
- 1. Giới thiệu
- 2. Phân tích toán học
- 3. Bài toán đối ngẫu Lagrange
- 4. Bài toán tối ưu không ràng buộc cho Soft Margin SVM
- 5. Kiểm chứng bằng lập trình
- 6. Tóm tắt và thảo luận
- 7. Tài liệu tham khảo
1. Giới thiệu
Giống như Perceptron Learning Algorithm (PLA), Support Vector Machine (SVM) thuần chỉ làm việc khi dữ liệu của 2 classes là linearly separable. Một cách tự nhiên, chúng ta cũng mong muốn rằng SVM có thể làm việc với dữ liệu gần linearly separable giống như Logistic Regression đã làm được.
Bạn được khuyến khích đọc bài Support Vector Machine trước khi đọc bài này.
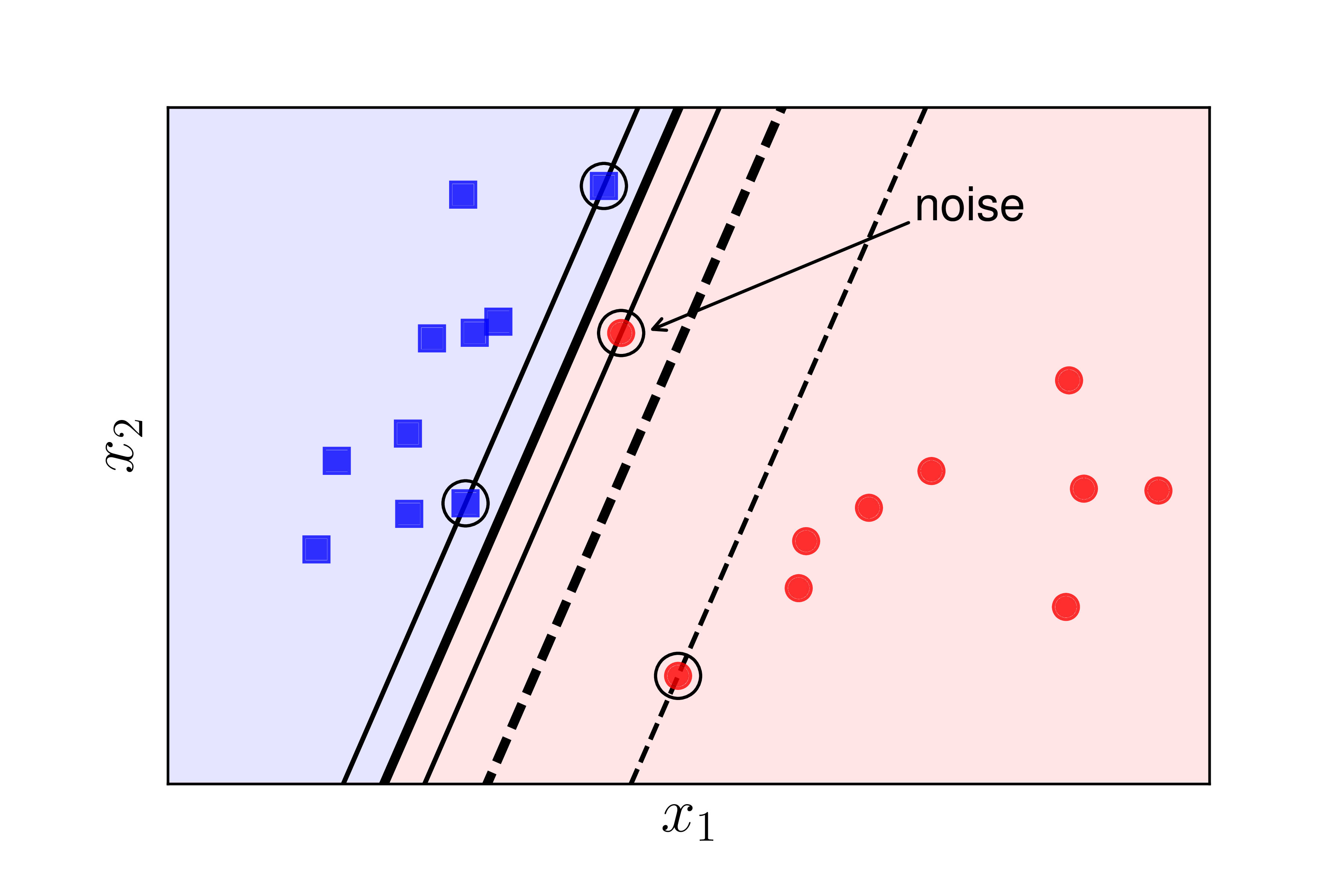
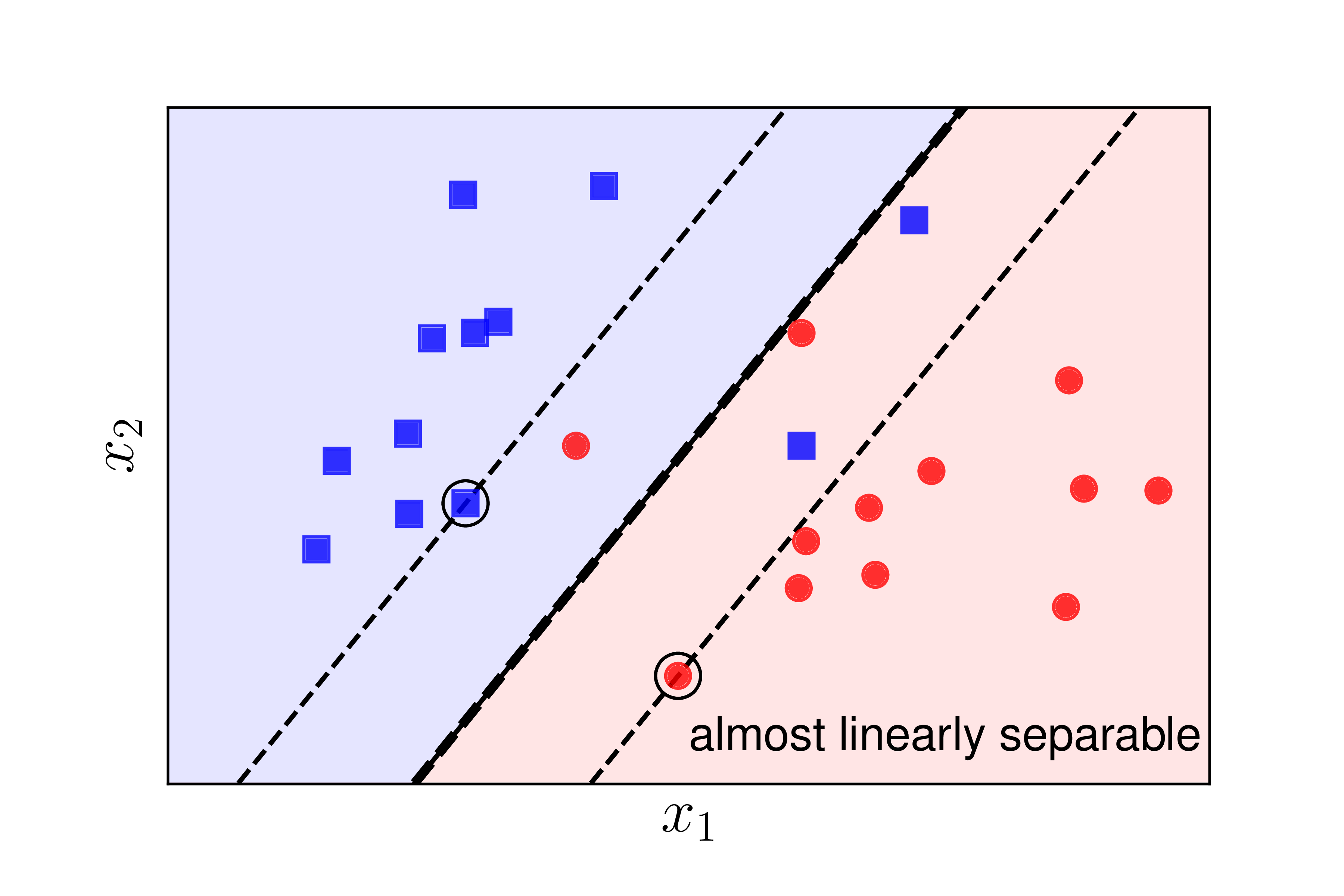
Xét 2 ví dụ trong Hình 1 dưới đây:
a) |
b) |
Có hai trường hợp dễ nhận thấy SVM làm việc không hiệu quả hoặc thậm chí không làm việc:
-
Trường hợp 1: Dữ liệu vẫn linearly separable như Hình 1a) nhưng có một điểm nhiễu của lớp tròn đỏ ở quá gần so với lớp vuông xanh. Trong trường hợp này, nếu ta sử dụng SVM thuần thì sẽ tạo ra một margin rất nhỏ. Ngoài ra, đường phân lớp nằm quá gần lớp vuông xanh và xa lớp tròn đỏ. Trong khi đó, nếu ta hy sinh điểm nhiễu này thì ta được một margin tốt hơn rất nhiều được mô tả bởi các đường nét đứt. SVM thuần vì vậy còn được coi là nhạy cảm với nhiễu (sensitive to noise).
-
Trường hợp 2: Dữ liệu không linearly separable nhưng gần linearly separable như Hình 1b). Trong trường hợp này, nếu ta sử dụng SVM thuần thì rõ ràng bài toán tối ưu là infeasible, tức feasible set là một tập rỗng, vì vậy bài toán tối ưu SVM trở nên vô nghiệm. Tuy nhiên, nếu ta lại chịu hy sinh một chút những điểm ở gần biên giữa hai classes, ta vẫn có thể tạo được một đường phân chia khá tốt như đường nét đứt đậm. Các đường support đường nét đứt mảnh vẫn giúp tạo được một margin lớn cho bộ phân lớp này. Với mỗi điểm nằm lần sang phía bên kia của các đường suport (hay đường margin, hoặc đường biên) tương ứng, ta gọi điểm đó rơi vào vùng không an toàn. Chú ý rằng vùng an toàn của hai classes là khác nhau, giao nhau ở phần nằm giữa hai đường support.
Trong cả hai trường hợp trên, margin tạo bởi đường phân chia và đường nét đứt mảnh còn được gọi là soft margin (biên mềm). Cũng theo cách gọi này, SVM thuần còn được gọi là Hard Margin SVM (SVM biên cứng).
Trong bài này, chúng ta sẽ tiếp tục tìm hiểu một biến thể của Hard Margin SVM có tên gọi là Soft Margin SVM.
Bài toán tối ưu cho Soft Margin SVM có hai cách tiếp cận khác nhau, cả hai đều mang lại những kết quả thú vị và có thể phát triển tiếp thành các thuật toán SVM phức tạp và hiệu quả hơn.
Cách giải quyết thứ nhất là giải một bài toán tối ưu có ràng buộc bằng cách giải bài toán đối ngẫu giống như Hard Margin SVM; cách giải dựa vào bài toán đối ngẫu này là cơ sở cho phương pháp Kernel SVM cho dữ liệu thực sự không linearly separable mà tôi sẽ đề cập trong bài tiếp theo. Hướng giải quyết này sẽ được tôi trình bày trong Mục 3 bên dưới.
