
Trong trang này:
- 1. Giới thiệu
- 2. Xây dựng và tối ưu hàm mất mát
- 3. Lập trình Python
- 4. Thảo luận
- 5. Tài liệu tham khảo
1. Giới thiệu
Trong Bài 24, chúng ta đã làm quen với một hướng tiếp cận trong Collaborative Filtering dựa trên hành vi của các users hoặc items lân cận có tên là Neighborhood-based Collaborative Filtering. Trong bài viết này, chúng ta sẽ làm quen với một hướng tiếp cận khác cho Collaborative Filtering dựa trên Matrix Factorization (hoặc Matrix Decomposition), tức Phân tích ma trận thành nhân tử.
Nhắc lại rằng trong Content-based Recommendation Systems, mỗi item được mô tả bằng một vector \(\mathbf{x}\) được gọi là item profile. Trong phương pháp này, ta cần tìm một vector hệ số \(\mathbf{w}\) tương ứng với mỗi user sao cho rating đã biết mà user đó cho item xấp xỉ với: \[ y \approx \mathbf{xw} \]
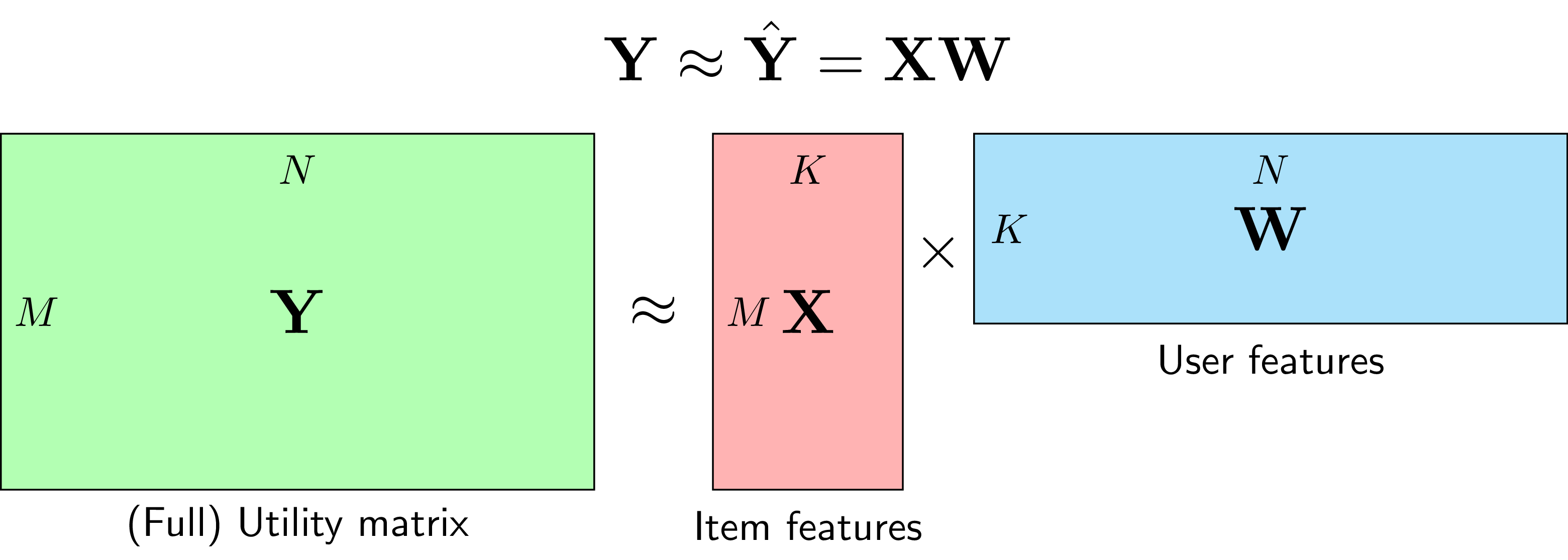
Với cách làm trên, Utility Matrix \(\mathbf{Y}\), giả sử đã được điền hết, sẽ xấp xỉ với:
\[ \mathbf{Y} \approx \left[ \begin{matrix} \mathbf{x}_1\mathbf{w}_1 & \mathbf{x}_1\mathbf{w}_2 & \dots & \mathbf{x}_1 \mathbf{w}_N \newline \mathbf{x}_2\mathbf{w}_1 & \mathbf{x}_2\mathbf{w}_2 & \dots & \mathbf{x}_2 \mathbf{w}_N \newline \dots & \dots & \ddots & \dots \newline \mathbf{x}_M\mathbf{w}_1 & \mathbf{x}_M\mathbf{w}_2 & \dots & \mathbf{x}_M \mathbf{w}_N \newline \end{matrix} \right] = \left[ \begin{matrix} \mathbf{x}_1 \newline \mathbf{x}_2 \newline \dots \newline \mathbf{x}_M \newline \end{matrix} \right] \left[ \begin{matrix} \mathbf{w}_1 & \mathbf{w}_2 & \dots & \mathbf{w}_N \end{matrix} \right] = \mathbf{XW} \]
với \(M, N\) lần lượt l à số items và số users.
