIFAR-10 đã có kích thước giống nhau \(32 \times 32\) pixel, vì vậy việc đầu tiên chúng ta cần làm là kéo dài mỗi trong ba channels Red, Green, Blue của bức ảnh ra thành một vector có kích thước là \(3 \times 32 \times 32 = 3072\).
-
Vì mỗi pixel có giá trị là một số tự nhiên từ 0 đến 255 nên chúng ta cần một chút chuẩn hóa dữ liệu. Trong Machine Learning, một cách đơn giản nhất để chuẩn hóa dữ liệu là center data, tức làm cho mỗi feature có trung bình cộng bằng 0. Một cách đơn giản để làm việc này là ta tính trung bình cộng của tất cả các ảnh trong tập training để được ảnh trung bình, sau đó trừ từ tất cả các ảnh đi ảnh trung bình này. Tương tự, ta cũng dùng ảnh trung bình này để chuẩn hoá dữ liệu trong validation set và test set.
1.5. Bias trick
Thông thường, với một ma trận hệ số \(\mathbf{W} \in \mathbb{R}^{d\times C}\), một đầu vào \(\mathbf{x} \in \mathbb{R}^d\) và vector bias \(\mathbf{b} \in \mathbb{R}^C\), chúng ta có thể tính được đầu ra của layer này là: \[ f(\mathbf{x}, \mathbf{W}, \mathbf{b}) = \mathbf{W}^T\mathbf{x} + \mathbf{b} \]
Để cho biểu thức trên đơn giản hơn, ta có thể thêm một phần từ bằng 1 vào cuối của \(\mathbf{x}\) và ghép vector \(\mathbf{b}\) vào ma trận \(\mathbf{W}\) như ví dụ dưới đây:

Bây giờ thì ta chỉ còn 1 biến dữ liệu là \(\mathbf{W}\) thay vì hai biến dữ liệu như trước. Từ giờ trở đi, khi viết \(\mathbf{W}\) và \(\mathbf{x}\), chúng ta ngầm hiểu là biến mới và dữ liệu mới như ở phần bên phải của Hình 3.
2. Xây dựng hàm mất mát cho Multi-class Support Vector Machine
Chúng ta cùng quay lại một chút với ý tưởng của Softmax Regression với hàm mất mát Cross-entropy. Sau đó, chúng ta sẽ làm quen với Multi-class SVM với hàm mất mát hinge loss mở rộng.
2.1. Nhắc lại Softmax Regression.
Chúng ta cùng xem lại Softmax layer đã được trình bày trong Bài 13.

Trong Hình 4 ở trên, dữ liệu trong lớp màu xanh lục được coi như feature vector của dữ liệu. Với dữ liệu CIFAR-10, nếu ta coi mỗi feature là giá trị của từng pixel trong ảnh, tổng số chiều của feature vector cho mỗi bức ảnh là \(32\times 32 \times 3 +1 = 3073\), với 3 là số channels trong bức ảnh (Red, Green, Blue).
Qua ma trận hệ số \(\mathbf{W}\), dữ liệu ban đầu trở thành \(\mathbf{z} = \mathbf{W}^T\mathbf{x}\).
Lúc này, ứng với mỗi một trong \(C\) classes, chúng ta nhận được một giá trị tương ứng \(z_i\) ứng với class thứ \(i\). Giá trị \(z_i\) này còn được gọi là score của dữ liệu \(\mathbf{x}\) ứng với class thứ \(i\).
Ý tưởng chính trong Sofftmax Regression là đi tìm ma trận hệ số \(\mathbf{W}\), mỗi cột của ma trận này ứng với một class, sao cho score vector \(\mathbf{z}\) đạt giá trị lớn nhất tại phần tử tương ứng với class chính xác của nó. Sau khi mô hình đã được trained, nhãn của một điểm dữ liệu mới được tính là vị trí của thành phần score có giá trị lớn nhất trong score vector. Xem ví dụ trong Hình 5 dưới đây:

Để huấn luyện trên tập các cặp (dữ liệu, nhãn), Softmax Regression sử dụng hàm softmax để đưa score vector về dạng phân phối xác suất có các phần tử là dương và có tổng bằng 1. Sau đó dùng hàm cross entropy để ép vector xác suất này gần với vector xác suất thật sự của dữ liệu - tức one-hot vector mà chỉ có đúng 1 phần tử bằng 1 tại class tương ứng, các phần tử còn lại bằng 0.
2.3. Hinge losss tổng quát cho Multi-class SVM
Với Multi-class SVM, trong khi tesst, class của một input cũng được xác định bởi thành phần có giá trị lớn nhất trong score vector. Điều này giống với Softmax Regression.
