
Tất cả các bài tập trong bài viết này có thể được thực hiện trực tiếp trên trình duyệt qua trang web FundaML
- 2.0. Mảng nhiều chiều
- 2.1. Khởi tạo một ma trận
- 2.2. Ma trận đơn vị và ma trận đường chéo
- 2.3. Kích thước của ma trận
- 2.4. Truy cập vào từng phần tử của ma trận
- 2.5. Truy cập vào nhiều phần tử của ma trận
- 2.6. np.sum, np.min, np.max, np.mean cho mảng nhiều chiều
- 2.7. Các phép toán tác động đến mọi phần tử của ma trận
- 2.8. Các phép toán giữa hai ma trận I
- 2.9. Chuyện vị ma trận, Reshape ma trận
- 2.10. Các phép toán giữa ma trận và vector
- 2.11. Tích giữa hai ma trận, tích giữa ma trận và vector
- 2.12. Softmax III - Phiên bản tổng quát
2.0. Mảng nhiều chiều
Trong Numpy, người ta thường dùng mảng numpy hai chiều để thể hiện một ma trận. Mảng hai chiều có thể coi là một mảng của các mảng một chiều. Trong đó, mỗi mảng nhỏ một chiều tương ứng với một hàng của ma trận.
Nói cách khác, ma trận có thể được coi là mảng của các vector hàng - mỗi vector hàng được biểu diễn bằng một mảng numpy một chiều.
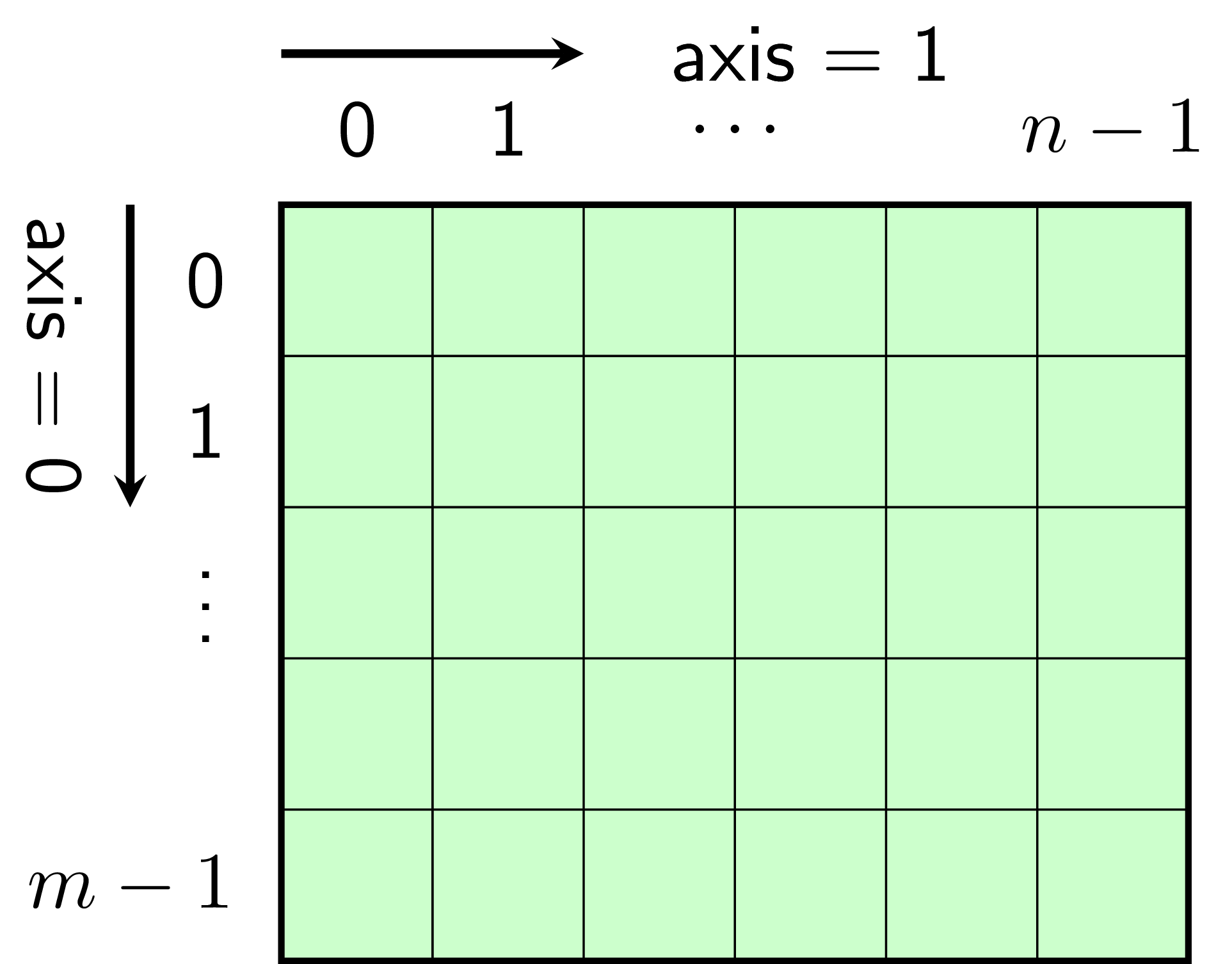
Ví dụ, nếu một mảng numpy hai chiều a mô tả ma trận:
\(\left[
\begin{matrix} 1 & 2 \\ 3 & 4 \end{matrix} \right]
\), khi được in ra nó sẽ có dạng:
array([[1, 2],
[3, 4]])
Ở đây chúng ta có thể nhìn thấy ba mảng, mỗi mảng được thể hiện bằng một cặp
đóng mở ngoặc vuông []:
-
hai mảng
[1, 2]và[3, 4]thể hiện các hàng của ma trận. Chúng là các mảng một chiều. -
mảng
[[1, 2], [3, 4]]có hai phân tử, mỗi phần tử là một hàng của ma trận.