Chú ý rằng, \(\mathbf{x}\) được xây dựng dựa trên thông tin mô tả của item và quá trình xây dựng này độc lập với quá trịnh đi tìm hệ số phù hợp cho mỗi user. Như vậy, việc xây dựng item profile đóng vai trò rất quan trọng và có ảnh hưởng trực tiếp lên hiệu năng của mô hình. Thêm nữa, việc xây dựng từng mô hình riêng lẻ cho mỗi user dẫn đến kết quả chưa thực sự tốt vì không khai thác được đặc điểm của những users gần giống nhau.
Bây giờ, giả sử rằng ta không cần xây dựng từ trước các item profile \(\mathbf{x}\) mà vector đặc trưng cho mỗi item này có thể được huấn luyện đồng thời với mô hình của mỗi user (ở đây là 1 vector hệ số). Điều này nghĩa là, biến số trong bài toán tối ưu là cả \(\mathbf{X}\) và \(\mathbf{W}\); trong đó, \(\mathbf{X}\) là ma trận của toàn bộ item profiles, mỗi hàng tương ứng với 1 item, \(\mathbf{W}\) là ma trận của toàn bộ user models, mỗi cột tương ứng với 1 user.
Với cách làm này, chúng ta đang cố gắng xấp xỉ Utility Matrix \(\mathbf{Y} \in \mathbb{R}^{M \times N}\) bằng tích của hai ma trận \(\mathbf{X}\in \mathbb{R}^{M\times K}\) và \(\mathbf{W} \in \mathbb{R}^{K \times N}\).
Thông thường, \(K\) được chọn là một số nhỏ hơn rất nhiều so với \(M, N\). Khi đó, cả hai ma trận \(\mathbf{X}\) và \(\mathbf{W}\) đều có rank không vượt quá \(K\). Chính vì vậy, phương pháp này còn được gọi là Low-Rank Matrix Factorization (xem Hình 1).
Có một vài điểm lưu ý ở đây:
-
Ý tưởng chính đằng sau Matrix Factorization cho Recommendation Systems là tồn tại các latent features (tính chất ẩn) mô tả sự liên quan giữa các items và users. Ví dụ với hệ thống gợi ý các bộ phim, tính chất ẩn có thể là hình sự, chính trị, hành động, hài, …; cũng có thể là một sự kết hợp nào đó của các thể loại này; hoặc cũng có thể là bất cứ điều gì mà chúng ta không thực sự cần đặt tên. Mỗi item sẽ mang tính chất ẩn ở một mức độ nào đó tương ứng với các hệ số trong vector \(\mathbf{x}\) của nó, hệ số càng cao tương ứng với việc mang tính chất đó càng cao. Tương tự, mỗi user cũng sẽ có xu hướng thích những tính chất ẩn nào đó và được mô tả bởi các hệ số trong vector \(\mathbf{w}\) của nó. Hệ số cao tương ứng với việc user thích các bộ phim có tính chất ẩn đó. Giá trị của biểu thức \(\mathbf{xw}\) sẽ cao nếu các thành phần tương ứng của \(\mathbf{x}\) và \(\mathbf{w}\) đều cao. Điều này nghĩa là item mang các tính chất ẩn mà user thích, vậy thì nên gợi ý item này cho user đó.
-
Vậy tại sao Matrix Factorization lại được xếp vào Collaborative Filtering? Câu trả lời đến từ việc đi tối ưu hàm mất mát mà chúng ta sẽ thảo luận ở Mục 2. Về cơ bản, để tìm nghiệm của bài toán tối ưu, ta phải lần lượt đi tìm \(\mathbf{X}\) và \(\mathbf{W}\) khi thành phần còn lại được cố định. Như vậy, mỗi hàng của \(\mathbf{X}\) sẽ phụ thuộc vào toàn bộ các cột của \(\mathbf{W}\). Ngược lại, mỗi cột của \(\mathbf{W}\) lại phục thuộc vào toàn bộ các hàng của \(\mathbf{X}\). Như vậy, có những mỗi quan hệ ràng buộc chằng chịt giữa các thành phần của hai ma trận trên. Tức chúng ta cần sử dụng thông tin của tất cả để suy ra tất cả. Vậy nên phương pháp này cũng được xếp vào Collaborative Filtering.