Softmax Regression sử dụng cross-entropy để ép hai vector xác suất bằng nhau, tức ép phần tử tương ứng với correct class trong vector xác suất gần với 1, đồng thời, các phần tử còn lại trong vector đó gần với 0. Nói cách khác, cách làm này khiến cho phần tử tương ứng với correct class càng lớn hơn các phần tử còn lại càng tốt. Trong khi đó, Multi-class SVM sử dụng một chiến thuật khác cho mục đích tương tự dựa trên score vector. Điểm khác biệt là Multi-class SVM xây dựng hàm mất mát dựa trên định nghĩa của biên an toàn, giống như trong Hard/Soft Margin vậy. Multi-class SVM muốn thành phần ứng với correct class của score vector lớn hơn các phần tử khác, không những thế, nó còn lớn hơn một đại lượng \(\Delta > 0\) gọi là biên an toàn. Hãy xem Hình 6 dưới đây:

Với cách xác định biên như trên, Multi-class SVM sẽ cho qua những scores nằm về phía trước vùng màu đỏ. Những điểm có scores nằm phía phải của ngưỡng (chữ x màu đỏ) sẽ bị xử phạt, và càng vi phạm nhiều sẽ càng bị xử lý ở mức cao.
Để mô tả các mức vi phạm này dưới dạng toán học, trước hết ta giả sử rằng các thành phần của score vector được đánh số thứ tự từ 1. Các classes cũng được đánh số thứ tự từ 1. Giả sử rằng điểm dữ liệu \(\mathbf{x}\) đang xét thuộc class \(y\) và score vector của nó là vector \(\mathbf{z}\). Thế thì score của correct class là \(z_y\), scores của các classes khác là các \(z_i, i \neq y\). Xét ví dụ như trong Hình 6 với hai score \(z_i\) trong vùng an toàn và \(z_j\) trong vùng vi phạm.
-
Với mỗi score \(z_i\) trong vùng an toàn, loss bằng 0.
-
Với mỗi socre \(z_j\) vượt quá điểm an toàn (điểm x đỏ), loss do nó gây ra được tính bằng lượng vượt quá so với điểm x đỏ, đại lượng này có thể tính được là: \(z_j - (z_y - \Delta) = \Delta - z_y + z_j\).
Tóm lại, với một score \(z_j, j \neq y\), loss do nó gây ra có thể được viết gọn thành: \[ \max(0, \Delta - z_y + z_j) = \max(0, \Delta - \mathbf{w}_y^T\mathbf{x} + \mathbf{w}_j^T\mathbf{x}) ~~~~~ (1) \] trong đó \(\mathbf{w}_j\) là cột thứ \(j\) của ma trận hệ số \(\mathbf{W}\).
Như vậy, với một điểm dữ liệu \(\mathbf{x}_n, n = 1, 2, \dots, N\), tổng cộng loss do nó gây ra là: \[ \mathcal{L}_n = \sum_{j \neq y_n} \max(0, \Delta - z_{y_n}^n + z_j^n) \]
trong đó \(\mathbf{z}^n = \mathbf{w}^T\mathbf{x}_n = [z^n_1, z^n_2, \dots, z^n_C]^T \in \mathbb{R}^{C \times 1}\) là scores tương ứng với điểm dữ liệu \(\mathbf{x}_n\); \(y_n\) là correct class của điểm dữ liệu đó.
Với toàn bộ các điểm dữ liệu \(\mathbf{X} = [\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_N ]\), loss tổng cộng là: \[ \mathcal{L}(\mathbf{X}, \mathbf{y}, \mathbf{W}) = \frac{1}{N}\sum_{n=1}^N \sum_{j \neq y_n} \max(0, \Delta - z_{y_n}^n + z_j^n) ~~~~~ (2) \] với \(\mathbf{y} = [y_1, y_2, \dots, y_N]\) là vector chứa corect class của toàn bộ các điểm dữ liệu trong training set. Hệ số \(\frac{1}{N}\) tính trung bình của loss để tránh việc biểu thức này quá lớn gây tràn số máy tính.
Có một bug trong lỗi này, chúng ta cùng phân tích tiếp.
