Pandas profiling¶
Pandas-profiling là một công cụ hữu hiệu cho việc làm EDA cơ bản. Nó giúp bạn tạo ra một trang html có thể lưu trữ và truyền tải một cách nhanh gọn. Pandas-profiling giúp bạn có cái nhìn toàn cảnh về bộ dữ liệu, phân phối của từng cột cũng như độ tương quan giữa các cột. Sử dụng công cụ này sẽ giúp bạn giảm rất nhiều thời gian EDA.
Dưới đây là một đoạn code ngắn giúp làm EDA cho bộ dữ liệu Titanic sử dụng pandas-profiling.
%%capture
import pandas as pd
from pandas_profiling import ProfileReport
df_train = pd.read_csv("../data/titanic/train.csv")
profile = ProfileReport(
df_train, title="Pandas Profiling Report for Titanic train dataset"
)
profile.to_file("../data_to_web/titanic_train_profiling.html")
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-1-4a5d4d3e7c89> in <module>
2 from pandas_profiling import ProfileReport
3
----> 4 df_train = pd.read_csv("../data/titanic/train.csv")
5
6 profile = ProfileReport(
~/w/tabml_book/tabml_book_env/lib/python3.8/site-packages/pandas/io/parsers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
686 )
687
--> 688 return _read(filepath_or_buffer, kwds)
689
690
~/w/tabml_book/tabml_book_env/lib/python3.8/site-packages/pandas/io/parsers.py in _read(filepath_or_buffer, kwds)
452
453 # Create the parser.
--> 454 parser = TextFileReader(fp_or_buf, **kwds)
455
456 if chunksize or iterator:
~/w/tabml_book/tabml_book_env/lib/python3.8/site-packages/pandas/io/parsers.py in __init__(self, f, engine, **kwds)
946 self.options["has_index_names"] = kwds["has_index_names"]
947
--> 948 self._make_engine(self.engine)
949
950 def close(self):
~/w/tabml_book/tabml_book_env/lib/python3.8/site-packages/pandas/io/parsers.py in _make_engine(self, engine)
1178 def _make_engine(self, engine="c"):
1179 if engine == "c":
-> 1180 self._engine = CParserWrapper(self.f, **self.options)
1181 else:
1182 if engine == "python":
~/w/tabml_book/tabml_book_env/lib/python3.8/site-packages/pandas/io/parsers.py in __init__(self, src, **kwds)
2008 kwds["usecols"] = self.usecols
2009
-> 2010 self._reader = parsers.TextReader(src, **kwds)
2011 self.unnamed_cols = self._reader.unnamed_cols
2012
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source()
FileNotFoundError: [Errno 2] No such file or directory: '../data/titanic/train.csv'
Bản kết quả có thể được tìm thấy tại đây.
Dưới đây là một số biểu đồ đáng chú ý.
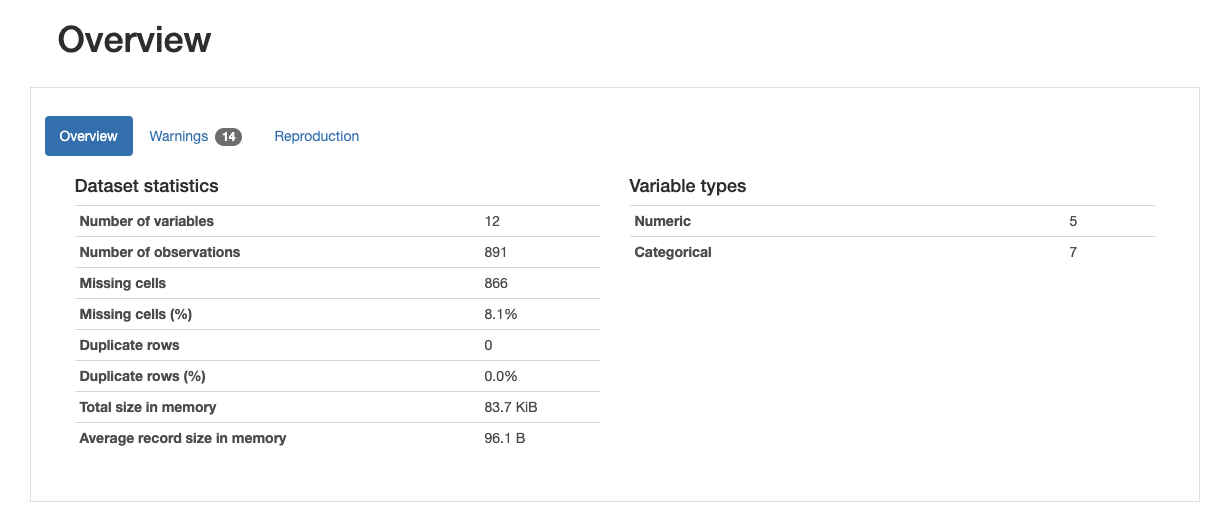
Fig. 2 Titanic Overview¶
Fig. 2 thể hiện khái quát những thống kê về bộ dữ liệu. Có nhiều thông tin hữu ích như số lượng trường dữ liệu (Number of variables), số mẫu dữ liệu (Number of observations), số giá trị bị khuyết (Missing cells), số mẫu dự liệu bị lặp (Duplicate rows), số cột dạng hạng mục (Categorical) và số cột dạng số (Numeric).