-
Trong các bài toán thực tế, số lượng items \(M\) và số lượng users \(N\) thường rất lớn. Việc tìm ra các mô hình đơn giản giúp dự đoán ratings cần được thực hiện một cách nhanh nhất có thể. Neighborhood-based Collaborative Filtering không yêu cầu việc learning quá nhiều, nhưng trong quá trình dự đoán (inference), ta cần đi tìm độ similarity của user đang xét với toàn bộ các users còn lại rồi suy ra kết quả. Ngược lại, với Matrix Factorization, việc learning có thể hơi phức tạp một chút vì phải lặp đi lặp lại việc tối ưu một ma trận khi cố định ma trận còn lại, nhưng việc inference đơn giản hơn vì ta chỉ cần lấy tích của hai vector \(\mathbf{xw}\), mỗi vector có độ dài \(K\) là một số nhỏ hơn nhiều so với \(M, N\). Vậy nên quá trình inference không yêu cầu khả năng tính toán cao. Việc này khiến nó phù hợp với các mô hình có tập dữ liệu lớn.
-
Thêm nữa, việc lưu trữ hai ma trận \(\mathbf{X}\) và \(\mathbf{W}\) yêu cầu lượng bộ nhớ nhỏ khi so với việc lưu toàn bộ Similarity matrix trong Neighborhood-based Collaborative Filtering. Cụ thể, ta cần bộ nhớ để chứa \(K(M+N)\) phần tử thay vì lưu \(M^2\) hoặc \(N^2\) của Similarity matrix.
Tiếp theo, chúng ta cùng đi xây dựng hàm mất mát và cách tối ưu nó.
2. Xây dựng và tối ưu hàm mất mát
2.1. Hàm mất mát
Tương tự như trong Content-based Recommendation Systems, việc xây dựng hàm mất mát cũng được dựa trên các thành phần đã được điền của Utility Matrix \(\mathbf{Y}\), có khác một chút là không có thành phần bias và biến tối ưu là cả \(\mathbf{X}\) và \(\mathbf{W}\). Việc thêm bias vào sẽ được thảo luận ở Mục 4. Việc xây dựng hàm mất mát cho Matrix Factorization là tương đối dễ hiểu:
\[ \mathcal{L}(\mathbf{X}, \mathbf{W}) = \frac{1}{2s} \sum_{n=1}^N \sum_{m:r_{mn} = 1} (y_{mn} - \mathbf{x}_m\mathbf{w}_n)^2 + \frac{\lambda}{2} (||\mathbf{X}||_F^2 + ||\mathbf{W}||_F^2) ~~~~~ (1) \]
trong đó \(r_{mn} = 1\) nếu item thứ \(m\) đã được đánh giá bởi user thứ \(n\), \(||\bullet||_F^2\) là Frobineous norm, tức căn bậc hai của tổng bình phương tất cả các phần tử của ma trận (giống với norm 2 trong vector), \(s\) là toàn bộ số ratings đã có. Thành phần thứ nhất chính là trung bình sai số của mô hình. Thành phần thứ hai trong hàm mất mát phía trên là \(l_2\) regularization, giúp tránh overfitting.
Lưu ý: Giá trị ratings thường là các giá trị đã được chuẩn hoá, bằng cách trừ mỗi hàng của Utility Matrix đi trung bình cộng của các giá trị đã biết của hàng đó (item-based) hoặc trừ mỗi cột đi trung bình cộng của các giá trị đã biết trong cột đó (user_based). Trong một số trường hợp nhất định, ta không cần chuẩn hoá ma trận này, nhưng kèm theo đó phải có thêm các kỹ thuật khác để giải quyết vấn đề thiên lệch trong khi rating.
Việc tối ưu đồng thời \(\mathbf{X}, \mathbf{W}\) là tương đối phức tạp, thay vào đó, phương pháp được sử dụng là lần lượt tối ưu một ma trận trong khi cố định ma trận kia, tới khi hội tụ.