2.4. Regularization
Điều gì sẽ xảy ra nếu nghiệm tìm được \(\mathbf{w}\) là hoàn hảo, tức không có score nào vi phạm và biểu thức \((2)\) đạt giá trị bằng 0? Nói cách khác: \[ \Delta - z_{y_n}^n + z_j^n = \leq 0 \Leftrightarrow \Delta \leq \mathbf{w}_{y_n}^T \mathbf{x}_n - \mathbf{w}_j^T\mathbf{x}_n~\forall n = 1, 2, \dots, N; j = 1, 2, \dots, C; j \neq y_n \]
Điều này có nghĩa là \(k\mathbf{W}\) cũng là một nghiệm của bài toán với \(k > 1\) bất kỳ. Việc bài toán có vô số nghiệm và có những nghiệm có những phần tử tiến tới vô cùng khiến cho bài toán rất unstable khi giải. Một phương pháp quen thuộc để tránh hiện tượng này là cộng thêm số hạng regularization vào hàm mất mát. Số hạng này giúp ngăn chặn việc các hệ số của \(\mathbf{W}\) trở nên quá lớn. Và để cho hàm mất mát vẫn có đạo hàm đơn giản, chúng ta lại sử dụng \(l_2\) regularization:
\[ \mathcal{L}(\mathbf{X}, \mathbf{y}, \mathbf{W}) = \underbrace{\frac{1}{N}\sum_{n=1}^N \sum_{j \neq y_n} \max(0, \Delta - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n)}_{\text{data loss }} + \underbrace{\frac{\lambda}{2} ||\mathbf{W}||_F^2}_{\text{regularization loss}}~~~~~ (3) \] với \(||\bullet||_F\) là Frobenius norm, và \(\lambda\) là một giá trị dương giúp cân bằng giữa data loss và regularization loss, thường được chọn bằng cross-validation.
2.5. Chọn giá trị \(\Delta\)
Có hai hyperparameter trong hàm mất mát \((3)\) là \(\Delta\) và \(\lambda\), câu hỏi đặt ra là làm thế nào để chọn ra cặp giá trị hợp lý nhất cho từng bài toán. Liệu chúng ta có cần làm cross-validation cho từng giá trị không?
Trong thực tế, người ta nhận thấy rằng \(\Delta\) có thể được chọn bằng 1 mà không ảnh hưởng nhiều tới chất lượng của nghiệm. Thực tế cho thấy cả hai tham số \(\Delta\) và \(\lambda\) đều giúp cân bằng giữa data loss và regularization loss. Thực vậy, độ lớn của các hệ số trong \(\mathbf{W}\) có tác động trực tiếp lên các score vectors, và vì vậy ảnh hưởng tới sự khác nhau giữa chúng. Khi chúng ta giảm các hệ số của \(\mathbf{W}\), sự khác nhau giữa các scores cũng giảm một tỉ lệ tương tự; và khi ta tăng các hệ số của \(\mathbf{W}\), sự khác nhau giữa các scores cũng tăng lên. Bởi vậy, giá trị chính xác \(\Delta\) của margin giữa các scores trở nên không quan trọng vì chúng ta có thể tăng hoặc giảm \(\mathbf{W}\) một cách tùy ý. Việc quan trọng hơn là hạn chế việc \(\mathbf{W}\) trở nên quá lớn. Việc này đã được điều chỉnh bởi tham số \(\lambda\).
Cuối cùng, chúng ta sẽ đi tối ưu hàm mất mát sau đây cho Multi-class SVM:
\[ \mathcal{L}(\mathbf{X}, \mathbf{y}, \mathbf{W}) = \frac{1}{N}\sum_{n=1}^N \sum_{j \neq y_n} \max(0, 1 - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n) + \frac{\lambda}{2} ||\mathbf{W}||_F^2~~~~~ (4) \]
Một lần nữa, chúng ta có thể dùng Gradient Descent để tối ưu bài toán tối ưu không ràng buộc này. Chúng ta sẽ đi sâu vào việc tính đạo hàm của hàm mất mát một cách hiệu quả ở mục 3.
Trước hết, có một nhận xét thú vị:
2.6. Soft Margin SVM là một trường hợp đặc biệt của Multi-class SVM
Phát biểu này có vẻ hiển nhiên vì bài toán phân lớp với hai classes là một trường hợp đặc biệt của bài toán phân lớp với nhiều classes! Nhưng điều tôi muốn nói đến là cách xây dựng hàm mất mát. Điều này có thể được nhận ra bằng cách xét từng điểm dữ liệu.
Trong \((4)\), nếu \(C = 2\) (số classes bằng 2), hàm mất mát tại mỗi điểm dữ liệu trở thành (tạm bỏ qua regularization loss): \[ \mathcal{L}_n = \sum_{j \neq y_n} \max(0, 1 - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n) \] Xét hai trường hợp:
-
\(y_n = 1 \Rightarrow \mathcal{L}_n = \max(0, 1 - \mathbf{w}_1^T\mathbf{x}_n + \mathbf{w}_2^T\mathbf{x}_n) = \max(0, 1 - (1)(\mathbf{w}_1 - \mathbf{w}_2)^T\mathbf{x})\)
-
\(y_n = 2 \Rightarrow \mathcal{L}_n = \max(0, 1 - \mathbf{w}_2^T\mathbf{x}_n + \mathbf{w}_1^T\mathbf{x}_n) = \max(0, 1 - (-1)(\mathbf{w}_1 - \mathbf{w}_2)^T\mathbf{x})\)
Nếu ta thay \(y_n = -1\) cho dữ liệu thuộc class 2, và đặt \(\mathbf{\bar{w}} = \mathbf{w}_1 - \mathbf{w}_2\), hai trường hợp trên có thể được viết gọn thành: \[ \mathcal{L}_n = \max(0, 1 - y_n\mathbf{\bar{w}}^T\mathbf{x}_n) \] tức chính là Hinge loss cho Soft Margin SVM.