Note
Lưu ý rằng khi không chỉ định rõ kiểu dữ liệu khi đọc file csv, pandas tự suy ra kiểu dựa trên giá trị của dữ liệu trong cột. Ở đây, PassengerID và PClass cũng được tính là dạng số vì chúng mang những giá trị có thể chuyển đổi ra số. Nếu bạn muốn chỉ định rõ, bạn cần sử dụng tham số dtype.
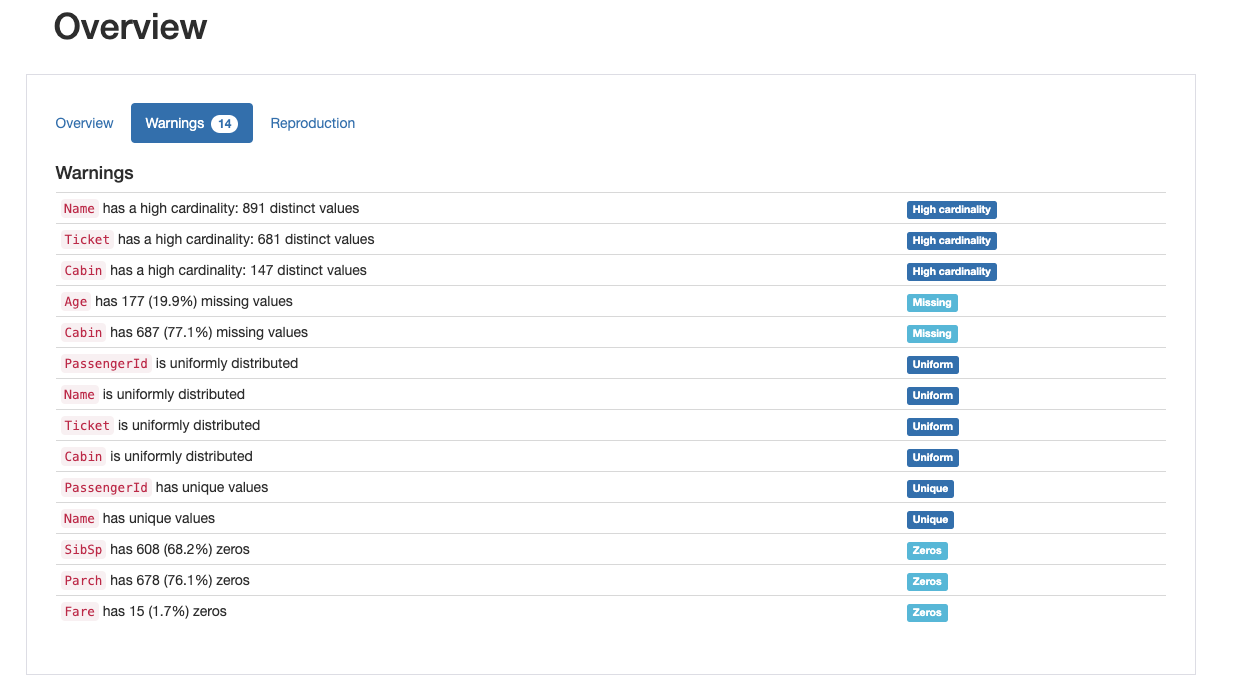
Fig. 3 Overview Warnings¶
Fig. 3 đưa ra những cảnh báo khái quát về những trường dữ liệu có chứa giá trị khuyết (Missing), có số lượng hạng mục cao (High cardinality), có nhiều giá trị bằng 0 (Zeros) cũng như chỉ chứa những giá trị riêng biệt (Unique).