2.2. Tối ưu hàm mất mát
Khi cố định \(\mathbf{X}\), việc tối ưu \(\mathbf{W}\) chính là bài toán tối ưu trong Content-based Recommendation Systems:
\[ \mathcal{L}(\mathbf{W}) = \frac{1}{2s} \sum_{n=1}^N \sum_{m:r_{mn} = 1} (y_{mn} - \mathbf{x}_m\mathbf{w}_n)^2 + \frac{\lambda}{2} ||\mathbf{W}||_F^2 ~~~~~ (2) \]
Khi cố định \(\mathbf{W}\), việc tối ưu \(\mathbf{X}\) được đưa về tối ưu hàm:
\[ \mathcal{L}(\mathbf{X}) = \frac{1}{2s} \sum_{n=1}^N \sum_{m:r_{mn} = 1} (y_{mn} - \mathbf{x}_m\mathbf{w}_n)^2 + \frac{\lambda}{2} ||\mathbf{X}||_F^2 ~~~~~ (3) \]
Hai bài toán này sẽ được tối ưu bằng Gradient Descent.
Chúng ta có thể thấy rằng bài toán \((2)\) có thể được tách thành \(N\) bài toán nhỏ, mỗi bài toán ứng với việc đi tối ưu một cột của ma trận \(\mathbf{W}\): \[ \mathcal{L}(\mathbf{w}_n) = \frac{1}{2s} \sum_{m:r_{mn} = 1} (y_{mn} - \mathbf{x}_m\mathbf{w}_n)^2 + \frac{\lambda}{2}||\mathbf{w}_n||_2^2 ~~~~ (4) \]
Vì biểu thức trong dấu \(\sum\) chỉ phụ thuộc vào các items đã được rated bởi user đang xét, ta có thể đơn giản nó bằng cách đặt \(\hat{\mathbf{X}}_n\) là ma trận được tạo bởi các hàng tương ứng với các items đã được rated đó, và \(\hat{\mathbf{y}}_n\) là các ratings tương ứng. Khi đó: \[ \mathcal{L}(\mathbf{w}_n) = \frac{1}{2s} ||\hat{\mathbf{y}}_n - \hat{\mathbf{X}}_n\mathbf{w}_n||^2 + \frac{\lambda}{2}||\mathbf{w}_n||_2^2 ~~~~~(5) \] và đạo hàm của nó: \[ \frac{\partial \mathcal{L}(\mathbf{w}_n)}{\partial \mathbf{w}_n} = -\frac{1}{s}\hat{\mathbf{X}}_n^T(\hat{\mathbf{y}}_n - \hat{\mathbf{X}}_n\mathbf{w}_n) + \lambda \mathbf{w}_n ~~~~~ (6) \]
Vậy công thức cập nhật cho mỗi cột của \(\mathbf{W}\) là: \[ \mathbf{w}_n = \mathbf{w}_n - \eta \left(-\frac{1}{s}\hat{\mathbf{X}}_n^T (\hat{\mathbf{y}}_n - \hat{\mathbf{X}}_n\mathbf{w}_n) + \lambda \mathbf{w}_n\right) ~~~~~(7) \]
Tương tự như thế, mỗi cột của \(\mathbf{X}\), tức vector cho mỗi item, sẽ được tìm bằng cách tối ưu: \[ \begin{eqnarray} \mathcal{L}(\mathbf{x}_m) &=& \frac{1}{2s}\sum_{n:r_{mn} = 1} (y_{mn} - \mathbf{x}_m\mathbf{w}_n)^2 + \frac{\lambda}{2}||\mathbf{x}_m||_2^2 ~~~~ (8) \end{eqnarray} \]
Đặt \(\hat{\mathbf{W}}_m\) là ma trận được tạo bằng các cột của \(\mathbf{W}\) ứng với các users đã đánh giá item đó và \(\hat{\mathbf{y}}^m\) là vector ratings tương ứng. \((8)\) trở thành:
\[ \mathcal{L}(\mathbf{x}_m) = \frac{1}{2s}||\hat{\mathbf{y}}^m - {\mathbf{x}}_m\hat{\mathbf{W}}_m||_2^2 + \frac{\lambda}{2} ||\mathbf{x}_m||_2^2 ~~~~~ (9) \] Tương tự như trên, công thức cập nhật cho mồi hàng của \(\mathbf{X}\) sẽ có dạng: \[ \mathbf{x}_m = \mathbf{x}_m - \eta\left(-\frac{1}{s}(\hat{\mathbf{y}}^m - \mathbf{x}_m\hat{\mathbf{W}}_m)\hat{\mathbf{W}}_m^T + \lambda \mathbf{x}_m\right) ~~~~~ (10) \]
Bạn đọc có thể muốn xem thêm Đạo hàm của hàm nhiều biến
3. Lập trình Python
Tiếp theo, chúng ta sẽ đi sâu vào phần lập trình.