3. Tinh toán hàm mất mát và đạo hàm của nó
Để tối ưu hàm mất mát, chúng ta sử dụng phương pháp Stochastic Gradient Method. Điều này có nghĩa là chúng ta cần tính gradient tại mỗi vòng lặp. Đồng thời, loss sau mỗi vòng lặp cũng cần được tính để kiểm tra liệu thuật toán có hoạt động như ý muốn hay không.
Việc tính toán loss và gradient này không những cần phải chính xác mà còn cần được thực hiện càng nhanh càng tốt. Trong khi việc tính loss thường dễ thực hiện, việc tính gradient cần phải được kiểm tra kỹ càng hơn.
Để đảm bảo rằng loss và gradient được tính một cách chính xác và nhanh, chúng ta sẽ làm từng bước một. Bước thứ nhất là đảm bảo rằng các tính toán là chính xác, dù cách tính có rất chậm. Bước thứ hai là phải đảm bảo có cách tính hiệu quả để thuật toán chạy nhanh hơn. Hai bước này cần được thực hiện trên một lượng dữ liệu nhỏ để đảm bảo chúng được tính chính xác trước khi áp dụng thuật toán vào dữ liệu thật, thường có số điểm dữ liệu lớn và mỗi điểm dữ liệu cũng có số chiều lớn.
Hai mục nhỏ tiếp theo sẽ mô tả hai bước đã nêu ở trên.
3.1. Tính hàm mất mát và đạo hàm của nó bằng cách naive
Naive dịch tạm ra tiếng Việt có nghĩa là ngây thơ, hoặc ngây ngô. Trong Machine Learning, từ này cũng hay được sử dụng với ý chỉ sự đơn giản.
Dưới đây là cách tính đơn giản loss và gradient của hàm mất mát trong \((4)\). Chú ý thành phần regularization.
import numpy as np
from random import shuffle
# naive way to calculate loss and grad
def svm_loss_naive(W, X, y, reg):
d, C = W.shape
_, N = X.shape
## naive loss and grad
loss = 0
dW = np.zeros_like(W)
for n in xrange(N):
xn = X[:, n]
score = W.T.dot(xn)
for j in xrange(C):
if j == y[n]:
continue
margin = 1 - score[y[n]] + score[j]
if margin > 0:
loss += margin
dW[:, j] += xn
dW[:, y[n]] -= xn
loss /= N
loss += 0.5*reg*np.sum(W * W) # regularization
dW /= N
dW += reg*W # gradient off regularization
return loss, dW
# random, small data
N, C, d = 10, 3, 5
reg = .1
W = np.random.randn(d, C)
X = np.random.randn(d, N)
y = np.random.randint(C, size = N)
# sanity check
print 'loss without regularization:', svm_loss_naive(W, X, y, 0)[0]
print 'loss with regularization:'svm_loss_naive(W, X, y, .1)[0]
loss without regularization: 4.68441457903
loss with regularization: 6.25136675351
Cách tính với hai vòng for lồng nhau như trên mô tả lại chính xác loss trong \((4)\) nên sai sót, nếu có, ở đây có thể được kiểm tra và sửa lại dễ dàng. Việc kiểm tra ở cuối cho cái nhìn ban đầu về hàm mất mát: dương và không có regularization sẽ có loss tổng cộng nhỏ hơn.
Về cách tính gradient cho phần data loss, mặc dù hàm \(\max\) là convex nhưng nó không có đạo hàm tại mọi nơi. Cụ thể:
\[ \begin{eqnarray} \frac{\partial }{\partial \mathbf{w}_{y_n}}\max(0, 1 - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n) &=& \left\{ \begin{matrix} 0 & \text{if}& 1 - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n < 0 \newline -\mathbf{x}_n & \text{if} &1 - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n > 0 \end{matrix} \right. && ~~~~(5)\newline \frac{\partial }{\partial \mathbf{w}_{j}}\max(0, 1 - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n) &=& \left\{ \begin{matrix} 0 & \text{if}& 1 - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n < 0 \newline \mathbf{x}_n & \text{if} &1 - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n > 0 \end{matrix} \right. && ~~~~(6) \end{eqnarray} \]
Rõ ràng là các đạo hàm này không xác định tại các điểm mà \(1 - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n = 0\). Tuy nhiên, khi thực hành, ta có thể giả sử rằng tại 0, các đạo hàm này cũng bằng 0.