Cách giải quyết thứ hai là đưa về một bài toán tối ưu không ràng buộc. Bài toán này có thể giải bằng các phương pháp Gradient Descent. Nhờ đó, cách giải quyết này có thể được áp dụng cho các bài toán large cale. Ngoài ra, trong cách giải này, chúng ta sẽ làm quen với một hàm mất mát mới có tên là hinge loss. Hàm mất mát này có thể mở rộng ra cho bài toán multi-class classification mà tôi sẽ đề cập sau 2 bài nữa (Multi-class SVM). Cách phát triển từ Soft Margin SVM thành Multi-class SVM có thể so sánh với cách phát triển từ Logistic Regression thành Softmax Regression. Hướng giải quyết này sẽ được tôi trình bày trong Mục 4 bên dưới.
Trước hết, chúng ta cùng đi phân tích bài toán.
2. Phân tích toán học
Như đã đề cập phía trên, để có một margin lớn hơn trong Soft Margin SVM, chúng ta cần hy sinh một vài điểm dữ liệu bằng cách chấp nhận cho chúng rơi vào vùng không an toàn. Tất nhiên, chúng ta phải hạn chế sự hy sinh này, nếu không, chúng ta có thể tạo ra một biên cực lớn bằng cách hy sinh hầu hết các điểm. Vậy hàm mục tiêu nên là một sự kết hợp để tối đa margin và tối thiểu sự hy sinh.
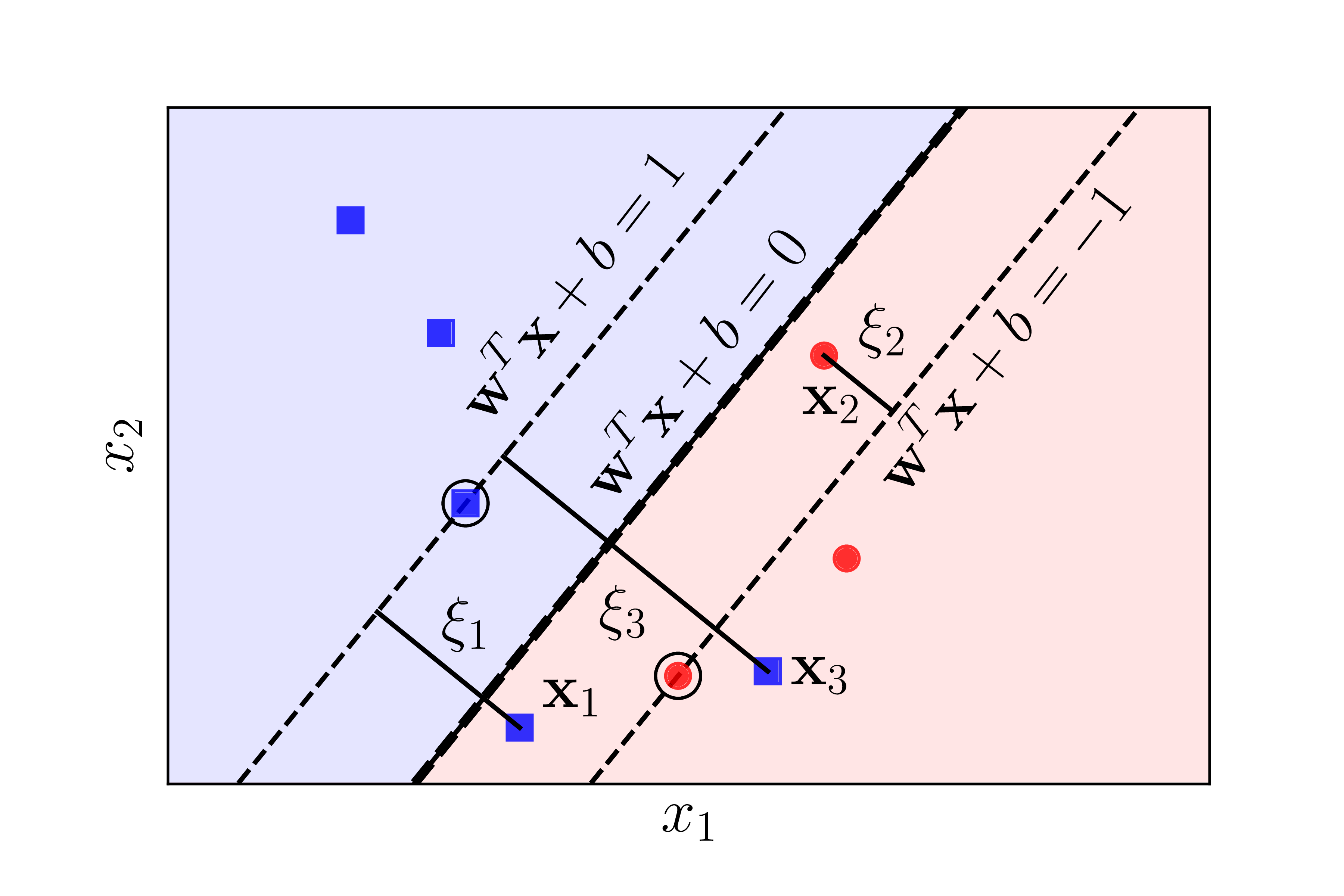
Giống như với Hard Margin SVM, việc tối đa margin có thể đưa về việc tối thiểu \(||\mathbf{w}||_2^2\). Để xác định sự hy sinh, chúng ta cùng theo dõi Hình 2 dưới đây:
|
Hình 2: Giới thiệu các biến slack \(\xi_n\). Với những điểm nằm trong vùng an toàn, \(\xi_n = 0\). Những điểm nằm trong vùng không an toàn nhưng vẫn đúng phía so với đường phân chia tương ứng với các \(0 < \xi_n < 1\), ví dụ \(\mathbf{x}_2\). Những điểm nằm ngược phía với class của chúng so với đường boundary ứng với các \(\xi_n > 1\), ví dụ như \(\mathbf{x}_1\) và \(\mathbf{x}_3\). |
Với mỗi điểm \(\mathbf{x}_n\) trong tập toàn bộ dữ liệu huấn luyện, ta giới thiệu thêm một biến đo sự hy sinh \(\xi_n\) tương ứng. Biến này còn được gọi là slack variable. Với những điểm \(\mathbf{x}_n\) nằm trong vùng an toàn, \(\xi_n = 0\). Với mỗi điểm nằm trong vùng không an toàn như \(\mathbf{x}_1, \mathbf{x}_2\) hay \(\mathbf{x}_3\), ta có \(\xi_i > 0\). Nhận thấy rằng nếu \(y_i= \pm 1\) là nhãn của \(\mathbf{x}_i\) trong vùng không an toàn thì \(\xi_i = |\mathbf{w}^T\mathbf{x}_i + b - y_i|\). (Bạn có nhận ra không?)
Nhắc lại bài toán tối ưu cho Hard Margin SVM: \[ \begin{eqnarray} (\mathbf{w}, b) &=& \arg \min_{\mathbf{w}, b} \frac{1}{2}{||\mathbf{w}||_2^2} \newline \text{subject to:}~ && y_n(\mathbf{w}^T\mathbf{x}_n + b) \geq 1, \forall n = 1, 2, \dots, N ~~~~(1) \end{eqnarray} \]
Với Soft Margin SVM, hàm mục tiêu sẽ có thêm một số hạng nữa giúp tối thiểu sự hy sinh. Từ đó ta có hàm mục tiêu: \[ \frac{1}{2}{||\mathbf{w}||_2^2} + C \sum_{n=1}^N \xi_n \] trong đó \(C\) là một hằng số dương và \(\xi = [\xi_1, \xi_2, \dots, \xi_N]\).
Hằng số \(C\) được dùng để điều chỉnh tầm quan trọng giữa margin và sự hy sinh. Hằng số này được xác định từ trước bởi người lập trình hoặc có thể được xác định bởi cross-validation.
Điều kiện ràng buộc sẽ thay đổi một chút. Với mỗi cặp dữ liệu \((\mathbf{x}_n, y_n)\), thay vì ràng buộc cứng \(y_n(\mathbf{w}^T\mathbf{x}_n + b) \geq 1\), chúng ta sẽ có ràng buộc mềm: \[ y_n(\mathbf{w}^T\mathbf{x}_n + b) \geq 1 - \xi_n \Leftrightarrow 1 - \xi_n - y_n(\mathbf{w}^T\mathbf{x}_n + b) \leq 0, ~~ \forall n = 1, 2, \dots, n \] Và ràng buộc phụ \(\xi_n \geq 0, ~\forall n = 1, 2, \dots, N\).
Tóm lại, ta sẽ có bài toán tối ưu ở dạng chuẩn cho Soft-margin SVM: \[ \begin{eqnarray} (\mathbf{w}, b, \xi) &=& \arg \min_{\mathbf{w}, b, \xi} \frac{1}{2}{||\mathbf{w}||_2^2} + C \sum_{n=1}^N \xi_n \newline \text{subject to:}~ && 1 - \xi_n - y_n(\mathbf{w}^T\mathbf{x}_n + b) \leq 0, \forall n = 1, 2, \dots, N ~~~~(2) \newline && -\xi_n \leq 0, ~\forall n = 1, 2, \dots, N \end{eqnarray} \]
Nhận xét:
-
Nếu \(C\) nhỏ, việc sự hy sinh cao hay thấp không gây ảnh hưởng nhiều tới giá trị của hàm mục tiêu, thuật toán sẽ điều chỉnh sao cho \(||\mathbf{x}||_2^2\) là nhỏ nhất, tức margin là lớn nhất, điều này sẽ dẫn tới \(\sum_{n=1}^N\xi_n\) sẽ lớn theo. Ngược lại, nếu \(C\) quá lớn, để hàm mục tiêu đạt giá trị nhỏ nhất, thuật toán sẽ tập trung vào làm giảm \(\sum_{n=1}^N\xi_n\). Trong trường hợp \(C\) rất rất lớn và hai classes là linearly separable, ta sẽ thu được \(\sum_{n=1}^N\xi_n = 0\). Chú ý rằng giá trị này không thể nhỏ hơn 0. Điều này đồng nghĩa với việc không có điểm nào phải hy sinh, tức ta thu được nghiệm cho Hard Margin SVM. Nói cách khác, Hard Margin SVM chính là một trường hợp đặc biệt của Soft Margin SVM.
-
Bài toán tối ưu \((2)\) có thêm sự xuất hiện của slack variables \(\xi_n\). Những \(\xi_n = 0\) tương ứng với những điểm dữ liệu nằm trong vùng an toàn. Những \(0 < \xi_n \leq 1\) tương ứng với những điểm nằm trong vùng không an toàn những vẫn được phân loại đúng, tức vẫn nằm về đúng phía so với đường phân chia. Những \(\xi_n > 1\) tương ứng với các điểm bị phân loại sai.
-
Hàm mục tiêu trong bài toán tối ưu \((2)\) là một hàm lồi vì nó là tổng của hai hàm lồi: hàm norm và hàm tuyến tính. Các hàm ràng buộc cũng là các hàm tuyến tính theo \((\mathbf{w}, b, \xi)\). Vì vậy bải toán tối ưu \((2)\) là một bài toán lồi, hơn nữa nó có thể biểu diễn dưới dạng một Quadratic Programming (QP).
Dưới đây, chúng ta sẽ cùng giải quyết bài toán tối ưu \((2)\) bằng hai cách khác nhau.
3. Bài toán đối ngẫu Lagrange
Chú ý rằng bài toán này có thể giải trực tiếp bằng các toolbox hỗ trợ QP, nhưng giống như với Hard Margin SVM, chúng ta sẽ quan tâm hơn tới bài toán đối ngẫu.