3.1. class MF
Khởi tạo và chuẩn hoá:
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from scipy import sparse
class MF(object):
"""docstring for CF"""
def __init__(self, Y_data, K, lam = 0.1, Xinit = None, Winit = None,
learning_rate = 0.5, max_iter = 1000, print_every = 100, user_based = 1):
self.Y_raw_data = Y_data
self.K = K
# regularization parameter
self.lam = lam
# learning rate for gradient descent
self.learning_rate = learning_rate
# maximum number of iterations
self.max_iter = max_iter
# print results after print_every iterations
self.print_every = print_every
# user-based or item-based
self.user_based = user_based
# number of users, items, and ratings. Remember to add 1 since id starts from 0
self.n_users = int(np.max(Y_data[:, 0])) + 1
self.n_items = int(np.max(Y_data[:, 1])) + 1
self.n_ratings = Y_data.shape[0]
if Xinit is None: # new
self.X = np.random.randn(self.n_items, K)
else: # or from saved data
self.X = Xinit
if Winit is None:
self.W = np.random.randn(K, self.n_users)
else: # from daved data
self.W = Winit
# normalized data, update later in normalized_Y function
self.Y_data_n = self.Y_raw_data.copy()
def normalize_Y(self):
if self.user_based:
user_col = 0
item_col = 1
n_objects = self.n_users
# if we want to normalize based on item, just switch first two columns of data
else: # item bas
user_col = 1
item_col = 0
n_objects = self.n_items
users = self.Y_raw_data[:, user_col]
self.mu = np.zeros((n_objects,))
for n in range(n_objects):
# row indices of rating done by user n
# since indices need to be integers, we need to convert
ids = np.where(users == n)[0].astype(np.int32)
# indices of all ratings associated with user n
item_ids = self.Y_data_n[ids, item_col]
# and the corresponding ratings
ratings = self.Y_data_n[ids, 2]
# take mean
m = np.mean(ratings)
if np.isnan(m):
m = 0 # to avoid empty array and nan value
self.mu[n] = m
# normalize
self.Y_data_n[ids, 2] = ratings - self.mu[n]
Tính giá trị hàm mất mát:
def loss(self):
L = 0
for i in range(self.n_ratings):
# user, item, rating
n, m, rate = int(self.Y_data_n[i, 0]), int(self.Y_data_n[i, 1]), self.Y_data_n[i, 2]
L += 0.5*(rate - self.X[m, :].dot(self.W[:, n]))**2
# take average
L /= self.n_ratings
# regularization, don't ever forget this
L += 0.5*self.lam*(np.linalg.norm(self.X, 'fro') + np.linalg.norm(self.W, 'fro'))
return L
Xác định các items được đánh giá bởi 1 user, và users đã đánh giá 1 item và các ratings tương ứng:
def get_items_rated_by_user(self, user_id):
"""
get all items which are rated by user user_id, and the corresponding ratings
"""
ids = np.where(self.Y_data_n[:,0] == user_id)[0]
item_ids = self.Y_data_n[ids, 1].astype(np.int32) # indices need to be integers
ratings = self.Y_data_n[ids, 2]
return (item_ids, ratings)
def get_users_who_rate_item(self, item_id):
"""
get all users who rated item item_id and get the corresponding ratings
"""
ids = np.where(self.Y_data_n[:,1] == item_id)[0]
user_ids = self.Y_data_n[ids, 0].astype(np.int32)
ratings = self.Y_data_n[ids, 2]
return (user_ids, ratings)
Cập nhật \(\mathbf{X}, \mathbf{W}\):
def updateX(self):
for m in range(self.n_items):
user_ids, ratings = self.get_users_who_rate_item(m)
Wm = self.W[:, user_ids]
# gradient
grad_xm = -(ratings - self.X[m, :].dot(Wm)).dot(Wm.T)/self.n_ratings + \
self.lam*self.X[m, :]
self.X[m, :] -= self.learning_rate*grad_xm.reshape((self.K,))
def updateW(self):
for n in range(self.n_users):
item_ids, ratings = self.get_items_rated_by_user(n)
Xn = self.X[item_ids, :]
# gradient
grad_wn = -Xn.T.dot(ratings - Xn.dot(self.W[:, n]))/self.n_ratings + \
self.lam*self.W[:, n]
self.W[:, n] -= self.learning_rate*grad_wn.reshape((self.K,))
Phần thuật toán chính:
def fit(self):
self.normalize_Y()
for it in range(self.max_iter):
self.updateX()
self.updateW()