Để kiểm tra lại cách tính đạo hàm như trên dựa vào \((5)\) và \((6)\) có chính xác không, chúng ta sẽ làm một bước quen thuộc là so sánh nó với numerical gradient. Nếu sự sai khác là nhỏ, nhỏ hơn 1e-7 thì ta có thể coi là gradient tính được là chính xác:
f = lambda W: svm_loss_naive(W, X, y, .1)[0]
# for checking if calculated grad is correct
def numerical_grad_general(W, f):
eps = 1e-6
g = np.zeros_like(W)
# flatening variable -> 1d. Then we need
# only one for loop
W_flattened = W.flatten()
g_flattened = np.zeros_like(W_flattened)
for i in xrange(W.size):
W_p = W_flattened.copy()
W_n = W_flattened.copy()
W_p[i] += eps
W_n[i] -= eps
# back to shape of W
W_p = W_p.reshape(W.shape)
W_n = W_n.reshape(W.shape)
g_flattened[i] = (f(W_p) - f(W_n))/(2*eps)
# convert back to original shape
return g_flattened.reshape(W.shape)
# compare two ways of computing gradient
g1 = svm_loss_naive(W, X, y, .1)[1]
g2 = numerical_grad_general(W, f)
print 'gradient difference: %f' %np.linalg.norm(g1 - g2)
# this should be very small
gradient difference: 0.000000
Sự sai khác là xấp xỉ 0, vậy chúng ta có thể yên tâm khi nói rằng cách tính gradient đã thỏa mãn sự chính xác, chúng ta cần tính nó một cách hiệu quả nữa.
Các cách tính hiệu quả thường không chứa các vòng for mà được viết gọn lại dưới dạng ma trận và vector, việc này đòi hỏi các kỹ năng về Đại số tuyến tính và numpy một chút. Cách tính này thường được gọi là vectorized.
3.2. Tính hàm mất mát và đạo hàm của nó bằng cách vectorized
Để giúp các bạn dễ hình dung hơn, tôi đã chuẩn bị Hình dưới đây:

Ở đây, chúng ta tạm quên phần regularization loss đi vì cả loss và gradient của phần này đều có cách tính đơn giản. Với phần data loss, chúng ta cũng bỏ qua hệ số \(\frac{1}{N}\) đi cho dễ hình dung.
Giả sử rằng có 4 classes và mini-batch gồm có 3 điểm dữ liệu \(\mathbf{x}_1, \mathbf{x}_2, \mathbf{x}_3\). 3 điểm này lần lượt thuộc vào các class 1, 3, 2. Các ô có nền màu đỏ nhạt ở mỗi cột tương ứng với correct class của điểm dữ liệu của cột đó. Các bước tính loss và gradient có thể được hình dung như sau:
-
Bước 1: Tính score matrix \(\mathbf{Z} = \mathbf{W}^T\mathbf{X}\).
-
Bước 2: Với mỗi ô, tính \(\max(0, 1 - \mathbf{w}_{y_n}^T \mathbf{x}_n + \mathbf{w}_j^T\mathbf{x}_n)\). Chú ý rằng ta không cần tính các ô có nền màu đỏ nhạt vì có thể coi chúng bằng 0 do trong biểu thức data loss. Sau khi tính được giá trị của từng ô, ta chỉ quan tâm tới các ô có giá trị lớn hơn 0 - là các ô được tô nền màu xanh lục. Lấy tổng của tất cả các phần tử ở các ô xanh lục, ta sẽ được data loss. (Có thể bạn sẽ phải dừng lại một chút để hiểu. Không sao, take your time).
-
Bước 3: Theo công thức \((6)\), với ô màu xanh lục ở hàng 2, cột 1, thì đạo hàm theo vector hệ số \(\mathbf{w}_2\) sẽ được cộng thêm một lượng \(\mathbf{x}_1\) và đạo hàm theo vector hệ số \(\mathbf{w}_1\) sẽ được trừ đi một lượng \(\mathbf{x}_1\). Tương tự với các ô màu xanh lục còn lại. Với các ô màu đỏ ở hàng 1 cột 1, chúng ta chú ý rằng trong cùng cột 1, có bao nhiêu ô màu xanh lục thì có bấy nhiêu lần đạo hàm của \(\mathbf{w}_1\) bị trừ đi một lượng \(\mathbf{x}_1\). Điều này được suy ra từ \((5)\). Từ đó suy ra trong khối ô vuông thứ 3, giá trị của ô màu đỏ sẽ bằng đối số của tổng số lượng các ô màu xanh lục. Vậy nên ô màu đỏ ở hàng 1 cột 1 phải bằng -2.