Trước kết, ta cần kiểm tra tiêu chuẩn Slater cho bài toán tối ưu lồi \((2)\). Nếu tiêu chuẩn này được thoả mãn, strong duality sẽ thoả mãn, và ta sẽ có nghiệm của bài toán tối ưu \((2)\) là nghiệm của hệ điều kiện KKT. (Những kiến thức được đề cập trong mục này có thể được tìm thấy trong Bài 18).
3.1. Kiểm tra tiêu chuẩn Slater
Rõ ràng là với mọi \(n = 1, 2, \dots, N\) và mọi \((\mathbf{w}, b)\), ta luôn có thể tìm được các số dương \(\xi_n, n = 1, 2, \dots, N\) đủ lớn sao cho: \[ y_n(\mathbf{w}^T\mathbf{x}_n + b) + \xi_n > 1, ~\forall n = 1, 2, \dots, N \]
Vậy nên bài toán này thoả mãn tiêu chuẩn Slater.
3.2. Lagrangian của bài toán Soft-margin SVM
Lagrangian cho bài toán \((2)\) là:
\[ \mathcal{L}(\mathbf{w}, b, \xi, \lambda, \mu) = \frac{1}{2}{||\mathbf{w}||_2^2} + C \sum_{n=1}^N \xi_n + \sum_{n=1}^N \lambda_n ( 1 - \xi_n - y_n(\mathbf{w}^T\mathbf{x}_n + b)) - \sum_{n=1}^N \mu_n \xi_n ~ (3) \]
với \(\lambda = [\lambda_1, \lambda_2, \dots, \lambda_N]^T \succeq 0\) và \(\mu = [\mu_1, \mu_2, \dots, \mu_N]^T \succeq 0\) là các biến đối ngẫu Lagrange (vector nhân tử Lagrange).
3.3. Bài toán đối ngẫu
Hàm số đối ngẫu của bài toán tối ưu \((2)\) là: \[ g(\lambda, \mu) = \min_{\mathbf{w}, b, \xi} \mathcal{L}(\mathbf{w}, b, \xi, \lambda, \mu) \] Với mỗi cặp \((\lambda,\mu)\), chúng ta sẽ quan tâm tới \((\mathbf{w}, b, \xi)\) thoả mãn điều kiện đạo hàm của Lagrangian bằng 0:
\[ \begin{eqnarray} \frac{\partial \mathcal{L}}{\partial \mathbf{w}} & = & 0 \Leftrightarrow \mathbf{w} = \sum_{n=1}^N \lambda_n y_n \mathbf{x}_n &&(4)\newline \frac{\partial \mathcal{L}}{\partial b} & = & 0 \Leftrightarrow \sum_{n=1}^N \lambda_n y_n = 0 && (5)\newline \frac{\partial \mathcal{L}}{\partial \xi_n} & = & 0 \Leftrightarrow \lambda_n = C - \mu_n && (6) \end{eqnarray} \]
Từ \((6)\) ta thấy rằng ta chỉ quan tâm tới những cặp \((\lambda, \mu)\) sao cho \(\lambda_n = C - \mu_n\). Từ đây ta cũng suy ra \(0 \leq \lambda_n, \mu_n \leq C, n = 1, 2, \dots, N\). Thay các biểu thức này vào Lagrangian ta sẽ thu được hàm đối ngẫu: \[ g(\lambda, \mu) = \sum_{n=1}^N \lambda_n - \frac{1}{2} \sum_{n=1}^N\sum_{m=1}^N \lambda_n \lambda_m y_n y_m \mathbf{x}_n^T\mathbf{x}_m \] Chú ý rằng hàm này không phụ thuộc vào \(\mu\) nhưng ta cần lưu ý ràng buộc \((6)\), ràng buộc này và điều kiện không âm của \(\lambda\) có thể được viết gọn lại thành \(0 \leq \lambda_n \leq C\), và ta đã giảm được biến \(\mu\). Lúc này, bài toán đối ngẫu được xác định bới:
\[ \begin{eqnarray} \lambda &=& \arg \max_{\lambda} g(\lambda) &&\newline \text{subject to:}~ && \sum_{n=1}^N \lambda_ny_n = 0 && (7)\newline && 0 \leq \lambda_n \leq C, ~\forall n= 1, 2, \dots, N && (8) \end{eqnarray} \]
Bài toán này gần giống với bài toán đối ngẫu của Hard Margin SVM, chỉ khác là ta có chặn trên cho mỗi \(\lambda_n\). Khi \(C\) rất lớn, ta có thể coi hai bài toán là như nhau. Ràng buộc \((8)\) còn được gọi là box constraint vì không gian các điểm \(\lambda\) thoả mãn ràng buộc này giống như một hình hộp chữ nhật trong không gian nhiều chiều.
Bài toán này cũng hoàn toàn giải được bằng các công cụ giải QP thông thường, ví dụ CVXOPT như tôi đã thực hiện trong bài Hard Margin SVM.
Sau khi tìm được \(\lambda\) của bài toán đối ngẫu, ta vẫn phải quay lại tìm nghiệm \((\mathbf{w}, b, \xi)\) của bài toán gốc. Để làm điều này, chúng ta cùng xem xét hệ điều kiện KKT.
3.4. Hệ điều kiện KKT
Hệ điều kiện KKT của bài toán tối ưu Soft Margin SVM là, với mọi \(n = 1, 2, \dots, N\): \[ \begin{eqnarray} 1 - \xi_n - y_n(\mathbf{w}^T\mathbf{x}_n + b) &\leq& 0 && (9) \newline -\xi_n &\leq& 0 &&(10)\newline \lambda_n &\geq& 0 &&(11)\newline \mu_n &\geq & 0 && (12)\newline \lambda_n ( 1 - \xi_n - y_n(\mathbf{w}^T\mathbf{x}_n + b)) &=& 0 && (13)\newline \mu_n \xi_n &=& 0 &&(14)\newline \mathbf{w} &=& \sum_{n=1}^N \lambda_n y_n \mathbf{x}_n &&(4)\newline \sum_{n=1}^N \lambda_n y_n &=& 0 && (5)\newline \lambda_n &=& C - \mu_n && (6) \end{eqnarray} \] (Để cho dễ hình dung, tôi đã viết lại các điều kiện \((4), (5), (6)\) trong hệ này.)
Ta có một vài quan sát như sau:
-
Nếu \(\lambda_n = 0\) thì từ \((6)\) ta suy ra \(\mu_n = C \neq 0\). Kết hợp với \((14)\) ta suy ra \(\xi_n = 0\). Nói cách khác, không có sự hy sinh nào xảy ra ở \(\mathbf{x}_n\), tức \(\mathbf{x}_n\) nằm trong vùng an toàn.
-
Nếu \(\lambda_n > 0\), từ \((13)\) ta có: \[ y_n(\mathbf{w}^T\mathbf{x}_n + b) = 1 - \xi_n \]
- Nếu \(0 < \lambda_n < C\), từ \((6)\) ta suy ra \(\mu_n \neq 0\) và từ \((14)\) ta lại có \(\xi_n = 0\). Nói cách khác, \(y_n(\mathbf{w}^T\mathbf{x}_n + b) = 1\), hay những điểm \(\mathbf{x}_n\) nằm chính xác trên margin.
- Nếu \(\lambda_n = C\), thì \(\mu_n = 0\) và \(\xi_n\) có thể nhận bất kỳ giá trị nào không âm. Nếu \(\xi_n \leq 1, \mathbf{x}_n\) sẽ được phân lớp đúng (vẫn đúng phía so với đường phân chia). Ngược lại, các điểm tương ứng với \(\xi_n > 1\) sẽ bị phân lớp sai.
- \(\lambda_n\) không thể lớn hơn \(C\) vì khi đó theo \((6)\), \(\mu_n < 0\), mâu thuẫn với \((12)\).
Ngoài ra, những điểm tương ứng với \(0 < \lambda_n \leq C\) bây giờ là sẽ là các support vectors. Mặc dù những điểm này có thể không nằm trên margins, chúng vẫn được coi là support vectors vì có công đóng góp cho việc tính toán \(\mathbf{w}\) thông qua phương trình \((4)\).
Như vậy, dựa trên các giá trị của \(\lambda_n\) ta có thể dự đoán được vị trí tương đối của \(\mathbf{x}_n\) so với hai margins. Đặt \(\mathcal{M} = \{n: 0 < \lambda_n < C \}\) và \(\mathcal{S} = \{m: 0 < \lambda_m \leq C\}\). Tức \(\mathcal{M}\) là tập hợp các chỉ số của các điểm nằm chính xác trên margins - hỗ trợ cho việc tính \(b\), \(\mathcal{S}\) là tập hợp các chỉ số của các support vectors - hỗ trợ trực tiếp cho việc tính \(\mathbf{w}\). Tương tự như với Hard Margin SVM, các hệ số \(\mathbf{w}, b\) có thể được xác định bởi: \[ \begin{eqnarray} \mathbf{w} &=& \sum_{m \in \mathcal{S}} \lambda_m y_m \mathbf{x}_m & ~~~(15) \newline b &=& \frac{1}{N_{\mathcal{M}}} \sum_{n \in \mathcal{M}} (y_n - \mathbf{w}^T\mathbf{x}_n) = \frac{1}{N_{\mathcal{M}}} \sum_{n \in \mathcal{M}} \left(y_n - \sum_{m \in \mathcal{S}} \lambda_m y_m \mathbf{x}_m^T\mathbf{x}_n\right) & ~~~ (16) \end{eqnarray} \]
Nhắc lại rằng mục đích cuối cùng là xác định nhãn cho một điểm mới chứ không phải là tính \(\mathbf{w}\) và \(b\) nên ta quan tâm hơn tới cách xác định giá trị của biếu thức sau với một điểm dữ liệu \(\mathbf{x}\) bất kỳ: \[ \mathbf{w}^T\mathbf{x} + b = \sum_{m \in \mathcal{S}} \lambda_m y_m \mathbf{x}_m^T \mathbf{x} + \frac{1}{N_{\mathcal{M}}} \sum_{n \in \mathcal{M}} \left(y_n - \sum_{m \in \mathcal{S}} \lambda_m y_m \mathbf{x}_m^T\mathbf{x}_n\right) \]
Và trong cách tính này, ta chỉ cần quan tâm tới tích vô hướng của hai điểm bất kỳ. Ở bài sau các bạn sẽ thấy rõ lợi ích của việc này nhiều hơn.
4. Bài toán tối ưu không ràng buộc cho Soft Margin SVM
Trong mục này, chúng ta sẽ đưa bài toán tối ưu có ràng buộc \((2)\) về một bài toán tối ưu không ràng buộc, và có có khả năng giải được bằng các phương pháp Gradient Descent.