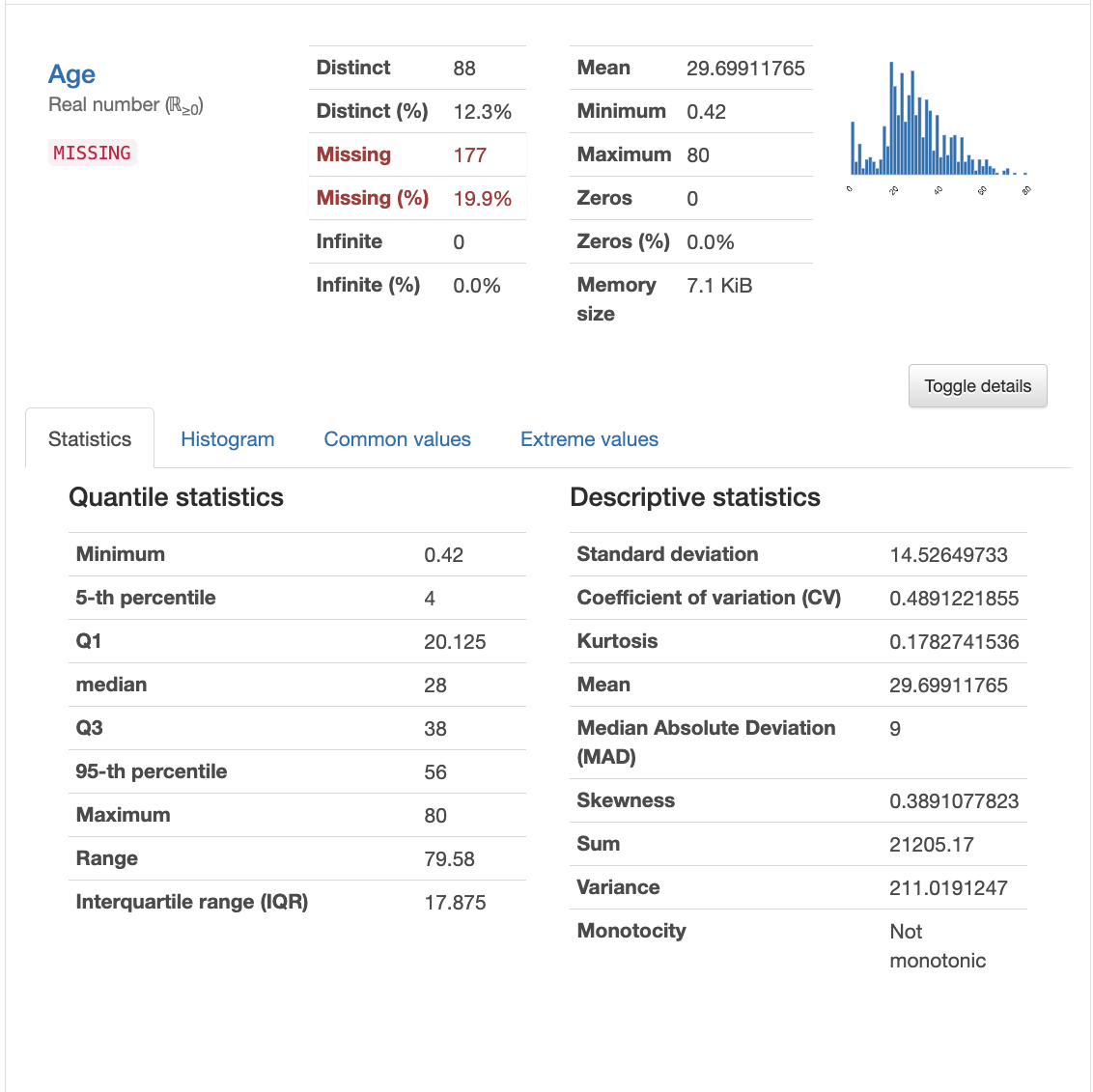
Fig. 4 Thống kê cột Age¶
Phần tiếp theo của bảng kết quả mang lại nhiều thông tin về phân phối của từng cột dữ liệu. Fig. 4 mô tả các thống kê về cột dữ liệu Age. Rất nhiều thông tin bạn có thể tìm thấy ở đây.