-
Bước 4: Bây giờ cộng theo các hàng, ta sẽ được đạo hàm theo hệ số của class tương ứng.
Trong đoạn code dưới đây, correct_class_score chính là tập hợp các giá trị trong các ô màu đỏ ở khối thứ nhất.
# more efficient way to compute loss and grad
def svm_loss_vectorized(W, X, y, reg):
d, C = W.shape
_, N = X.shape
loss = 0
dW = np.zeros_like(W)
Z = W.T.dot(X)
correct_class_score = np.choose(y, Z).reshape(N,1).T
margins = np.maximum(0, Z - correct_class_score + 1)
margins[y, np.arange(margins.shape[1])] = 0
loss = np.sum(margins, axis = (0, 1))
loss /= N
loss += 0.5 * reg * np.sum(W * W)
F = (margins > 0).astype(int)
F[y, np.arange(F.shape[1])] = np.sum(-F, axis = 0)
dW = X.dot(F.T)/N + reg*W
return loss, dW
Sau khi đã viết đoạn code mà chúng ta cho rằng đã hiệu quả (không còn vòng for nào) này, chúng ta cần phải kiểm chứng hai điều:
- Quy trình 4 bước tôi nêu ở trên có chính xác không. Việc này được kiểm chứng bằng cách so sánh đạo hàm này với đạo hàm nhận được bằng cách tính naive.
- Cách tính thứ hai này liệu có thực sự hiệu quả, tức có nhanh hơn cách naive nhiều không.
N, C, d = 49000, 10, 3073
reg = .1
W = np.random.randn(d, C)
X = np.random.randn(d, N)
y = np.random.randint(C, size = N)
import time
t1 = time.time()
l1, dW1 = svm_loss_naive(W, X, y, reg)
t2 = time.time()
print 'Naive : run time:', t2 - t1, '(s)'
t1 = time.time()
l2, dW2 = svm_loss_vectorized(W, X, y, reg)
t2 = time.time()
print 'Vectorized: run time:', t2 - t1, '(s)'
print 'loss difference:', np.linalg.norm(l1 - l2)
print 'gradient difference:', np.linalg.norm(dW1 - dW2)
Naive : run time: 34.326472044 (s)
Vectorized: run time: 0.267823934555 (s)
loss difference: 3.63797880709e-12
gradient difference: 2.70855454684e-14
Kết quả nhận được cho chúng ta thấy rằng cách tính bằng vectorized nhanh hơn rất nhiều (khoảng 120 lần) so với cách tính naive. Hơn nữa, sự chênh lệch giữa kết quả của hai cách tính là rất nhỏ, đều nhỏ hơn 1e-10 (tức \(10^{-10})\). Vậy thì chúng ta có thể yên tâm sử dụng cách vectorized này để cập nhật nghiệm.