if (it + 1) % self.print_every == 0:
rmse_train = self.evaluate_RMSE(self.Y_raw_data)
print 'iter =', it + 1, ', loss =', self.loss(), ', RMSE train =', rmse_train
Dự đoán:
def pred(self, u, i):
"""
predict the rating of user u for item i
if you need the un
"""
u = int(u)
i = int(i)
if self.user_based:
bias = self.mu[u]
else:
bias = self.mu[i]
pred = self.X[i, :].dot(self.W[:, u]) + bias
# truncate if results are out of range [0, 5]
if pred < 0:
return 0
if pred > 5:
return 5
return pred
def pred_for_user(self, user_id):
"""
predict ratings one user give all unrated items
"""
ids = np.where(self.Y_data_n[:, 0] == user_id)[0]
items_rated_by_u = self.Y_data_n[ids, 1].tolist()
y_pred = self.X.dot(self.W[:, user_id]) + self.mu[user_id]
predicted_ratings= []
for i in range(self.n_items):
if i not in items_rated_by_u:
predicted_ratings.append((i, y_pred[i]))
return predicted_ratings
Đánh giá kết quả bằng cách đo Root Mean Square Error:
def evaluate_RMSE(self, rate_test):
n_tests = rate_test.shape[0]
SE = 0 # squared error
for n in range(n_tests):
pred = self.pred(rate_test[n, 0], rate_test[n, 1])
SE += (pred - rate_test[n, 2])**2
RMSE = np.sqrt(SE/n_tests)
return RMSE
3.2. Áp dụng lên MovieLens 100k
Chúng ta cùng quay lại với cơ sở dữ liệu MovieLens 100k
r_cols = ['user_id', 'movie_id', 'rating', 'unix_timestamp']
ratings_base = pd.read_csv('ml-100k/ub.base', sep='\t', names=r_cols, encoding='latin-1')
ratings_test = pd.read_csv('ml-100k/ub.test', sep='\t', names=r_cols, encoding='latin-1')
rate_train = ratings_base.as_matrix()
rate_test = ratings_test.as_matrix()
# indices start from 0
rate_train[:, :2] -= 1
rate_test[:, :2] -= 1
Kết quả nếu sư dụng cách chuẩn hoá dựa trên user:
rs = MF(rate_train, K = 10, lam = .1, print_every = 10,
learning_rate = 0.75, max_iter = 100, user_based = 1)
rs.fit()
# evaluate on test data
RMSE = rs.evaluate_RMSE(rate_test)
print '\nUser-based MF, RMSE =', RMSE
iter = 10 , loss = 5.67288309116 , RMSE train = 1.20479476967
iter = 20 , loss = 2.64823713338 , RMSE train = 1.03727078113
iter = 30 , loss = 1.34749564429 , RMSE train = 1.02937828335
iter = 40 , loss = 0.754769340402 , RMSE train = 1.0291792473
iter = 50 , loss = 0.48310745143 , RMSE train = 1.0292035212
iter = 60 , loss = 0.358530096403 , RMSE train = 1.02921183102
iter = 70 , loss = 0.30139979707 , RMSE train = 1.02921377947
iter = 80 , loss = 0.27520033847 , RMSE train = 1.02921421055
iter = 90 , loss = 0.263185542009 , RMSE train = 1.02921430477
iter = 100 , loss = 0.257675693217 , RMSE train = 1.02921432529
User-based MF, RMSE = 1.06037991127
Ta nhận thấy rằng giá trị loss giảm dần và RMSE train cũng giảm dần khi số vòng lặp tăng lên. RMSE có cao hơn so với Neighborhood-based Collaborative Filtering (~0.99) một chút nhưng vẫn tốt hơn kết quả của Content-based Recommendation Systems rất nhiều (~1.2).
Nếu chuẩn hoá dựa trên item:
rs = MF(rate_train, K = 10, lam = .1, print_every = 10, learning_rate = 0.75, max_iter = 100, user_based = 0)
rs.fit()
# evaluate on test data
RMSE = rs.evaluate_RMSE(rate_test)
print '\nItem-based MF, RMSE =', RMSE
iter = 10 , loss = 5.62978100103 , RMSE train = 1.18231933756
iter = 20 , loss = 2.61820113008 , RMSE train = 1.00601013825
iter = 30 , loss = 1.32429630221 , RMSE train = 0.996672160644
iter = 40 , loss = 0.734890958031 , RMSE train = 0.99621264651
iter = 50 , loss = 0.464793412146 , RMSE train = 0.996184081495
iter = 60 , loss = 0.340943058213 , RMSE train = 0.996181347407
iter = 70 , loss = 0.284148579208 , RMSE train = 0.996180972472
iter = 80 , loss = 0.258103818785 , RMSE train = 0.996180914097
iter = 90 , loss = 0.246160195903 , RMSE train = 0.996180905172
iter = 100 , loss = 0.240683073898 , RMSE train = 0.996180903957
Item-based MF, RMSE = 1.04980475198
Kết quả có tốt hơn một chút.