Theo quy ước của Numpy, chúng ta cần đi từ mảng ngoài cùng tới các mảng trong:
-
mảng lớn nhất là
[[1, 2], [3, 4]]được coi là mảng ứng vớiaxis = 0. Trong mảng này, thành phần thứ nhất là[1, 2], thành phần thứ hai là[3, 4]. -
hai mảng lớn thứ hai là
[1, 2]và[3, 4]được coi là các mảng ứng vớiaxis = 1.
(Xem thêm hình vẽ bên.)
Chú ý:
-
Một mảng numpy hoàn toàn có thể có nhiều hơn hai chiều. Khi đó ta vẫn đi từ cặp ngoặc vuông ngoài cùng vào tới trong cùng,
axiscũng đi từ0, 1, ...theo thứ tự đó. -
Mỗi mảng con phải có số phần tử bằng nhau, thể hiện cho việc mỗi hàng của ma trận phải có số chiều như nhau, không có hàng nào thò ra thụt vào.
-
Khi làm việc với các thư viện cho Machine Learning, mỗi điểm dữ liệu thường được coi là một mảng một chiều. Tập hợp các điểm dữ liệu thường được lưu trong một ma trận - tức mảng của các mảng một chiều. Trong ma trận này, mỗi hàng tương ứng với một điểm dữ liệu.
Việc này hơi ngược với cách xây dựng toán học của các thuật toán, nơi mà mỗi điểm dữ liệu thường được coi là một vector cột - tức mỗi cột của ma trận là một điểm dữ liệu. Khi đọc các tài liệu và làm việc với các thư viện, bạn đọc cần chú ý.
Giống như bài “Cơ bản về vector”, trong bài học này, chúng ta sẽ cùng làm quen với các cách xử lý ma trận trong Numpy: Khởi tạo, truy cập, thay đổi, ma trận đặc biệt, …
2.1. Khởi tạo một ma trận
2.1.1. Khởi tạo một ma trận
Cách đơn giản nhất để khởi tạo một ma trận là nhập vào từng phần tử của ma trận đó. Cách làm này, tất nhiên, chỉ phù hợp với các ma trận nhỏ.
>>> import numpy as np
>>> A = np.array([[1, 2], [3, 4]])
>>> A
array([[1, 2],
[3, 4]])
Nếu bạn mới chuyển từ Matlab qua Python, bạn sẽ thấy cách khai báo của Matlab dễ chịu hơn rất nhiều. Chúng ta sẽ phải quen dần thôi :).
Khi khai báo một mảng numpy nói chung, nếu ít nhất một phần tử của mảng là
float, type của mọi phần tử trong mảng sẽ được coi là 'numpy.float64'
(số thực 64 bit).
Ngược lại, nếu toàn bộ các phần tử là số nguyên (không có dấu . xuất hiện),
type của mọi phần tử trong mảng sẽ được coi là 'numpy.int64' (số nguyên 64 bit).
Nếu muốn chỉ định type của các phần tử trong mảng, ta cần đặt giá trị cho dtype.
Ví dụ:
>>> B = np.array([[1, 2, 3], [4, 5, 6]], dtype = np.float)
>>> type(B[0][0])
<type 'numpy.float64'>
Bài tập:
Khai báo một mảng numpy hai chiều A mô tả ma trận:
\[\mathbf{A} = \left[ \begin{matrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{matrix} \right] \]
2.2. Ma trận đơn vị và ma trận đường chéo
2.2.1. Ma trận đơn vị
Để tạo một ma trận đơn vị có số chiều bằng n (ma trận đơn vị là một ma trận vuông có tất cả các phần tử trên đường chéo bằng 1), chúng ta sử dụng hàm np.eye():
>>> import numpy as np
>>> np.eye(3)
array([[ 1., 0., 0.],
[ 0., 1., 0.],
[ 0., 0., 1.]])
Hàm np.eye() cũng được dùng để tạo các ma trận toàn 1 ở một đường chéo phụ nào đó, các thành phần còn lại bằng 0. Ví dụ:
>>> np.eye(3, k = 1)
array([[ 0., 1., 0.],
[ 0., 0., 1.],
[ 0., 0., 0.]])
>>> np.eye(4, k= -2)
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 1., 0., 0., 0.],
[ 0., 1., 0., 0.]])
k = 1 sẽ tương ứng với đường chéo phụ ngay trên đường chéo chíh. k = -2 sẽ tương ứng với đường chéo phụ thứ hai bên dưới đường chéo chính.