3.3. Gradient Descent cho Multi-class SVM
Mọi việc giờ thật là đơn giản, giống như mọi phương pháp giải bằng Gradient Descent tôi đã nêu trước đây:
# Mini-batch gradient descent
def multiclass_svm_GD(X, y, Winit, reg, lr=.1, \
batch_size = 100, num_iters = 1000, print_every = 100):
W = Winit
loss_history = np.zeros((num_iters))
for it in xrange(num_iters):
# randomly pick a batch of X
idx = np.random.choice(X.shape[1], batch_size)
X_batch = X[:, idx]
y_batch = y[idx]
loss_history[it], dW = \
svm_loss_vectorized(W, X_batch, y_batch, reg)
W -= lr*dW
if it % print_every == 1:
print 'it %d/%d, loss = %f' \
%(it, num_iters, loss_history[it])
return W, loss_history
N, C, d = 49000, 10, 3073
reg = .1
W = np.random.randn(d, C)
X = np.random.randn(d, N)
y = np.random.randint(C, size = N)
W, loss_history = multiclass_svm_GD(X, y, W, reg)
it 1/1000, loss = 1802.750975
it 101/1000, loss = 251.495825
it 201/1000, loss = 62.021015
it 301/1000, loss = 45.626031
it 401/1000, loss = 38.334262
it 501/1000, loss = 43.666638
it 601/1000, loss = 45.649841
it 701/1000, loss = 35.401936
it 801/1000, loss = 36.211475
it 901/1000, loss = 41.676211
Chúng ta thử visisualize giá trị của loss sau mỗi vòng lặp:
import matplotlib.pyplot as plt
# plot loss as a function of iteration
plt.plot(loss_history)
plt.show()
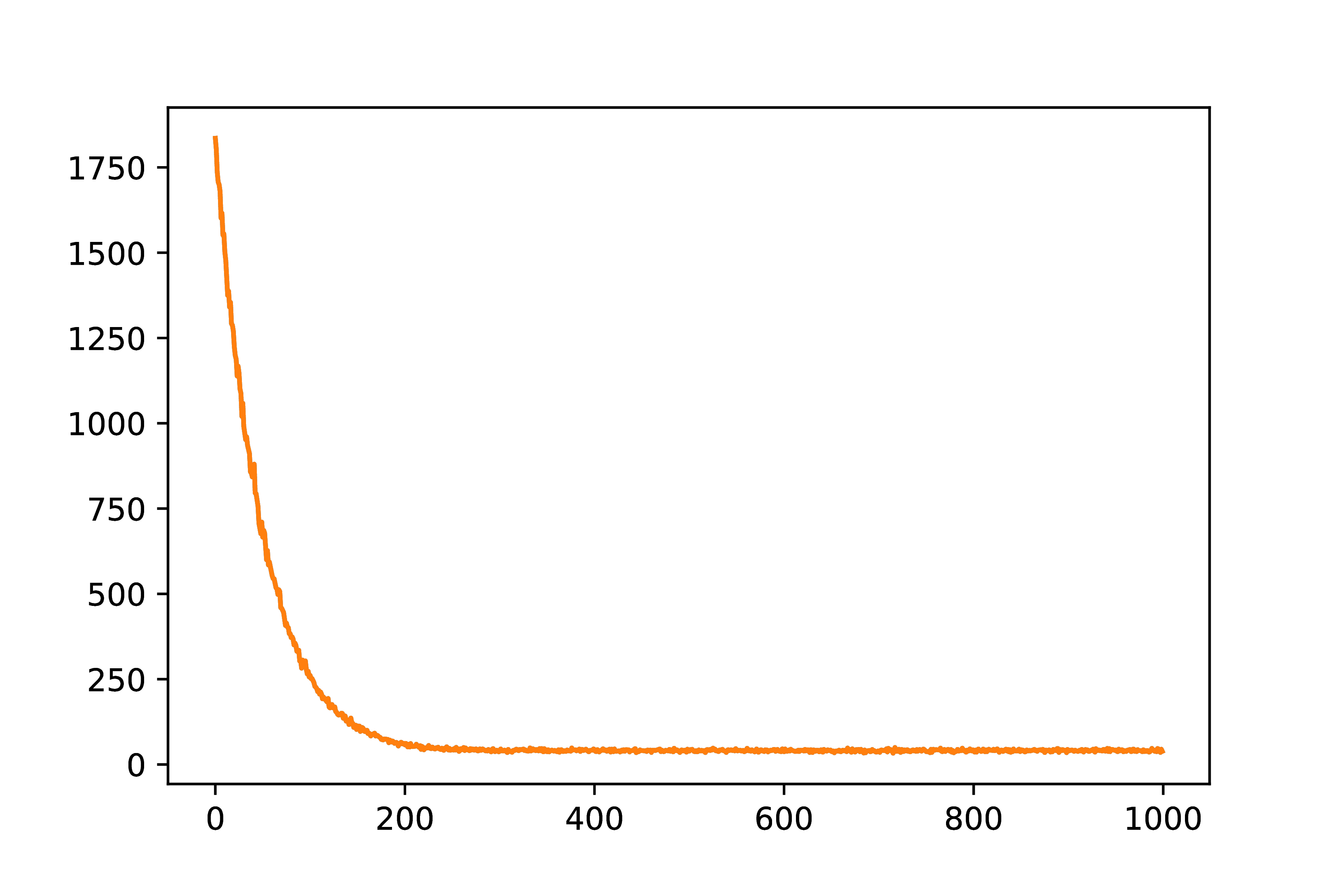
|
Hình 8: Lịch sử loss qua các vòng lặp. Ta thấy rằng loss có xu hướng giảm và hội tụ. |
Từ lịch sử loss này ta thấy rằng giá trị của loss sau mỗi vòng lặp có xu hướng giảm và hội tụ, đây chính là điều mà chúng ta mong muốn.
Phần code còn lại để giải quyết bài toán phân loại cho cơ sở dữ liệu CIFAR-10 có thể tìm thấy trong ipython notebook này
(đây chính là lời giải của tôi cho Assignment #1 của CS231n, WInter 2016, Stanford.)
Kết quả đạt được cho CIFAR-10 là khoảng 40%. Như thế là đã rất tốt với một bài toán khó với 10 classes như thế này, nhất là khi chúng ta chưa phải làm thêm bước feature engineering phức tạp nào. Kết quả của Softmax Regression là khoảng 35%, các bạn cũng có thể tìm thấy tại đây.