Chúng ta cùng làm thêm một thí nghiệm nữa khi không sử dụng regularization, tức lam = 0:
rs = MF(rate_train, K = 2, lam = 0, print_every = 10, learning_rate = 1, max_iter = 100, user_based = 0)
rs.fit()
# evaluate on test data
RMSE = rs.evaluate_RMSE(rate_test)
print '\nItem-based MF, RMSE =', RMSE
Nếu các bạn chạy đoạn code trên, các bạn sẽ thấy chất lượng của mô hình giảm đi rõ rệt (RMSE cao).
3.3. Áp dụng lên MovieLens 1M
Tiếp theo, chúng ta cùng đến với một bộ cơ sở dữ liệu lớn hơn là MovieLens 1M bao gồm xấp xỉ 1 triệu ratings của 6000 người dùng lên 4000 bộ phim. Đây là một bộ cơ sở dữ liệu lớn, thời gian training cũng sẽ tăng theo. Bạn đọc cũng có thể thử áp dụng mô hình Neighborhood-based Collaborative Filtering lên cơ sở dữ liệu này để so sánh kết quả. Tôi dự đoán là thời gian training sẽ nhanh nhưng thời gian inference sẽ rất lâu.
Load dữ liệu:
r_cols = ['user_id', 'movie_id', 'rating', 'unix_timestamp']
ratings_base = pd.read_csv('ml-1m/ratings.dat', sep='::', names=r_cols, encoding='latin-1')
ratings = ratings_base.as_matrix()
# indices in Python start from 0
ratings[:, :2] -= 1
Tách tập training và test, sử dụng 1/3 dữ liệu cho test
from sklearn.model_selection import train_test_split
rate_train, rate_test = train_test_split(ratings, test_size=0.33, random_state=42)
print X_train.shape, X_test.shape
(670140, 4) (330069, 4)
Áp dụng Matrix Factorization:
rs = MF(rate_train, K = 2, lam = 0.1, print_every = 2, learning_rate = 2, max_iter = 10, user_based = 0)
rs.fit()
# evaluate on test data
RMSE = rs.evaluate_RMSE(rate_test)
print '\nItem-based MF, RMSE =', RMSE
iter = 2 , loss = 6.80832412832 , RMSE train = 1.12359545594
iter = 4 , loss = 4.35238943299 , RMSE train = 1.00312745587
iter = 6 , loss = 2.85065420416 , RMSE train = 0.978490200028
iter = 8 , loss = 1.90134941041 , RMSE train = 0.974189487594
iter = 10 , loss = 1.29580344305 , RMSE train = 0.973438724579
Item-based MF, RMSE = 0.981631017423
Kết quả khá ấn tượng sau 10 vòng lặp. Kết quả khi áp dụng Neighborhood-based Collaborative Filtering là khoảng 0.92 nhưng thời gian inference khá lớn.
4. Thảo luận
4.1. Khi có bias
Một lợi thế của hướng tiếp cận Matrix Factorization cho Collaborative Filtering là khả năng linh hoạt của nó khi có thêm các điều kiện ràng buộc khác, các điều kiện này có thể liên quan đến quá trình xử lý dữ liệu hoặc đến từng ứng dụng cụ thể.
Giả sử ta chưa chuẩn hoá các giá trị ratings mà sử dụng trực tiếp giá trị ban đầu của chúng trong đẳng thức \((1)\). Việc chuẩn hoá cũng có thể được tích hợp trực tiếp vào trong hàm mất mát. Như tôi đã đề cập, các ratings thực tế đều có những thiên lệch về users hoặc/và items. Có user dễ và khó tính, cũng có những item được rated cao hơn những items khác chỉ vì user thấy các users khác đã đánh giá item đó cao rồi. Vấn đề thiên lệch có thể được giải quyết bằng các biến gọi là biases, phụ thuộc vào mỗi user và item và có thể được tối ưu cùng với \(\mathbf{X}\) và \(\mathbf{W}\). Khi đó, ratings của user \(n\) lên item \(m\) không chỉ được xấp xỉ bằng \(\mathbf{x}_m\mathbf{w}_n\) mà còn phụ thuộc vào các biases của item \(m\) và user \(n\) nữa. Ngoài ra, giá trị này cũng có thể phụ thuộc vào giá trị trung bình của toàn bộ ratings nữa:
\[ y_{mn} \approx \mathbf{x}_m \mathbf{w}_n + b_m + d_n + \mu \]
với \(b_m, d_n, \mu\) lần lượt là bias của item \(m\), user \(n\), và giá trị trung bình của toàn bộ các ratings (là hằng số).