4.1. Bài toán tối ưu không ràng buộc tương đương
Để ý thấy rằng điều kiện ràng buộc thứ nhất: \[ 1 - \xi_n -y_n(\mathbf{w}^T\mathbf{x} + b)) \leq 0 \Leftrightarrow \xi_n \geq 1 - y_n(\mathbf{w}^T\mathbf{x} + b)) \] Kết hợp với điều kiện \(\xi_n \geq 0\) ta sẽ thu được bài toán ràng buộc tương đương với bài toán \((2)\) như sau:
\[ \begin{eqnarray} (\mathbf{w}, b, \xi) &=& \arg \min_{\mathbf{w}, b, \xi} \frac{1}{2}{||\mathbf{w}||_2^2} + C \sum_{n=1}^N \xi_n \newline \text{subject to:}~ && \xi_n \geq \max(0, 1 - y_n(\mathbf{w}^T\mathbf{x} + b)), ~\forall n = 1, 2, \dots, N~~~ (17) \end{eqnarray} \]
Tiếp theo, để đưa bài toán \((17)\) về dạng không ràng buộc, chúng ta sẽ chứng minh nhận xét sau đây bằng phương pháp phản chứng:
Nếu \((\mathbf{w}, b, \xi)\) là nghiệm của bài toán tối ưu \((17)\), tức tại đó hàm mục tiêu đạt giá trị nhỏ nhất, thì: \[ \xi_n = \max(0, 1 - y_n(\mathbf{w}^T\mathbf{x}_n + b)), ~\forall n = 1, 2, \dots, N ~~~ (18) \]
Thật vậy, giả sử ngược lại, tồn tại \(n\) sao cho: \[ \xi_n > \max(0, 1 - y_n(\mathbf{w}^T\mathbf{x}_n + b)) \] ta chọn \(\xi_n’ = \max(0, 1 - y_n(\mathbf{w}^T\mathbf{x}_n + b))\), ta sẽ thu được một giá trị thấp hơn của hàm mục tiêu, trong khi tất cả các ràng buộc vẫn được thoả mãn. Điều này mâu thuẫn với việc hàm mục tiêu đã đạt giá trị nhỏ nhất!
Vậy nhận xét \((18)\) được chứng minh.
Khi đó, ta thay toàn bộ các giá trị của \(\xi_n\) trong \((18)\) vào hàm mục tiêu: \[ \begin{eqnarray} (\mathbf{w}, b, \xi) &=& \arg \min_{\mathbf{w}, b, \xi} \frac{1}{2}{||\mathbf{w}||_2^2} + C \sum_{n=1}^N \max(0, 1 - y_n(\mathbf{w}^T\mathbf{x}_n + b)) \newline \text{subject to:}~ && \xi_n = \max(0, 1 - y_n(\mathbf{w}^T\mathbf{x}_n + b)), ~\forall n = 1, 2, \dots, N~~~ (19) \end{eqnarray} \]
Rõ ràng rằng biến số \(\xi\) không còn quan trọng trong bài toán này nữa, ta có thể lược bỏ nó mà không làm thay đổi nghiệm của bài toán: \[ (\mathbf{w}, b)= \arg \min_{\mathbf{w}, b} \frac{1}{2}{||\mathbf{w}||_2^2} + C \sum_{n=1}^N \max(0, 1 - y_n(\mathbf{w}^T\mathbf{x}_n + b)) \triangleq \arg\min_{\mathbf{w}, b} J(\mathbf{w}, b) ~~~~ (20) \] Đây là một bài toán tối ưu không ràng buộc với hàm mất mát \(J(\mathbf{w}, b)\). Bài toán này có thể giải được bằng các phương pháp Gradient Descent. Nhưng trước hết, chúng ta cùng xem xét hàm mất mát này từ một góc nhìn khác, bằng định nghĩa của một hàm gọi là hinge loss
4.2. Hinge loss
Nhắc lại một chút về hàm cross entropy chúng ta đã biết từ bài Logistic Regression và Softmax Regression. Với mỗi cặp hệ số \((\mathbf{w}, b)\) và cặp dữ liệu, nhãn \((\mathbf{x}_n, y_n)\), đặt \(z_n = \mathbf{w}^T\mathbf{x}_n + b\) và \(a_n = \sigma(z_n)\) ( \(\sigma\) là sigmoid function). Hàm cross entropy được định nghĩa là: \[ J_n^1(\mathbf{w}, b) = -(y_n \log(a_n) + (1 - y_n) \log(1 - a_n)) \] Chúng ta đã biết rằng, hàm cross entropy đạt giá trị càng nhỏ nếu xác suất \(a_n\) càng gần với \(y_n\) \((0 < a_n < 1)\).
Ở đây, chúng ta làm quen với một hàm số khác cũng được sử dụng nhiều trong các classifiers: \[ J_n(\mathbf{w}, b) = \max(0, 1 - y_nz_n) \] Hàm này có tên là hinge loss. Trong đó, \(z_n\) có thể được coi là score của \(\mathbf{x}_n\) ứng với cặp hệ số \((\mathbf{w}, b)\), \(y_n\) chính là đầu ra mong muốn.
Hình 3 đưới dây mô tả hàm số hinge loss \(f(ys) = \max(0, 1 - ys)\) và so sánh với hàm zero-one loss. Hàm zero-one loss là hàm đếm các điểm bị misclassified.
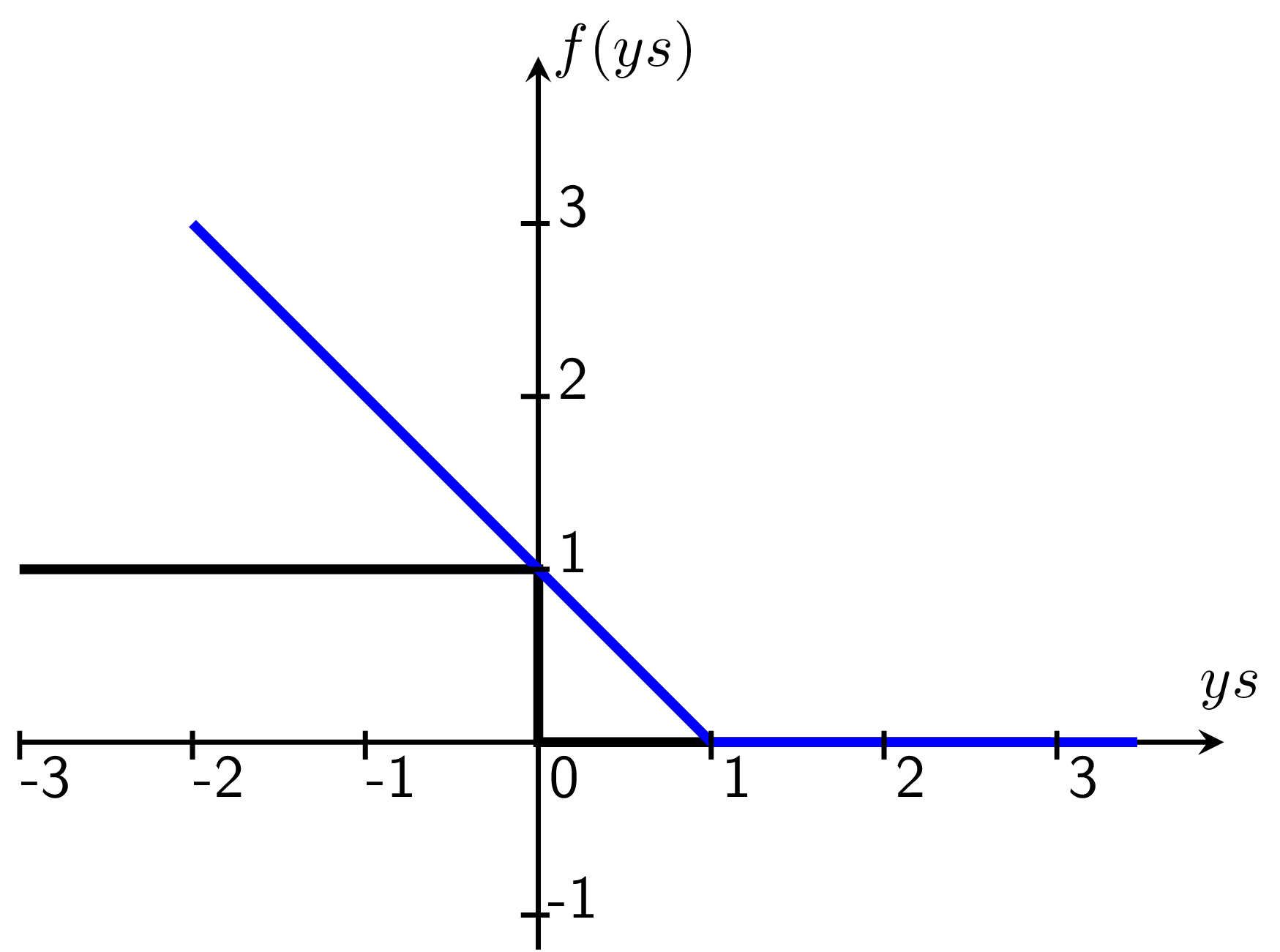
|
Hình 3: Hinge loss (màu xanh) và zeros-one loss (màu đen). Với zero-one loss, những điểm nằm xa margin (hoành độ bằng 1) và boundary (hoành độ bằng 0) được đối xử như nhau. Trong khi đó, với hinge loss, những điểm ở xa gây ra mất mát nhiều hơn. |
Trong Hình 3, biến số là \(y\) là tích của đầu ra mong muốn (ground truth) và đầu ra tính được (score). Những điểm ở phía phải của trục tung ứng với những điểm được phân loại đúng, tức \(s\) tìm được cùng dấu với \(y\). Những điểm ở phía trái của trục tung ứng với các điểm bị phân loại sai. Ta có các nhận xét:
-
Với hàm zero-one loss, các điểm có score ngược dấu với đầu ra mong muốn sẽ gây ra mất mát như nhau (bằng 1), bất kể chúng ở gần hay xa đường phân chia (trục tung). Đây là một hàm rời rạc, rất khó tối ưu và ta cũng khó có thể đo đếm được sự hy sinh như đã định nghĩa ở phần đầu.
-
Với hàm hinge loss, những điểm nằm trong vùng an toàn, ứng với \(ys \geq 1\), sẽ không gây ra mất mát gì. Những điểm nằm giữa margin của class tương ứng và đường phân chia tương ứng với \(0 < y < 1\), những điểm này gây ra một mất mát nhỏ. Những điểm bị misclassifed, tức \(y < 0\) sẽ gây ra mất mát lớn hơn, vì vậy, khi tối thiểu hàm mất mát, ta sẽ tránh được những điểm bị misclassifed và lấn sang phần class còn lại quá nhiều. Đây chính là một ưu điểm của hàm hinge loss.
-
Hàm hinge loss là một hàm liên tục, và có đạo hàm tại gần như mọi nơi (almost everywhere differentiable) trừ điểm có hoành độ bằng 1. Ngoài ra, đạo hàm của hàm này cũng rất dễ xác định: bằng -1 tại các điểm nhỏ hơn 1 và bằng 0 tại các điểm lớn hơn 1. Tại 1, ta có thể coi như đạo hàm của nó bằng 0 giống như cách tính đạo hàm của hàm ReLU.
4.3. Xây dựng hàm mất mát
Bây giờ, nếu ta xem xét bài toán Soft Margin SVM dưới góc nhìn hinge loss:
Với mỗi cặp \((\mathbf{w}, b)\), đặt: \[ L_n(\mathbf{w}, b) = \max(0, 1 - y_n(\mathbf{w}^T\mathbf{x}_n + b)) \] Lấy tổng tất cả các loss này (giống như cách mà Logistic Regression hay Softmax Regression lấy tổng của tất cả các cross entropy loss) theo \(n\) ta được: \[ L(\mathbf{w}, b) = \sum_{n=1}^N L_i = \sum_{n=1}^N \max(0, 1 - y_n(\mathbf{w}^T\mathbf{x}_n + b)) \]
Câu hỏi đặt ra là, nếu ta trực tiếp tối ưu tổng các hinge loss này thì điều gì sẽ xảy ra?