Chú ý: Trong các bài tập này, dữ liệu được tính toán theo dạng hàng, tức mỗi hàng của \(\mathbf{X}\) là một điểm dữ liệu. Khi đó, score được tính theo công thức: \(\mathbf{Z} = \mathbf{XW}\). Các phép biến đổi có khác một chút so với trường hợp dữ liệu ở dạng cột. Hy vọng các bạn không gặp khó khăn nhiều.
3.4. Minh họa nghiệm tìm được
Để ý rằng mỗi \(\mathbf{w}_i\) có chiều giống như chiều của dữ liệu, trong trường hợp này, chúng là các bức ảnh. Bằng cách sắp xếp lại các điểm trong mỗi trong 10 vector hệ số tìm được, chúng ta sẽ thu được bức ảnh cũng có kích thước \(3\times 32\times32\) như mỗi ảnh nhỏ trong cơ sở dữ liệu. Dưới đây là hình thù của mỗi \(\mathbf{w}_i\):

Từ đây chúng ta sẽ thấy một điều thú vị.
Hệ số tương ứng với mỗi class đều mang những tính chất giống với các bức ảnh trong class đó, ví dụ như car và truck trông khá giống với các bức ảnh trong class car và truck. Hệ số của ship và plane có mang màu xanh của nước biển và bầu trời. Trong khi horse trông giống như 1 con ngựa 2 đầu; điều này dễ hiểu vì trong tập training, các con ngựa có thể quay đầu về hai phía. Có thể nói theo một cách khác rằng các hệ số tìm được được coi như là các ảnh đại diện cho mỗi class. Vì sao chúng ta có thể nói như vậy?
Nếu chúng ta cùng xem lại cách xác định class cho một dữ liệu mới được thực hiện bằng cách tìm vị trí của giá trị lớn nhất trong score vector \(\mathbf{W}^T\mathbf{x}\), tức:
\[ \text{class}(\mathbf{x}) = \arg\max_{i = 1, 2, \dots, C} \mathbf{w}_i^T\mathbf{x} \]
Nếu bạn để ý chút nữa thì tích vô hướng chính là đại lượng đo sự tương quan giữa hai vector. Đại lượng này càng lớn thì sự tương quan càng cao, tức hai vector càng giống nhau. Như vậy, việc đi tìm class của một bức ảnh mới chính là việc đi tìm xem hệ số tìm được nào gần với bức ảnh đó nhất. Nói thêm một cách khác nữa, đây chính là K-nearest neighbors, nhưng thay vì thực hiện KNN trên toàn bộ training data, chúng ta chỉ thực hiện trên 10 bức ảnh đại diện tìm được bằng Multi-class SVM (hoặc Softmax Regression). Chính vì vậy, hai phương pháp này có thể coi là cách đi tìm mỗi điểm dữ liệu đại diện cho mỗi class!
4. Thảo luận
-
Giống như Softmax Regression, Multi-class SVM vẫn được coi là một bộ phân lớp tuyến tính vì đường phân chia giữa các class là các đường tuyến tính.
-
Kernel SVM cũng hoạt động khá tốt, nhưng việc tính toán ma trận kernel có thể tốn nhiều thời gian và bộ nhớ. Hơn nữa, việc mở rộng nó ra cho bài toán multi-class classification thường không hiệu quả bằng Multi-class SVM. Một ưu điểm nữa của Multi-class SVM là nó có thể được tối ưu bằng (Stochastic) Gradient Descnet, tức là nó phù hợp với các bài toán large-scale. Việc boundary giữa các class là tuyến tính có thể được giải quyết bằng cách kết hợp nó với Deep Neurel Networks. Bạn đọc có thể so sánh hiệu quả của hai phương pháp này bằng cách giải quyết bài toán CIFAR-10 bằng thư viện sklearn như tôi đã trình bày trong bài trước. Tôi đã thử, Kernel cho kết quả thấp và tốn hơn 1 giờ để huấn luyện, so với vài phút của Multi-class SVM. Có thể tôi chưa lựa chọn các tham số hợp lý, nhưng chắc chắn một điều rằng, Kernel SVM tốn nhiều thời gian huấn luyện hơn.
-
Có một cách nữa mở rộng hinge loss cho bài toán multi-class classification là dùng loss: \(\max(0, 1 - \mathbf{w}_{y_n}^T\mathbf{x}_n + \max_{j \neq y_n}\mathbf{w}_{j}^T\mathbf{x}_n)\). Đây chính là vi phạm lớn nhất, so với tổng vi pham mà chúng ta sử dụng trong bài này.
-
Trên thực tế, Multi-class SVM và Softmax Regression có hiệu quả tương đương nhau. Có thể trong một bài toán cụ thể, phương pháp này tốt hơn phương pháp kia, nhưng điều ngược lại xảy ra trong các bài toán khác.
5. Tài liệu tham khảo
[1] CS231n Convolutional Neural Networks for Visual Recognition