Bạn đọc có thể đọc thêm về cách sử dụng hàm ‘np.eye()’ tại đây.
Xin nhắc lại rằng bạn đọc luôn có thể xem cách sử dụng một hàm trên terminal bằng cách gõ help(func) trong đó func là tên hàm bạn muốn tra cứu. Ví dụ, help(np.eye).
2.2.2. Ma trận đường chéo
Để khai báo một ma trận đường chéo, hoặc muốn trích xuất đường chéo của một ma trận, ta dùng hàm np.diag.
>>> np.diag([1, 3, 4])
array([[1, 0, 0],
[0, 3, 0],
[0, 0, 4]])
>>> np.diag(np.diag([1, 3, 4]))
array([1, 3, 4])
-
Nếu đầu vào là một mảng một chiều, trả về một mảng hai chiều thể hiện ma trận có đường chéo là các phần tử thuộc mảng đó.
-
Nếu đầu vào là một mảng hai chiều (có thể không vuông), trả về mảng một chiều chứa các giá trị ở hàng thứ
i, cột thứivới0 <= i <= min(m, n). Trong đóm,nlần lượt là số hàng và số cột của ma trận được biểu diễn bằng mảng hai chiều ban đầu.
Đường chéo phụ của một ma trận cũng có thể được lấy bằng cách sử dụng hàm này và chỉ ra giá trị của k:
>>> a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
>>> a
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> np.diag(a, k = 1)
array([2, 6])
Bài tập:
Với một số tự nhiên n, hãy viết hàm trả về ma trận có dạng:
\[
\left[
\begin{matrix}
0 & 0 & 0 & 0 & \dots & 0 & 0 \\ 1 & 0 & 0 & 0 & \dots & 0 & 0 \\ 0 & 2 & 0 & 0 & \dots & 0 & 0 \\ \dots & \dots & \dots & \dots & \ddots & \dots \\ 0 & 0 & 0 & 0 & \dots & 0 & 0 \\ 0 & 0 & 0 & 0 & \dots & n & 0
\end{matrix}
\right]
\]
tức đường chéo phụ ngay dưới đường chéo chính nhận các giá trị từ 1 đến \(n\). Các thành phần là kiểu số nguyên.
2.3. Kích thước của ma trận
Giống như cách tìm kích thước của mảng một chiểu, để tìm kích thước của mảng hai chiều, ta cũng sử dụng thuộc tính shape:
>>> import numpy as np
>>> A = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
>>> A
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
>>> A.shape
(3, 4)
Ở đây, kết quả trả về là một tuple. Số phần tử của tuple này chính là số
chiều của mảng. Nếu coi mảng hai chiều như ma trận, số hàng và số cột của ma
trận có thể được tính bằng:
>>> A.shape[0]
3
>>> A.shape[1]
4
Với mảng numpy nhiều chiều, ta cũng dùng thuộc tính shape để tìm kích thước
của mỗi chiều.
2.4. Truy cập vào từng phần tử của ma trận
2.4.1. Truy cập vào từng phần tử
Có hai cách để truy cập vào mỗi phần tử của mảng hai chiều:
2.4.1.1. Cách 1: giống với list
Để truy cập vào phần tử ở hàng thứ i, cột thứ j của ma trận (chỉ số bắt đầu
từ 0), ta có thể coi phần tử đó là phần tử thứ j của mảng i trong mảng hai
chiều ban đầu.
Ví dụ:
>>> import numpy as np
>>> A = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
>>> A[1][2]
6
ở đây A[1] chính lả mảng một chiều [4, 5, 6], trong mảng này, ta lấy phần
tử có chỉ số là 2, phần tử đó có giá trị là 6. Vậy A[1][2] = 6.
2.4.1.2. Cách 2: giống như Matlab
Trong Matlab, để truy cập vào phần tử ở hàng đầu tiên, cột đầu tiên của một ma
trận A, ta sử dụng A(1, 1). Trong Numpy, có một chút thay đổi:
- Chỉ số bắt đầu từ 0.
- Bộ chỉ số được đặt trong dấu ngoặc vuông
[].
Ví dụ
>>> A[2, 1]
8
2.4.2. Truy cập vào hàng/cột
Để truy cập vào hàng có chỉ số i của một ma trận A, ta chỉ cần dùng A[i]
hoặc A[i,:] hoặc A[i][:]:
>>> A[2]
array([7, 8, 9])
>>> A[0,:]
array([1, 2, 3])
Để truy cập vào cột có chỉ số j, ta dùng A[:,j]:
>>> A[:, 1]
array([2, 5, 8])
Chú ý:
-
Trong Numpy, kết quả trả về của một cột hay hàng đều là một mảng một chiều, không phải là một vector cột như trong Matlab. Tuy nhiên, khi lấy một ma trận nhân với nó, nó vẫn được coi là một vector cột. Thông tin chi tiết sẽ có trong các bài sau.