Trong trường hợp dữ liệu trong hai class là linearly separable, ta sẽ có giá trị tối ưu tìm được của \(L(\mathbf{w}, b)\) là bằng 0. Điều này có nghĩa là: \[ 1 - y_n (\mathbf{w}^T\mathbf{x}_n + b) \leq 0, ~\forall n = 1, 2, \dots, N \] Nhân cả hai về với một hằng số \(a > 1\) ta có: \[ \begin{eqnarray} a - y_n (a\mathbf{w}^T\mathbf{x}_n + ab) &\leq& 0, ~\forall n = 1, 2, \dots, N \newline \Rightarrow 1 - y_n (a\mathbf{w}^T\mathbf{x}_n + ab) &\leq& 1 - a < 0, ~\forall n = 1, 2, \dots, N \end{eqnarray} \] Điều này nghĩa là \((a\mathbf{w}, ab)\) cũng là nghiệm của bài toán. Nếu không có điều kiện gì thêm, bài toán có thể dẫn tới nghiệm không ổn định vì các hệ số của nghiệm có thể lớn tuỳ ý!
Để tránh bug này, chúng ta cần thêm một số hạng nữa vào \(L(\mathbf{w}, b)\) gọi là số hạng regularization, giống như cách chúng ta đã làm để tránh overfitting trong neural networks. Lúc này, ta sẽ có hàm mất mát tổng cộng là: \[ J(\mathbf{w}, b) = L(\mathbf{w}, b) + \lambda R(\mathbf{w}, b) \] với \(\lambda\) là một số dương, gọi là regularization parameter, hàm \(R()\) sẽ giúp hạn chế việc các hệ số \((\mathbf{w}, b)\) trở nên quá lớn. Có nhiều cách chọn hàm \(R()\), nhưng cách phổ biến nhất là \(l_2\), khi đó hàm mất mát của Soft Margin SVM sẽ là: \[ J(\mathbf{w}, b) = \sum_{n=1}^N \max(0, 1 - y_n(\mathbf{w}^T\mathbf{x}_n + b)) + \frac{\lambda}{2} ||\mathbf{w}||_2^2 ~~~~~~~~~~~(21) \]
Kỹ thuật này còn gọi là weight decay. Chú ý rằng weight decay thường không được áp dụng lên thành phần bias \(b\).
Ta thấy rằng hàm mất mát \((21)\) giống với hàm mất mát \((20)\) với \(\lambda = \frac{1}{C}\). Ở đây, tôi đã lấy \(\lambda /2\) để biểu thức đạo hàm được đẹp hơn.
Trong phần tiếp theo của mục này, chúng ta sẽ quan tâm tới bài toán tối ưu hàm mất mát được cho trong \((21)\).
Nhận thấy rằng ta có thể khiến biểu thức \((19)\) gọn hơn một chút bằng cách sử dụng bias trick như đã làm trong Linear Regression hay các bài về neurel networks. Bằng cách mở rộng thêm một thành phần bằng 1 vào các điểm dữ liệu \(\mathbf{x}_n \in \mathbb{R}^d\) để được \(\bar{\mathbf{x}}_n \in \mathbb{R}^{d+1}\) và kết hợp \(\mathbf{w}, b\) thành một vector \(\bar{\mathbf{w}} = [\mathbf{w}^T, b]^T \in \mathbb{R}^{d+1}\) ta sẽ có một biểu thức gọn hơn. Khi đó, hàm mất mát trong \((21)\) có thể được viết gọn thành: \[ J(\mathbf{\bar{w}}) = \underbrace{\sum_{n=1}^N \max(0, 1 - y_n\bar{\mathbf{w}}^T\mathbf{\bar{x}}_n)}_{\text{hinge loss}} + \underbrace{\frac{\lambda}{2} ||\mathbf{w}||_2^2}_{\text{regularization}} \]
Các bạn có thể nhận thấy rằng đây là một hàm lồi theo \(\mathbf{\bar{w}}\) vì:
-
\(1 - y_n\bar{\mathbf{w}}^T\mathbf{\bar{x}}_n\) là 1 hàm tuyến tính nên nó là một hàm lồi. Hàm hằng số là một hàm lồi, \(\max\) cuả hai hàm lồi là một hàm lồi. Vậy biểu thức hinge loss là một hàm lồi.
-
Norm là một hàm lồi, vậy số hạng regularization cũng là một hàm lồi.
-
Tổng của hai hàm lồi là một hàm lồi.
Vì bài toán tối ưu bây giờ là không ràng buộc, chúng ta có thể sử dụng các phương pháp Gradient Descent để tối ưu. Hơn nữa, vì tính chất lồi của hàm mất mát, nếu chọn learning rate không quá lớn và số vòng lặp đủ nhiều, thuật toán sẽ hội tụ tới điểm global optimal của bài toán.
4.4. Tối ưu hàm mất mát
Trước hết ta cần tính được đạo hàm của hàm mất mát theo \(\mathbf{\bar{w}}\). Việc này thoáng qua có vẻ hơi phức tạp vì ta cần tính đạo hàm của hàm \(\max\), nhưng nếu chúng ta nhìn vào đạo hàm của hinge loss, ta có thể tính được đạo hàm theo \(\mathbf{\bar{w}}\) một cách đơn giản.
Chúng ta tạm quên đi đạo hàm của phần regularization vì nó đơn giản bằng \(\lambda \left[\begin{matrix} \mathbf{w}\newline 0 \end{matrix}\right]\) với thành phần 0 ở cuối chính là đạo hàm theo bias của thành phần regularization.
Với phần hinge loss, xét từng điểm dữ liệu, ta có hai trường hợp:
-
TH1: Nếu \( 1 - y_n \mathbf{\bar{w}}^T\mathbf{\bar{x}}_n \leq 0\), ta có ngay đạo hàm theo \(\mathbf{\bar{w}}\) bằng 0.
-
TH2: Nếu \( 1 - y_n \mathbf{\bar{w}}^T\mathbf{\bar{x}}_n > 0\), đạo hàm theo \(\mathbf{w}\) chính là \(-y_n\mathbf{x}_n\).
Để tính gradient cho toàn bộ dữ liệu, chúng ta cần một chút kỹ năng biến đổi đại số tuyến tính.
Đặt: \[ \begin{eqnarray} \mathbf{Z} &=& [y_1 \mathbf{\bar{x}}_1, y_2 \mathbf{\bar{x}}_2, \dots, y_N\mathbf{\bar{x}}_N] & ~~~(22) \newline \mathbf{u} &=& [y_1\mathbf{\bar{w}}^T\mathbf{\bar{x}}_1,y_2\mathbf{\bar{w}}^T\mathbf{\bar{x}}_2, \dots, y_N \mathbf{\bar{w}}^T \mathbf{\bar{x}}_N] = \mathbf{\bar{w}}^T\mathbf{Z} & ~~~ (23) \end{eqnarray} \]
với chú ý rằng \(\mathbf{u}\) là một vector hàng.
Tiếp tục, ta cần xác định các vị trí của \(\mathbf{u}\) có giá trị nhỏ hơn 1, tức ứng với TH2 ở trên. Bằng cách đặt: \[ \mathcal{H} = \{n: u_n < 1\} \] ta có thể suy ra cách tính đạo hàm theo \(\mathbf{\bar{w}}\) của hàm mất mát là \[ \nabla J(\mathbf{\bar{w}}) = \sum_{n \in \mathcal{H}} - y_n\mathbf{\bar{x}}_n + \lambda \left[\begin{matrix} \mathbf{w}\newline 0 \end{matrix}\right] ~~~ (24) \] Các bạn sẽ thấy cách tính toán giá trị này một cách hiệu quả trong phần lập trình.
Vậy quy tắc cập nhật của \(\mathbf{\bar{w}}\) sẽ là: \[ \mathbf{\bar{w}} = \mathbf{\bar{w}} - \eta \left(\sum_{n \in \mathcal{H}} - y_n\mathbf{\bar{x}}_n + \lambda \left[\begin{matrix} \mathbf{w}\newline 0 \end{matrix}\right]\right) ~~~ (25) \] với \(\eta\) là learning rate.
Với các bài toán large-scale, ta có thể sử dụng phương pháp Mini-batch Gradient Descent để tối ưu. Đây chính là một ưu điểm của hướng tiếp cận theo hinge loss.
5. Kiểm chứng bằng lập trình
Trong mục này, chúng ta cùng làm hai thí nghiệm nhỏ. Thứ nghiệm thứ nhất sẽ đi tìm nghiệm của một bài toán Soft Margin SVM bằng ba cách khác nhau: Sử dụng thư viện sklearn, Giải bài toán đối ngẫu bằng CVXOPT, và Tối ưu hàm mất mát không ràng bằng phương pháp Gradient Descent. Nếu mọi tính toán ở trên là chính xác, nghiệm của ba cách làm này sẽ giống nhau, khác nhau có thể một chút bởi sai số trong tính toán. Ở thí nghiệm thứ hai, chúng ta sẽ thay \(C\) bởi những giá trị khác nhau và cùng xem các margin thay đổi như thế nào.
5.1. Giải bài toán Soft Margin bằng 3 cách khác nhau
Source code cho phần này có thể được tìm thấy tại đây.
5.1.1. Khai báo thư viện và tạo dữ liệu giả
# generate data
# list of points
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdist
np.random.seed(21)
from matplotlib.backends.backend_pdf import PdfPages
means = [[2, 2], [4, 1]]
cov = [[.3, .2], [.2, .3]]
N = 10
X0 = np.random.multivariate_normal(means[0], cov, N)
X1 = np.random.multivariate_normal(means[1], cov, N)
X1[-1, :] = [2.7, 2]
X = np.concatenate((X0.T, X1.T), axis = 1)
y = np.concatenate((np.ones((1, N)), -1*np.ones((1, N))), axis = 1)
Hình 4 minh hoạ các điểm dữ liệu của hai classes.