Lúc này, hàm mất mát có thể được thay đổi thành: \[ \begin{eqnarray} \mathcal{L}(\mathbf{X}, \mathbf{W}, \mathbf{b}, \mathbf{d}) &=& \frac{1}{2s} \sum_{n=1}^N \sum_{m:r_{mn} = 1} (\mathbf{x}_m\mathbf{w}_n + b_m + d_n +\mu - y_{mn})^2 + \newline && + \frac{\lambda}{2} (||\mathbf{X}||_F^2 + ||\mathbf{W}||_F^2 + ||\mathbf{b}||_2^2 + ||\mathbf{d}||_2^2) \end{eqnarray} \]
Việc tính toán đạo hàm cho từng biến không quá phức tạp, tôi sẽ không bàn tiếp ở đây. Tuy nhiên, nếu bạn quan tâm, bạn có thể tham khảo source code mà tôi viết tại đây. Link này cũng kèm theo các ví dụ nêu trong Mục 3 và dữ liệu liên quan.
4.2. Nonnegative Matrix Factorization
Khi dữ liệu chưa được chuẩn hoá, chúng đều mang các giá trị không âm. Nếu dải giá trị của ratings có chứa giá trị âm, ta chỉ cần cộng thêm vào Utility Matrix một giá trị hợp lý để có được các ratings là các số không âm. Khi đó, một phương pháp Matrix Factorization khác cũng được sử dụng rất nhiều và mang lại hiệu quả cao trong Recommendation Systems là Nonnegative Matrix Factorization, tức phân tích ma trận thành tích các ma trận có các phần tử không âm.
Bằng Matrix Factorization, các users và items được liên kết với nhau bởi các latent features (tính chất ẩn). Độ liên kết của mỗi user và item tới mỗi latent feature được đo bằng thành phần tương ứng trong feature vector hệ số của chúng, giá trị càng lớn thể hiện việc user hoặc item có liên quan đến latent feature đó càng lớn. Bằng trực giác, sự liên quan của một user hoặc item đến một latent feature nên là một số không âm với giá trị 0 thể hiện việc không liên quan. Hơn nữa, mỗi user và item chỉ liên quan đến một vài latent feature nhất định. Vậy nên feature vectors cho users và items nên là các vectors không âm và có rất nhiều giá trị bằng 0. Những nghiệm này có thể đạt được bằng cách cho thêm ràng buộc không âm vào các thành phần của \(\mathbf{X}\) và \(\mathbf{W}\).
Bạn đọc muốn tìm hiểu thêm về Nonnegative Matrix Factorization có thể tham khảo các tài liệu ở Mục 6.
4.3. Incremental Matrix Factorization
Như đã đề cập, thời gian inference của Recommendation Systems sử dụng Matrix Factorization là rất nhanh nhưng thời gian training là khá lâu với các tập dữ liệu lớn. Thực tế cho thấy, Utility Matrix thay đổi liên tục vì có thêm users, items cũng như các ratings mới hoặc user muốn thay đổi ratings của họ, vì vậy hai ma trận \(\mathbf{X}\) và \(\mathbf{W}\) phải thường xuyên được cập nhật. Điều này đồng nghĩa với việc ta phải tiếp tục thực hiện quá trình training vốn tốn khá nhiều thời gian.
Việc này được giải quyết phần nào bằng Incremental Matrix Factorization. Bạn đọc quan tâm có thể đọc Fast incremental matrix factorization for recommendation with positive-only feedback.
4.4. Others
-
Bài toán Matrix Factorization có nhiều hướng giải quyết khác ngoài Gradient Descent. Bạn đọc có thể xem thêm Alternating Least Square (ALS), Generalized Low Rank Models. Trong bài tiếp theo, tôi sẽ viết về Singular Value Decomposition (SVD), một phương pháp phổ biến trong Matrix Factorization, được sử dụng không những trong (Recommendation) Systems mà còn trong nhiều hệ thống khác. Mời các bạn đón đọc.
6. Tài liệu tham khảo
[1] Recommendation Systems - Stanford InfoLab
[2] Collaborative Filtering - Stanford University
[3] Recommendation systems - Machine Learning - Andrew Ng
[4] Ekstrand, Michael D., John T. Riedl, and Joseph A. Konstan. “Collaborative filtering recommender systems.” Foundations and Trends® in Human–Computer Interaction 4.2 (2011): 81-173.
[5] Matrix factorization techniques for recommender systems
[6] Matrix Factorization For Recommender Systems
[7] Learning from Incomplete Ratings Using Non-negative Matrix Factorization
[8] Fast Incremental Matrix Factorization for Recommendation with Positive-Only Feedback