-
Nếu sử dụng
A[:][1], kết quả trả về là hàng có chỉ số1chứ không phải cột có chỉ số1. Trong trường hợp này,A[:]vẫn được hiểu là cả ma trậnA, vì vậy nênA[:][1]tương đương vớiA[1]. -
Có sự khác nhau căn bản giữa
AvàA[:], chúng ta sẽ quay lại trong một bài nào đó ở sau.
Bài tập:
Cho một ma trận A, viết hàm myfunc tính tổng các phần tử trên các cột
có chỉ số chẵn (0, 2, 4, ...) của ma trận đó.
Ví dụ:
>>> A = np.array([[1, 2], [3, 4]])
>>> myfunc(A)
4
Giải thích: cột có chỉ số 0 của ma trận là mảng [1, 3], tổng các phần tử
của mảng này là 4.
2.5. Truy cập vào nhiều phần tử của ma trận
2.5.1. Nhiều phần tử trong cùng một hàng
Việc truy cập vào nhiều phần tử trong một hàng tương tự như với mảng một chiều:
>>> import numpy as np
>>> A = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
>>> A
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
>>> A[0, 2:]
array([3, 4])
>>> A[1, range(0, A.shape[1], 2)]
array([5, 7])
trong đó, range(0, A.shape[1], 2) tạo ra một list các phần tử là cấp số cộng với công sai là 2,
bắt đầu từ 0 và kết thúc tại số lớn nhất có thể không vượt quá số cột của A. Số cột của A chính là A.shape[1].
2.5.2. Nhiều phần tử trong cùng một cột
Tương tự với nhiều phần tử trong cùng một cột:
>>> A[[0, 2], -1] # the first and the third elements in the last column
array([ 4, 12])
2.5.3. Nhiều hàng, nhiều cột
Nếu muốn trích một ma trận con từ ma trận ban đầu, giả sử lấy ma trận được
tạo bởi hàng có chỉ số 1 và 2, cột có chỉ số 0 và 3, ta làm như sau:
>>> A[[1, 2]][:, [0,3]]
array([[ 5, 8],
[ 9, 12]])
Chú ý: Một cách tự nhiên, bạn đọc có thể suy ra rằng câu lệnh nên là A[[1,
2], [0, 3]] (giống như cách làm trong Matlab). Tuy nhiên, câu lệnh này sẽ cho
ra một kết quả khác (xem mục 4).
A[[1, 2]][:, [0,3]] có thể hiểu được là: đầu tiên lấy hai hàng có chỉ số 1
và 2 bằng A[[1, 2]], ta được một ma trận, sau đó lấy hai cột có chỉ số 0
và 3 của ma trận mới này.
2.5.4. Cặp các toạ độ
Xét câu lệnh:
>>> A[[1, 2], [0, 3]]
array([ 5, 12])
Câu lệnh này sẽ trả về một mảng một chiều gồm các phần tử: A[1][0] và A[2][3]
, tức [1, 2] và [0, 3] là list các toạ độ theo mỗi chiều. Hai list này
phải có độ dài bằng nhau hoặc một list có độ dài bằng 1.
Khi một list có độ dài bằng 1, nó sẽ được cặp với mọi phần tử của list
còn lại. Ví dụ:
>>> A[[1, 2], [0]] # equivalent to A[[1, 2], [0, 0]]
array([5, 9])
Bài tập:
Viết hàm myfunc tính tổng tất cả các phần tử có cả hai chỉ số đều chẵn của
một ma trận A bất kỳ. Ví dụ:
>>> A
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
>>> myfunc(A) # = 1 + 3 + 9 + 11
24
Gợi ý: bạn đọc tìm đọc trước cách sử dụng np.sum cho mảng nhiều chiều.
2.6. np.sum, np.min, np.max, np.mean cho mảng nhiều chiều
Xin nhắc lại về cách quy ước axis của ma trận. axis = 0 là tính theo chiều
từ trên xuống dưới, nghĩa là phương của nó cùng với phương của các cột. Tương
tự axis = 1 sẽ có phương cùng với phương của các hàng. Hãy quan sát hình dưới
đây và ghi nhớ cách quy ước quan trọng này.
Xét một ma trận:
>>> import numpy as np
>>> A = np.array([[1., 2, 3, 2], [4, 3, 7, 4], [1, 4, 2, 3]])
>>> A
array([[ 1., 2., 3., 2.],
[ 4., 3., 7., 4.],
[ 1., 4., 2., 3.]])
Và các hàm np.sum(), np.min(), np.max(), np.mean() tác động lên A theo axis = 0 (tức các cột của A), kết quả sẽ là:
>>> np.sum(A, axis = 0)
array([ 6., 9., 12., 9.])
>>> np.min(A, axis = 0)
array([ 1., 2., 2., 2.])
>>> np.max(A, axis = 0)
array([ 4., 4., 7., 4.])
>>> np.mean(A, axis = 0)
array([ 2., 3., 4., 3.])
Các giá trị theo các hàm trê lần lượt là tổng, giá trị nhỏ nhất, giá trị lớn nhất, trung bình theo mỗi cột. Kết quả trả về là các mảng một chiều có số phần tử bằng số cột của A.
Tương tự như thế khi thay axis = 1:
>>> np.sum(A, axis = 1)
array([ 8., 18., 10.])