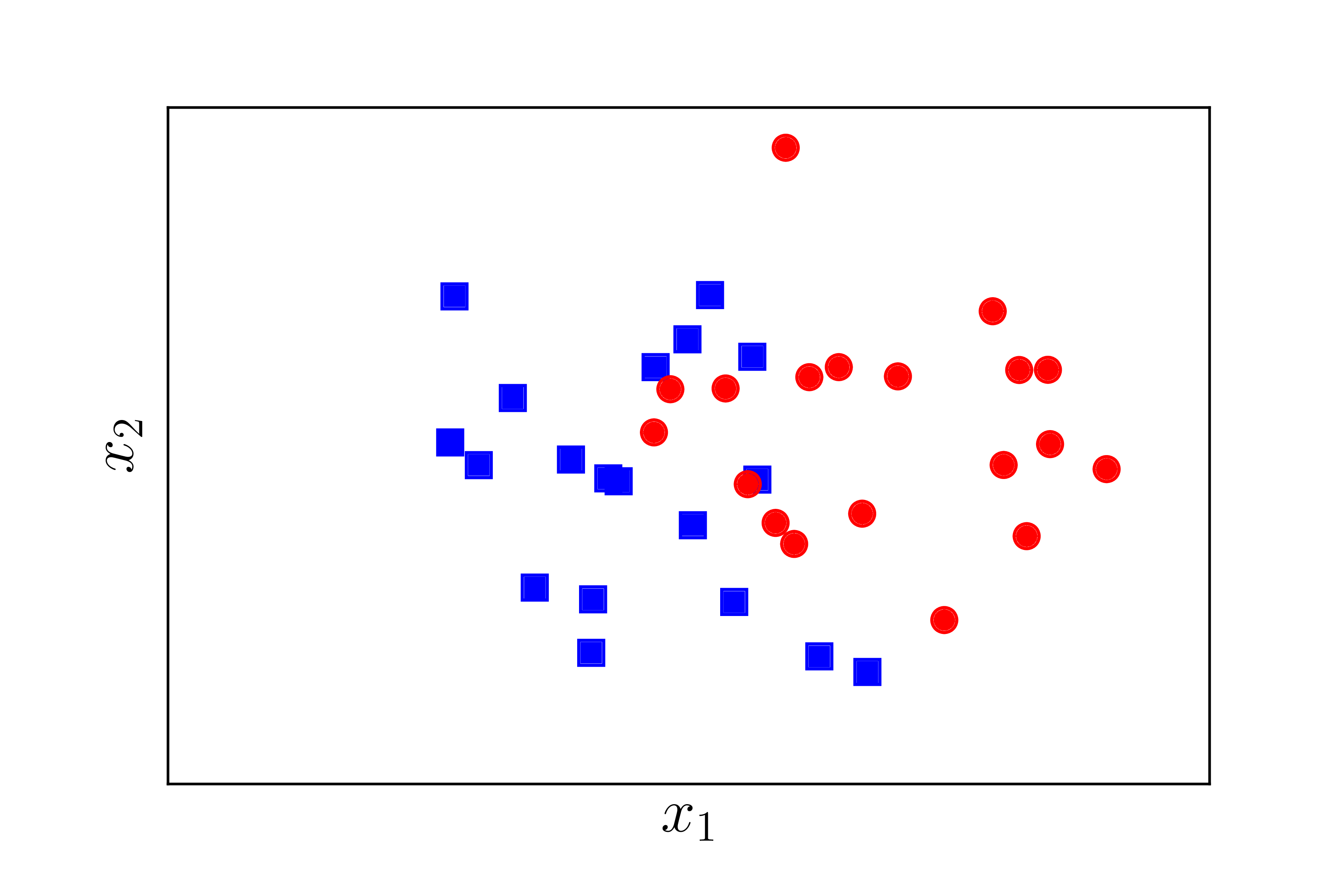
|
Hình 4: Tạo dữ liệu cho thí nghiệm. Dữ liệu của hai class là gần như linearly separable. |
5.1.2. Giải bài toán bằng thư viện sklearn
Ta chọn \(C = 100\) trong thí nghiệm này:
from sklearn.svm import SVC
C = 100
clf = SVC(kernel = 'linear', C = C)
clf.fit(X, y)
w_sklearn = clf.coef_.reshape(-1, 1)
b_sklearn = clf.intercept_[0]
print(w_sklearn.T, b_sklearn)
Nghiệm tìm được:
[[-1.87461946 -1.80697358]] 8.49691190196
5.1.3. Tìm nghiệm bằng giải bài toán đối ngẫu
Tương tự như việc giải bài toán Hard Margin SVM, chỉ khác rằng ta có thêm ràng buộc về chặn trên của các nhân thử Lagrange:
from cvxopt import matrix, solvers
# build K
V = np.concatenate((X0.T, -X1.T), axis = 1)
K = matrix(V.T.dot(V))
p = matrix(-np.ones((2*N, 1)))
# build A, b, G, h
G = matrix(np.vstack((-np.eye(2*N), np.eye(2*N))))
h = matrix(np.vstack((np.zeros((2*N, 1)), C*np.ones((2*N, 1)))))
A = matrix(y.reshape((-1, 2*N)))
b = matrix(np.zeros((1, 1)))
solvers.options['show_progress'] = False
sol = solvers.qp(K, p, G, h, A, b)
l = np.array(sol['x'])
print('lambda = \n', l.T)
lambda =
[[ 1.11381472e-06 9.99999967e+01 1.10533112e-06 6.70163540e-06
3.40838760e+01 4.73972850e-06 9.99999978e+01 3.13320446e-06
9.99999985e+01 5.06729333e+01 9.99999929e+01 3.23564235e-06
9.99999984e+01 9.99999948e+01 1.37977626e-06 9.99997155e+01
3.45005660e-06 1.46190314e-06 5.50601997e-06 1.45062544e-06
1.85373848e-06 1.14181647e-06 8.47565685e+01 9.99999966e+01
9.99999971e+01 8.00764708e-07 2.65537193e-06 1.45230729e-06
4.15737085e-06 9.99999887e+01 9.99999761e+01 8.98414770e-07
9.99999979e+01 1.75651607e-06 8.27947897e-07 1.04289116e-06
9.99999969e+01 9.07920759e-07 8.83138295e-07 9.99999971e+01]]
Trong các thành phần của lambda tìm được, có rất nhiều thành phần nhỏ tới 1e-6 hay 1e-7. Đây chính là các lambda_i = 0. Có rất nhiều phần tử xấp xỉ 9.99e+01, đây chính là các lambda_i bằng với C = 100, tương ứng với các support vectors không nằm trên margins, các sai số nhỏ xảy ra do tính toán. Các giá trị còn lại nằm giữa 0 và 100 là các giá trị tương ứng với các điểm nằm chính xác trên hai margins.
Tiếp theo, ta cần tính w và b theo công thức \((15)\) và \((16)\). Trước đó ta cần tìm tập hợp các điểm support và những điểm nằm trên margins.
S = np.where(l > 1e-5)[0] # support set
S2 = np.where(l < .999*C)[0]
M = [val for val in S if val in S2] # intersection of two lists
XT = X.T # we need each column to be one data point in this alg
VS = V[:, S]
lS = l[S]
yM = y[M]
XM = XT[:, M]
w_dual = VS.dot(lS).reshape(-1, 1)
b_dual = np.mean(yM.T - w_dual.T.dot(XM))