>>> np.min(A, axis = 1)
array([ 1., 3., 1.])
>>> np.max(A, axis = 1)
array([ 3., 7., 4.])
>>> np.mean(A, axis = 1)
array([ 2. , 4.5, 2.5])
Kết quả trả về được tính theo hàng. Kết quả trả về cũng là các mảng một chiều có số phần tử bằng với số hàng của A.
Khi không đề cập tới axis, kết quả được tính trên toàn bộ ma trận:
>>> np.sum(A)
36.0
>>> np.min(A)
1.0
>>> np.max(A)
7.0
>>> np.mean(A)
3.0
keepdims = True
Đôi khi, để thuận tiện cho việc tính toán về sau, chúng ta muốn kết quả trả về khi axis = 0 là các vector hàng thực sự, khi axis = 1 là các vector cột thực sự.
Để làm được việc đó, Numpy cung cấp thuộc tính keepdims = True (mặc định là False). Khi keepdims = True, nếu sử dụng axis = 0, kết quả sẽ là một mảng hai chiều có chiều thứ nhất bằng 1 (coi như ma trận một hàng).
Tương tự, nếu sử dụng axis = 1, kết quả sẽ là một mảng hai chiều có chiều thứ hai bằng 1 (một ma trận có số cột bằng 1). Việc này, về sau chúng ta sẽ thấy, quan trọng trong nhiều trường hợp đặc biệt:
>>> np.sum(A, axis = 0, keepdims = True)
array([[ 6., 9., 12., 9.]])
>>> np.mean(A, axis = 1, keepdims = True)
array([[ 2. ],
[ 4.5],
[ 2.5]])
Bài tập:
Cho một ma trận A bất kỳ. Trong mỗi hàng, ta định nghĩa độ biến động của nó
là sự khác nhau giữa giá trị lớn nhất và nhỏ nhất của các phần tử trong hàng
đó. Hãy viết hàm myfunc trả về tổng độ biến động của tất cả các hàng trong
ma trận đó.
Ví dụ với ma trận A trong bài học, độ biến động của mỗi hàng lần lượt là
2.0, 4.0, 3.0. Vậy myfunc(A) = 9.0.
2.7. Các phép toán tác động đến mọi phần tử của ma trận
2.7.1. Tính toán giữa một mảng hai chiều và một số vô hướng
Khi tính toán giữa một số vô hướng và một mảng hai chiều, ví dụ:
>>> import numpy as np
>>> A = np.array([[1, 3], [2, 5]])
>>> A
array([[1, 3],
[2, 5]])
>>> A + 2
array([[3, 5],
[4, 7]])
>>> A*2
array([[ 2, 6],
[ 4, 10]])
>>> 2**A
array([[ 2, 8],
[ 4, 32]])
Ta nhận thấy rằng từng phần tử của mảng sẽ được kết hợp với số vô hướng bằng các phép toán tương ứng để tạo ra một mảng mới cùng kích thước. Việc này, như cũng đã trình bày trong khi làm việc với mảng một chiều, đúng với các mảng numpy với số chiều bất kỳ.
2.7.2. np.abs, np.sin, np.exp, …
Bạn đọc cũng có thể dự đoán được rằng các hàm số này cũng tác động lên từng phần tử của mảng và trả về một mảng cùng kích thước với mảng ban đầu.
>>> A = np.random.randn(2, 3) # create a random numpy array with shape = (2, 3)
>>> A
array([[ 0.66079861, 2.11481663, -1.42221111],
[-1.13931439, -0.31866767, -0.37294795]])
>>> np.abs(A)
array([[ 0.66079861, 2.11481663, 1.42221111],
[ 1.13931439, 0.31866767, 0.37294795]])
Bài tập: Frobenious norm
Frobenius norm của một ma trận được định nghĩa là căn bậc hai của tổng bình phương các phần tử của ma trận. Frobenius norm được sử dụng rất nhiều trong các thuật toán Machine Learning vì các tính chất toán học đẹp của nó, trong đó quan trọng nhất là việc đạo hàm của bình phương của nó rất đơn giản. Frobenius norm của một ma trận \(\mathbf{A}\) được ký hiệu là \(||\mathbf{A}||_F\)
Numpy có sẵn hàm tính toán norm này, tuy nhiên, chúng ta nên học cách tự tính
nó trước.
Viết hàm norm_fro(A) tính Frobenius norm của một ma trận bất kỳ.
Ví dụ:
>>> A = np.array([[1, 3], [2, 5]])
>>> A
array([[1, 3],
[2, 5]])
thì norm_fro(A) = 6.2449979983983983 \(= \sqrt{1^2 + 3^2 + 2^2 + 5^2}\).
Gợi ý: Sử dụng hàm np.sqrt.
2.8. Các phép toán giữa hai ma trận I
Các phép toán cộng, trừ, nhân, chia, luỹ thừa (+, -, *, /, **) giữa hai mảng
cùng kích thước cũng được thực hiện dựa trên từng cặp phần tử. Kết quả trả
về là một mảng cùng chiều với hai mảng đã cho:
>>> import numpy as np
>>> A = np.array([[1., 5], [2, 3]])
>>> B = np.array([[5., 8], [7, 3]])
>>> A*B
array([[ 5., 40.],
[ 14., 9.]])
>>> A**B
array([[ 1.00000000e+00, 3.90625000e+05],
[ 1.28000000e+02, 2.70000000e+01]])
Chú ý: tích của hai ma trận như định nghĩa trong Đại số tuyến tính được thực hiện dựa trên hàm số khác. Cách viết A*B được thực hiện trên từng cặp phần tử của A và B
Bài tập:
Trong khi làm việc với Machine Learning, chúng ta thường xuyên phải so sánh hai ma trận. Xem xem liệu chúng có gần giống nhau không. Một cách phổ biến để làm việc này là tính bình phương của Frobineous norm của hiệu hai ma trận đó. Cụ thể, để xem ma trận \(\mathbf{A}\) có gần ma trận \(\mathbf{B}\) hay không, người ta thường tính \(||\mathbf{A} - \mathbf{B}||_F^2\).
Cho hai mảng hai chiều có cùng kích thước A và B. Viết hàm dist_fro tính bình phương Frobenious norm của hiệu hai ma trận được mô tả bởi hai mảng đó.
2.9. Chuyện vị ma trận, Reshape ma trận
2.9.1 Chuyển vị ma trận
Có hai cách để lấy chuyển vị của một ma trận: dùng thuộc tính .T hoặc dùng hàm np.transpose:
>>> import numpy as np
>>> A = np.array([[1, 2, 3],[4, 5, 6]])
>>> A
array([[1, 2, 3],
[4, 5, 6]])
>>> A.T
array([[1, 4],
[2, 5],
[3, 6]])
>>> np.transpose(A)
array([[1, 4],
[2, 5],
[3, 6]])
2.9.2. Reshape
Khi làm việc với ma trận, chúng ta sẽ phải thường xuyên làm việc với các phép biến đổi kích thước của ma trận. Phép biến đổi kích thước có thể coi là việc sắp xếp lại các phần tử của một ma trận vào một ma trận khác có tổng số phần tử như nhau.
Trong numpy, để làm được việc này chúng ta dùng phương thức .reshape hoặc hàm np.reshape. Cùng xem ví dụ:
>>> np.reshape(A, (3, 2))
array([[1, 2],
[3, 4],
[5, 6]])
>>> A.reshape(3, 2)
array([[1, 2],
[3, 4],
[5, 6]])
Số chiều của mảng mới không nhất thiết phải bằng 2, nó có thể bằng bất kỳ giá trị nào (lớn hơn hoặc bằng 1) nhưng phải đảm bảo tổng số phần tử của hai mảng là như nhau. Khi biến thành mảng
một chiều, ta không dùng tuple (như (3,2)) nữa mà chỉ dùng một số tự nhiên:
>>> np.reshape(A, 6) # to a 1d numpy array
array([1, 2, 3, 4, 5, 6])
>>> A.reshape(3, 1, 2) # to a 3d numpy array
array([[[1, 2]],
[[3, 4]],
[[5, 6]]])
Ta có thể nhận thấy rằng nếu biến thành một mảng hai chiều mới, ta không nhất thiết phải biết kích thước của mỗi chiều mà chỉ cần kích thước của một chiều. Kích thước còn lại được suy ra
từ việc tổng số phần tử của hai mảng là như nhau. Tương tự, nếu biến thành một mảng ba chiều mới, ta chỉ cần biết hai trong ba kích thước. Kích thước còn lại sẽ được python tự tính ra, và ta
chỉ cần gán nó bằng -1:
>>> A.reshape(-1) # to 1d array, its size must be 6
array([1, 2, 3, 4, 5, 6])
>>> np.reshape(A, (6, -1)) # ~ a 2d array of shape 6x1
array([[1],
[2],
[3],
[4],
[5],
[6]])
2.9.3. Thứ tự của phép toán reshape
Có một điểm quan trọng cần nhớ là thứ tự của phép toán reshape: các phần tử trong mảng mới được sắp xếp như thế nào. Có hai cách sắp xếp chúng ta cần lưu ý: mặc định là 'C'-order, và một cách khác là 'F'-order (xem hình).

Trong 'C'-order, các thành phần của mảng nguồn được quét từ axis trong ra ngoài (axis = 1 rồi mới tới axis = 0 trong mảng hai chiều, tức từng hàng một), sau đó chúng được xếp vào mảng đích cũng theo thứ tự đó.
Trong 'F'-oder (Fortran) các thành phần của mảng nguồn được quét từ axis ngoài vào trong (trong mảng hai chiều là từng cột một), sau đó chúng được sắp xếp vào mảng đích cũng theo thứ tự đó - từng cột một.
>>> A
array([[1, 2, 3],
[4, 5, 6]])
>>> A.reshape(3, -1, order = 'F')
array([[1, 5],
[4, 3],
[2, 6]])
>>>
(Đọc thêm numpy.reshape.)