print(w_dual.T, b_dual)
Kết quả:
[[-1.87457279 -1.80695039]] 8.49672109815
Kết quả này gần giống với kết quả tìm được bằng sklearn.
5.1.4. Tìm nghiệm bằng giải bài toán không ràng buộc
Trong phương pháp này, chúng ta cần tính gradient của hàm mất mát. Như thường lệ, chúng ta cần kiểm chứng này bằng cách so sánh với numerical gradient.
Chú ý rằng trong phương pháp này, ta cần dùng tham số lam = 1/C.
X0_bar = np.vstack((X0.T, np.ones((1, N)))) # extended data
X1_bar = np.vstack((X1.T, np.ones((1, N)))) # extended data
Z = np.hstack((X0_bar, - X1_bar)) # as in (22)
lam = 1./C
def cost(w):
u = w.T.dot(Z) # as in (23)
return (np.sum(np.maximum(0, 1 - u)) + \
.5*lam*np.sum(w*w)) - .5*lam*w[-1]*w[-1] # no bias
def grad(w):
u = w.T.dot(Z) # as in (23)
H = np.where(u < 1)[1]
ZS = Z[:, H]
g = (-np.sum(ZS, axis = 1, keepdims = True) + lam*w)
g[-1] -= lam*w[-1] # no weight decay on bias
return g
eps = 1e-6
def num_grad(w):
g = np.zeros_like(w)
for i in xrange(len(w)):
wp = w.copy()
wm = w.copy()
wp[i] += eps
wm[i] -= eps
g[i] = (cost(wp) - cost(wm))/(2*eps)
return g
w0 = np.random.randn(X0_ext.shape[0], 1)
g1 = grad(w0)
g2 = num_grad(w0)
diff = np.linalg.norm(g1 - g2)
print('Gradient different: %f' %diff)
Gradient difference: 0.000000
Vì sự khác nhau giữa hai cách tính gradient là bằng 0, ta có thể yên tâm rằng gradient tính được là chính xác.
Sau khi chắc chắn rằng gradient tìm được đã chính xác, ta có thể bắt đầu làm Gradient Descent:
def grad_descent(w0, eta):
w = w0
it = 0
while it < 100000:
it = it + 1
g = grad(w)
w -= eta*g
if (it % 10000) == 1:
print('iter %d' %it + ' cost: %f' %cost(w))
if np.linalg.norm(g) < 1e-5:
break
return w
w0 = np.random.randn(X0_ext.shape[0], 1)
w = grad_descent(w0, 0.001)
w_hinge = w[:-1].reshape(-1, 1)
b_hinge = w[-1]
print(w_hinge.T, b_hinge)
Kết quả:
[[-1.8623959 -1.79532187]] [ 8.4493419]
Ta thấy rằng kết quả tìm được bằng ba cách là như nhau. Hình 5 dưới đây minh hoạ kết quả bằng ba cách tính:
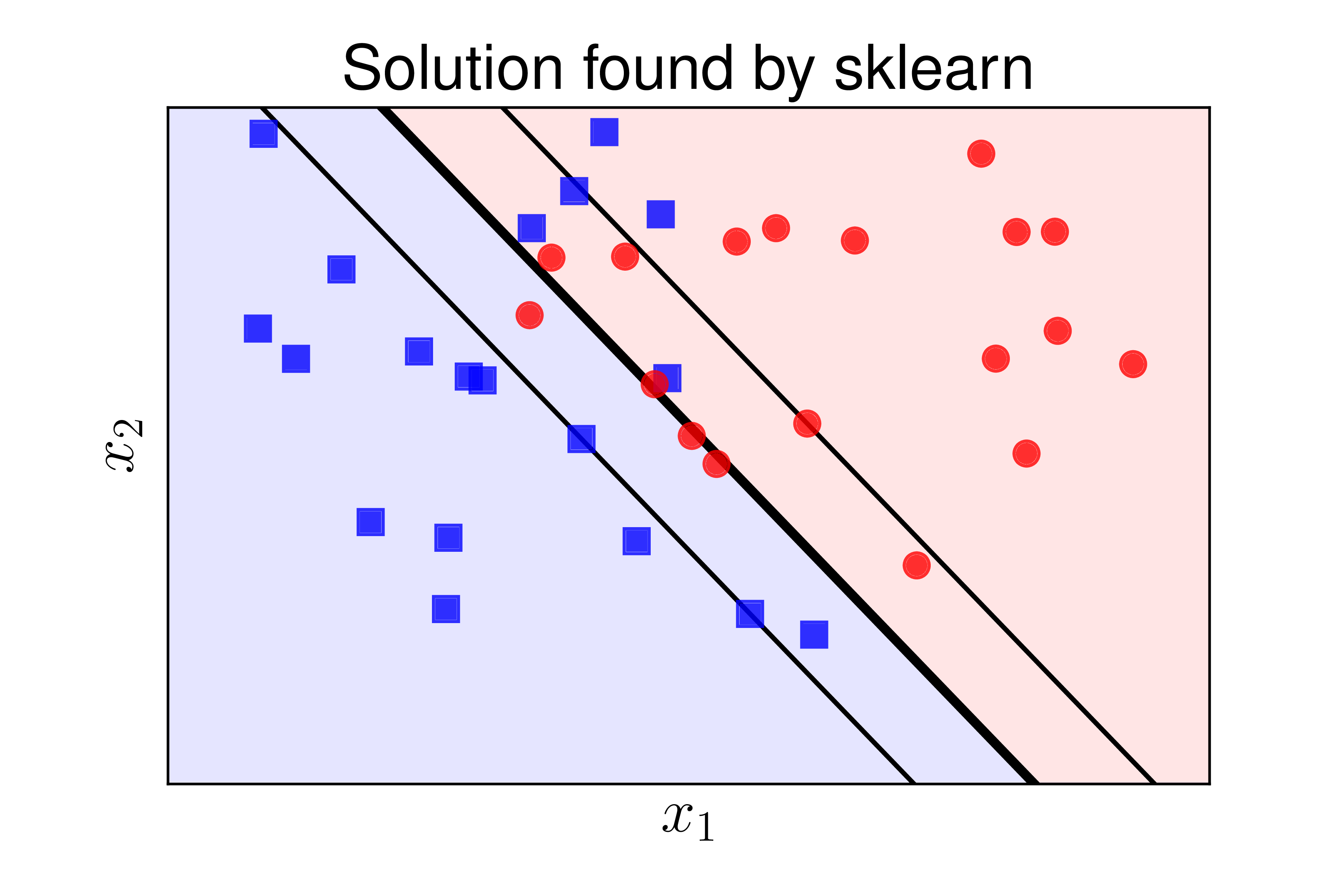
a) |
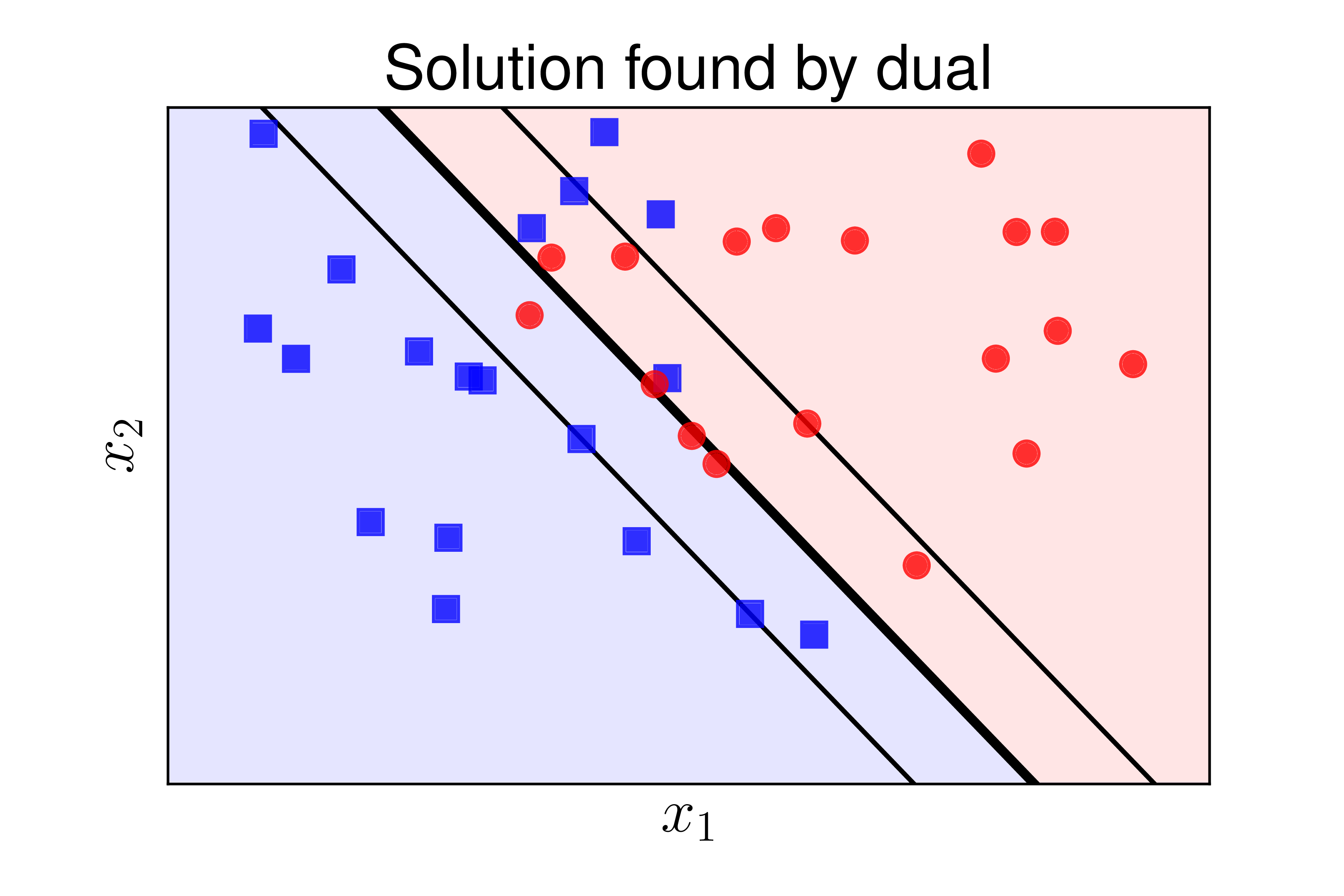
b) |
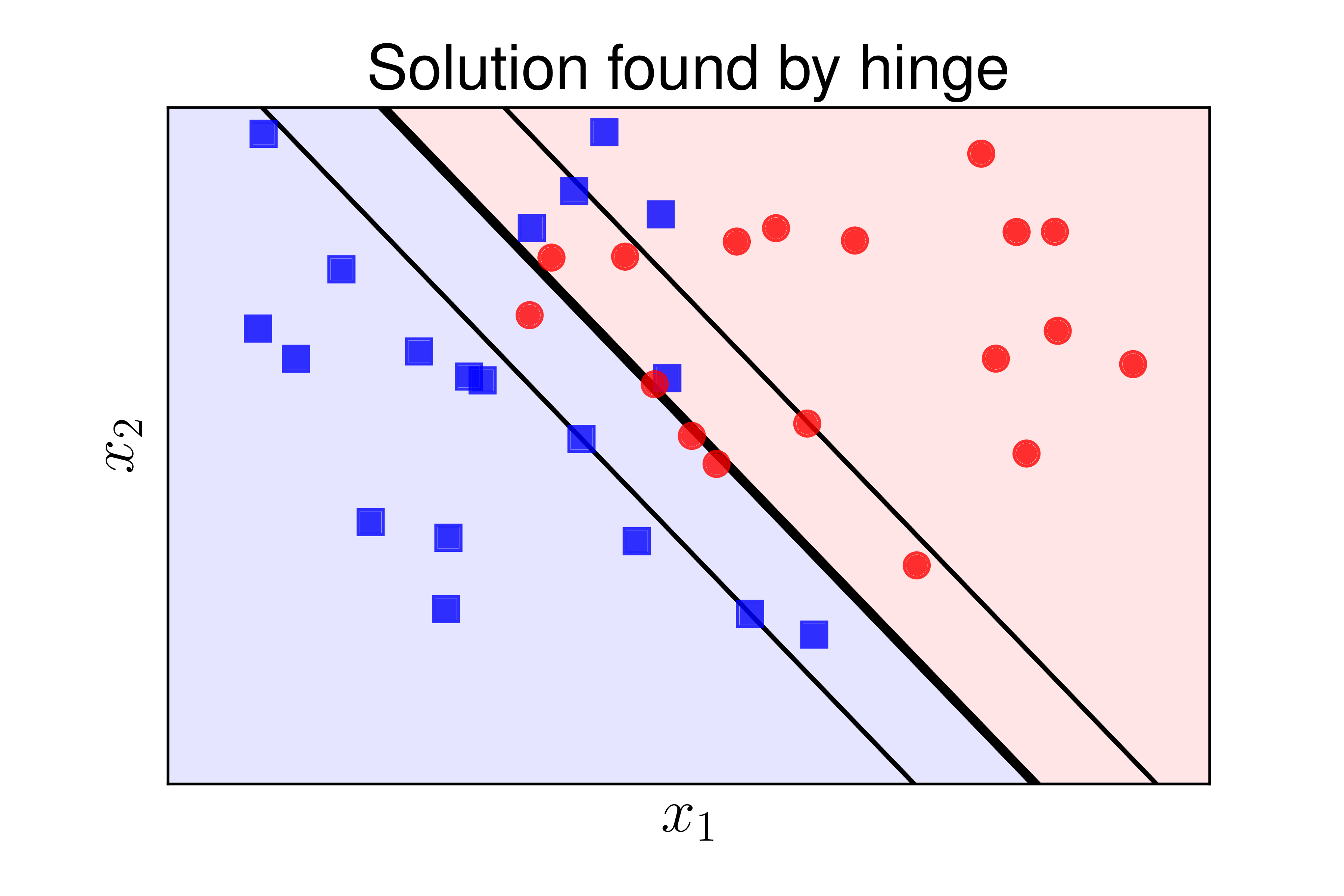
c) |
Hình 5: Các đường phân chia tìm được bởi ba cách khác nhau: a) hư viện sklearn, b) Bài toán đối ngẫu, c) Hàm hinge loss. Các kết quả tìm được là như nhau. |
Trong thực hành, phương pháp 1 chắc chắn được lựa chọn. Hai phương pháp còn lại được dùng làm cơ sở cho các phương pháp SVM nâng cao hơn trong các bài sau.
5.2. Ảnh hưởng của \(C\) lên nghiệm
Hình 6 dưới đây minh hoạ nghiệm tìm được cho bài toán phía trên nhưng với các giá trị \(C\) khác nhau. Nghiệm được tìm bằng thư viện sklearn.