Bài tập:
Hãy tạo ma trận A sau một cách nhanh nhất, không dùng cách thủ công ghi từng phần tử ra.
\[ \left[ \begin{matrix} 1 &5&9&2\\6&10&3&7 \\11&4&8&12 \end{matrix} \right] \] Gợi ý:
- sử dụng
np.arange() - Để ý vị trí của 9, 10, 11 và 2, 3, 4
- Lời giải không quá hai dòng
Bạn có thể nhận được phản hồi ‘Kết quả thành công’ nhưng hãy thử cố nghĩ quy luật của ma trận này rồi dùng các phép transpose, reshape thích hợp.
2.10. Các phép toán giữa ma trận và vector
Chúng ta đã qua các bài về phép toán giữa một mảng hai chiều và một số vô hướng, giữa hai mảng hai chiều cùng kích thước. Trong bài này, chúng ta cùng làm quen với các phép toán giữa một mảng hai chiều và một mảng một chiều. Trước tiên, hãy thử vài ví dụ:
>>> import numpy as np
>>> A = np.arange(12).reshape(3, -1)
>>> A
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> b = np.array([1., 2, 3, 5])
>>> A + b
array([[ 1., 3., 5., 8.],
[ 5., 7., 9., 12.],
[ 9., 11., 13., 16.]])
>>> A*b
array([[ 0., 2., 6., 15.],
[ 4., 10., 18., 35.],
[ 8., 18., 30., 55.]])
Nhận thấy rằng kết quả của phép toán A + b thu được bằng cách lấy từng hàng của A cộng với b. Kết quả của A*b thu được bằng cách lấy tích của từng hàng của A và b - tích ở đây là tích theo từng phần tử
của hai mảng một chiều, không phải tích vô hướng của hai vector. Nói cách khác, kết quả của A*b thu được bằng cách lấy từng cột của A nhân với phần tử tương ứng của b. Quy luật tương tự xảy ra
với cả phép -, / và **:
>>> c = np.array([1, 2, 1,2])
>>> A**c
array([[ 0, 1, 2, 9],
[ 4, 25, 6, 49],
[ 8, 81, 10, 121]])
Bài tập
Giả sử tập dữ liệu bao gồm nhiều điểm dữ liệu có cùng chiều, được sắp xếp thành một mảng hai chiều mô tả một ma trận - được gọi là ma trận dữ liệu. Mỗi hàng của ma trận này là một điểm dữ liệu. Một trong các kỹ thuật quan trọng trước khi áp dụng các thuật toán Machine Learning lên dữ liệu là chuẩn hoá dữ liệu. Trong các phương pháp chuẩn hoá dữ liệu, một phương pháp thường được sử dụng là đưa dữ liệu về dạng zero-mean, tức trung bình cộng của toàn bộ dữ liệu là một vector có toàn bộ các thành phần bằng 0.
Cách chuẩn hoá này có thể được thực hiện bằng cách trước tiên tính vector trung bình của toàn bộ dữ liệu (ở đây là vector trung bình của toàn bộ các hàng), sau đó lấy từng điểm dữ liệu trừ đi vector trung bình. Khi đó, ma trận mới sẽ có trung bình cộng các hàng bằng vector 0, và ta nói rằng ma trận dữ liệu mới này là zero-mean.
Cho một mảng hai chiều X mô tả dữ liệu, trong đó X[i] là một mảng một chiều mô tả dữ liệu có chỉ số i. Hãy viết hàm zero_mean trả về ma trận dữ liệu đã chuẩn hoá theo zero-mean.
2.11. Tích giữa hai ma trận, tích giữa ma trận và vector
2.11.1. Tích giữa hai ma trận
Trong Đại Số Tuyến Tính (ĐSTT), tích của hai ma trận \(\mathbf{A} \in \mathbb{R}^{m\times n}\) và \(\mathbf{B} \in \mathbb{R}^{n \times p}\) được ký hiệu là \(\mathbf{C = AB} \in \mathbb{R}^{m \times p}\) trong đó phần tử ở hàng thứ \(i\) cột thứ \(j\) (tính từ \(0\)) của \(\mathbf{C}\) được tính theo công thức: \[ c_{ij} = \sum_{k=0}^{n-1}a_{ik}b_{kj} \]
Chú ý rằng để phép nhân thực hiện được, số cột của ma trận thứ nhất phải bằng với số hàng của ma trận thứ hai (ở đây đều bằng \(n\)). Và phép nhân ma trận không có tính chất giao hoán, nhưng có tính chất kết hợp, tức: \[ \mathbf{ABC} = \mathbf{(AB)C} = \mathbf{A}(\mathbf{BC}) \]
Trong numpy, ký hiệu * không thực sự để chỉ tích hai ma trận theo nghĩa này mà là tích theo từng cặp phần tử (element-wise). Phép toán * trong numpy yêu cầu hai mảng phải có cùng kích thước, và phép toán này có tính chất giao hoán vì phép nhân
của hai số vô hướng có tính chất giao hoán.
Cho hai mảng numpy hai chiều A, B trong đó A.shape[1] == B.shape[0] (đừng quên điều kiện này). Nếu hai mảng này mô tả hai ma trận thì tích của hai ma trận (theo ĐSTT) có thể được thực hiện bằng thuộc tính
.dot hoặc hàm np.dot:
>>> import numpy as np
>>> A = np.arange(12).reshape(4, 3)
>>> A
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
>>> B = np.arange(-5, 7).reshape(3,-1)
>>> B
array([[-5, -4, -3, -2],
[-1, 0, 1, 2],
[ 3, 4, 5, 6]])
>>> A.dot(B)
array([[ 5, 8, 11, 14],
[ -4, 8, 20, 32],
[-13, 8, 29, 50],
[-22, 8, 38, 68]])
>>> np.dot(A, B)
array([[ 5, 8, 11, 14],
[ -4, 8, 20, 32],
[-13, 8, 29, 50],
[-22, 8, 38, 68]])
2.11.2. Tích giữa một ma trận và một vector
Trong ĐSTT, tích giữa một ma trận và một vector cột được coi là một trường hợp đặc biệt của tích giữa một ma trận và một ma trận có số cột bằng một. Khi làm việc với numpy, ma trận được mô tả bởi mảng hai chiều, vector được mô tả bởi các mảng một chiều.
Xem ví dụ dưới đây:
>>> A
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
>>> b = np.array([1, 3, 4])
>>> A.dot(b)
array([11, 35, 59, 83])
>>> A*b
array([[ 0, 3, 8],
[ 3, 12, 20],
[ 6, 21, 32],
[ 9, 30, 44]])
Tích của mảng hai chiều A và mảng một chiều b với A.shape[1] == b.shape[0] theo ĐSTT được thực hiện bằng phương thức .dot() của mảng numpy A. Kết quả trả về là một mảng một chiều có shape[0] == 4.
Chúng ta cần chú ý một chút ở đây là kết quả trả về là một mảng một chiều chứ không phải một vector cột (được biểu diễn bởi một mảng hai chiều có shape[1] = 1) như trên lý thuyết. Kết quả
của A*b cũng được chỉ ra để nhắc các bạn phân biệt hai phép nhân này.
Tiếp tục quan sát:
>>> b.dot(A)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: shapes (3,) and (4,3) not aligned: 3 (dim 0) != 4 (dim 0)
>>> c = np.array([1, 2, 3, 4])
>>> c.dot(A)
array([60, 70, 80])
ta thấy rằng nếu đặt b lên trước A thì có lỗi xảy ra vì xung đột chiều. Tuy nhiên nếu mảng một chiều c có kích thước bằng 4 thì lại có thể nhân với mảng hai chiều A được.
Kết quả thu được chính là vector hàng c nhân với ma trận A. (Bạn có thể tự kiểm tra lại).
Có một chút cần lưu ý ở đây: Nếu mảng một chiều được nhân vào sau một mảng hai chiều, nó được coi như một vector cột. Nếu nó được nhân vào trước một mảng hai chiều, nó lại được coi là một vector hàng. Dù sao thì nó vẫn là một vector, và vẫn được lưu bởi một mảng một chiều :). Đây cũng chính là một trong những lý o mà những người ban đầu làm quen với numpy gặp nhiều khó khăn.
Bài tập: Quay lại với Frobineus norm. Có một cách khác để tính bình phương của Frobineus norm của một ma trận dựa trên công thức: \[ ||\mathbf{A}||_F^2 = \text{trace}(\mathbf{AA}^T) = \text{trace}(\mathbf{A}^T\mathbf{A}) \]
trong đó \(\text{trace}()\) là hàm tính tổng các phần tử trên đường chéo của một ma trận vuông.
Cho một mảng hai chiều A, hãy viết hàm fro_trace tính bình phương của Frobineus norm của ma trận này dựa vào công thức trên.
Gợi ý:
- sử dụng hàm
np.diag, hoặc - sử dụng
np.trace(gõhelp(np.trace)trên Terminal hoặc google để biết thêm chi tiết).
Hy vọng các bạn gặp khó khăn chút với Compiler và nhận ra lý do của việc đó ;).
2.12. Softmax III - Phiên bản tổng quát
Chúng ta đã làm quen với Phiên bản ổn định của hàm Softmax với một một mảng một chiều \(\mathbf{z}\):
\[\frac{\exp(z_i)}{\sum_{j=0}^{C-1} \exp(z_j)} = \frac{\exp(-b)\exp(z_i)}{\exp(-b)\sum_{j=0}^{C-1} \exp(z_j)} = \frac{\exp(z_i-b)}{\sum_{j=0}^{C-1} \exp(z_j-b)}\]Bây giờ, chúng ta tiếp tục tổng quát hàm số này để áp dụng cho nhiều phần tử cùng lúc. Giả sử ma trận \(\mathbf{Z}\) là ma trận scores của \(N\) điểm dữ liệu, mỗi hàng \(\mathbf{z}_i\) của ma trận này ứng với score của một điểm dữ liệu. Hãy viết một hàm số trên python để tính softmax cho từng hàng của \(\mathbf{Z}\). Kết quả thu được là một ma trận \(\mathbf{A}\) cùng chiều với \(\mathbf{Z}\) mà mỗi hàng của \(\mathbf{A}\) là kết quả khi áp dụng hàm Softmax lên một hàng tương ứng của \(\mathbf{Z}\).
Bạn đọc cần viết hàm dưới dạng vectorization, tức không sử dụng vòng for.
Gợi ý: Lời giải có thể không vượt quá 2 dòng lệnh.