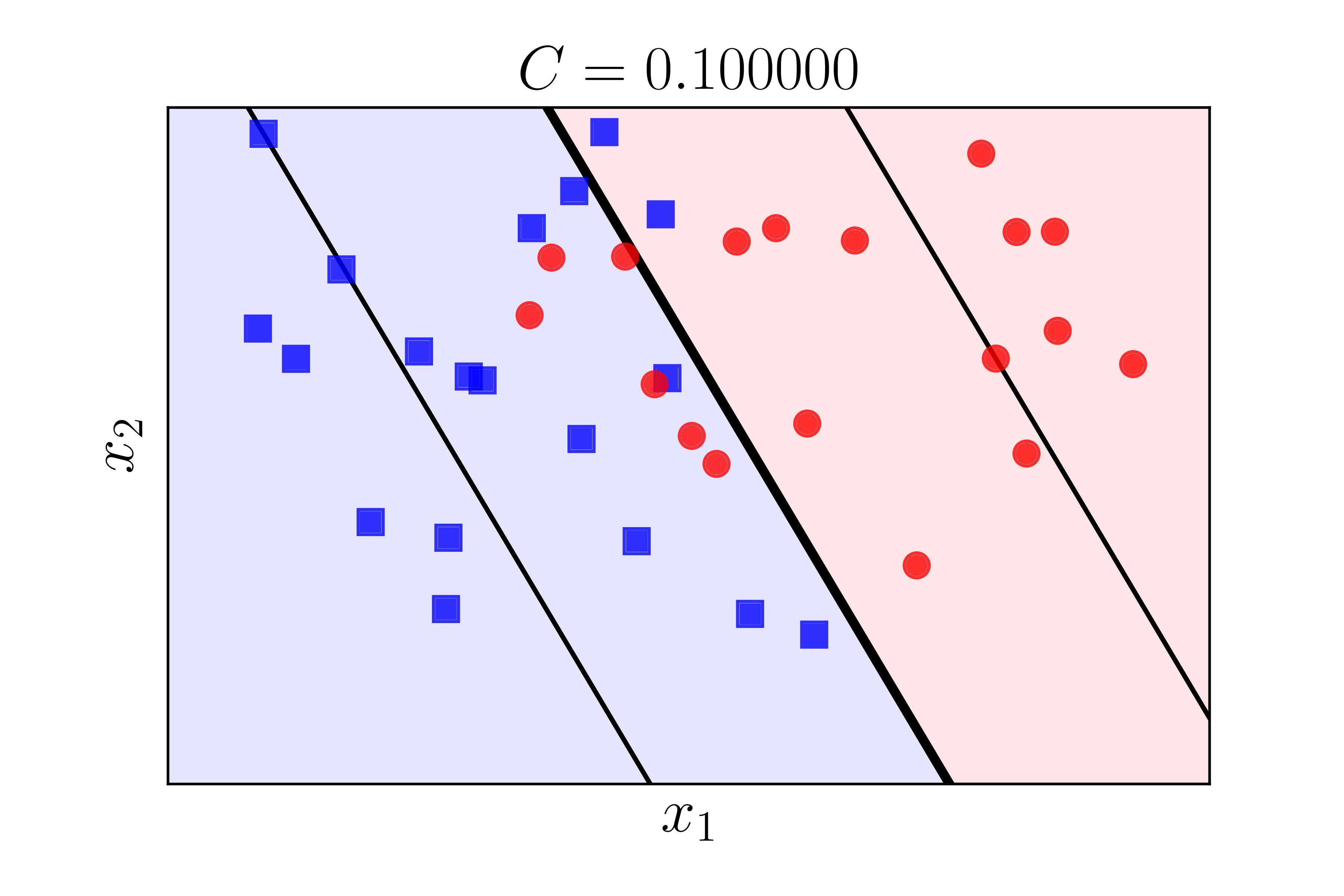
a) |
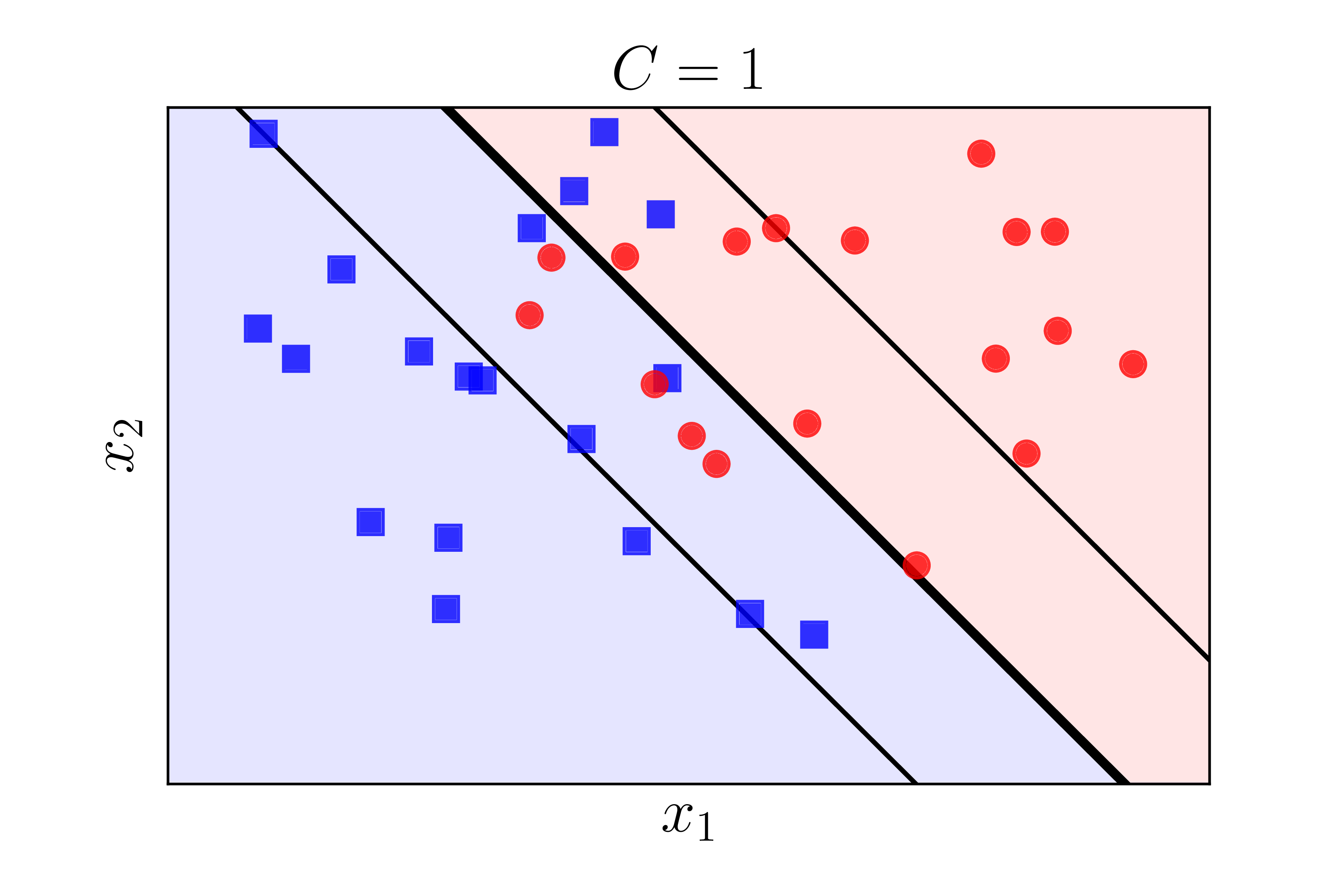
b) |
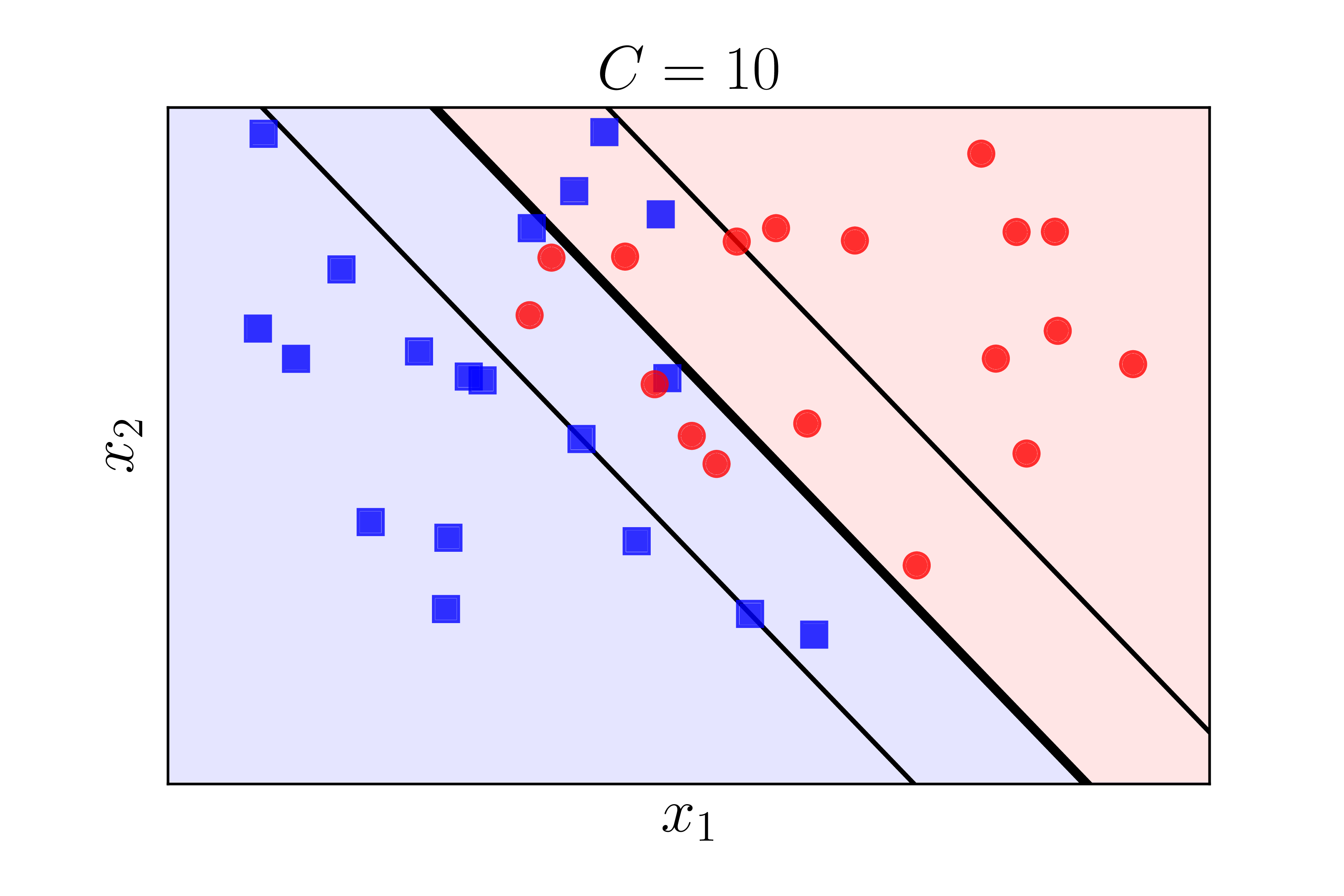
c) |

d) |
Chúng ta nhận thấy rằng khi (C) càng lớn thì biên càng nhỏ đi. Điều này phù hợp với suy luận của chúng ta ở Mục 2.
6. Tóm tắt và thảo luận
-
SVM thuần (Hard Margin SVM) hoạt động không hiệu quả khi có nhiễu ở gần biên hoặc thậm chí khi dữ liệu giữa hai lớp gần linearly separable. Soft Margin SVM có thể giúp khắc phục điểm này.
-
Trong Soft Margin SVM, chúng ta chấp nhận lỗi xảy ra ở một vài điểm dữ liệu. Lỗi này được xác định bằng khoảng cách từ điểm đó tới đường biên tương ứng. Bài toán tối ưu sẽ tối thiểu lỗi này bằng cách sử dụng thêm các biến được gọi là slack varaibles.
-
Để giải bài toán tối ưu, có hai cách khác nhau. Mỗi cách có những ưu, nhược điểm riêng, các bạn sẽ thấy trong các bài tới.
-
Cách thứ nhất là giải bài toán đối ngẫu. Bài toán đối ngẫu của Soft Margin SVM rất giống với bài toán đối ngẫu của Hard Margin SVM, chỉ khác ở ràng buộc chặn trên của các nhân tử Laggrange. Ràng buộc này còn được gọi là box costraint.
-
Cách thứ hai là đưa bài toán về dạng không ràng buộc dựa trên một hàm mới gọi là hinge loss. Với cách này, hàm mất mát thu được là một hàm lồi và có thể giải được khá dễ dàng và hiệu quả bằng các phương pháp Gradient Descent.
-
Trong Soft Margin SVM, có một hằng số phải được chọn, đó là \(C\). Hướng tiếp cận này còn được gọi là C-SVM. Ngoài ra, còn có một hướng tiếp cận khác cũng hay được sử dụng, gọi là \(\nu\)-SVM, bạn đọc có thể đọc thêm tại đây.
7. Tài liệu tham khảo
[1] Bishop, Christopher M. “Pattern recognition and Machine Learning.”, Springer (2006). (book)
[2] Duda, Richard O., Peter E. Hart, and David G. Stork. Pattern classification. John Wiley & Sons, 2012.
[3] sklearn.svm.SVC
[4] LIBSVM – A Library for Support Vector Machines
[5] Bennett, K. P. (1992). “Robust linear programming discrimination of two linearly separable sets”. Optimization Methods and Software 1, 23–34.
[6] Sch¨olkopf, B., A. Smola, R. C.Williamson, and P. L. Bartlett (2000). “New support vector algorithms”. Neural Computation 12(5), 1207–1245
[7] Rosasco, L.; De Vito, E. D.; Caponnetto, A.; Piana, M.; Verri, A. (2004). “Are Loss Functions All the Same?”. Neural Computation. 16 (5): 1063–1076