Ở gần dưới cùng có mục “Correlations”. Mục này minh họa độ tương quan giữa các cột dự liệu. Có bốn phương pháp tính độ tương quan giữa các cột với thông tin có thể tìm thấy tại nút “Toggle correlation description”. Kết quả của mỗi phương pháp được thể hiện ở ma trận tương quan trong mỗi tab.
Các tab “Pearson’s, Spearman’s, Kendall’s” thể hiện sự tương quan giữa các cột dạng số. Tab “Phik” thể hiện cho tất cả cả cột và tab “Cramer’s” dành cho các cột dạng hạng mục.
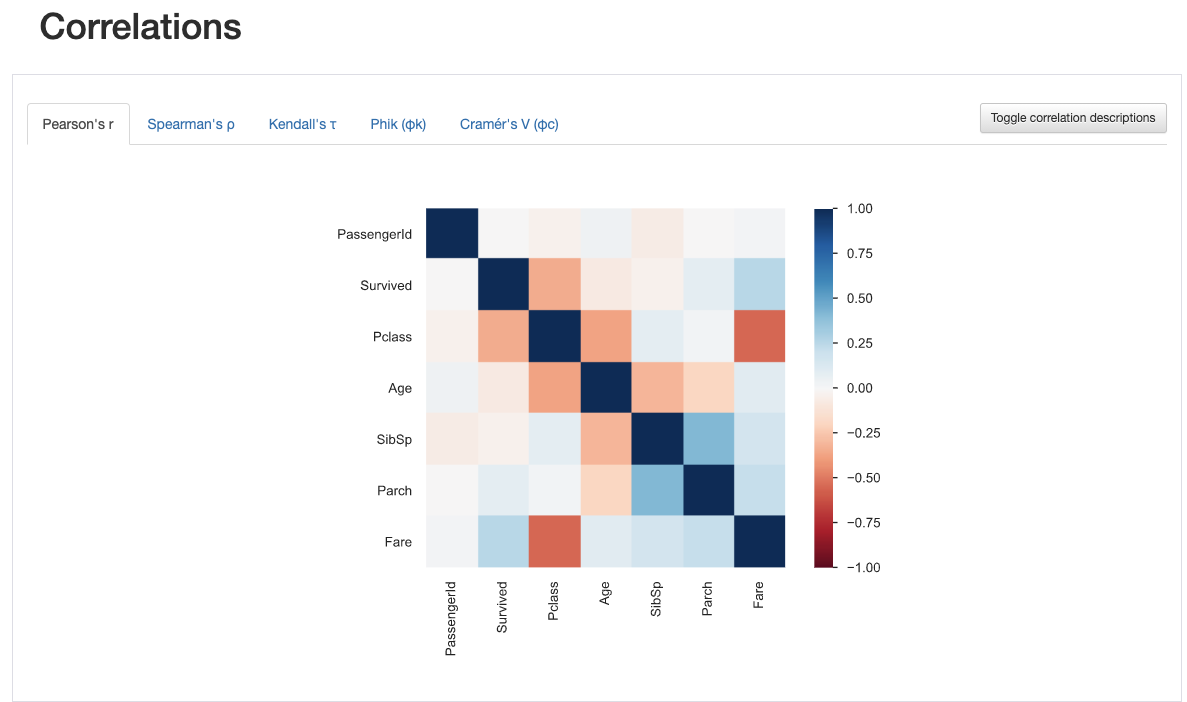
Fig. 5 Ma trận tương quan Pearson’s¶
Fig. 5 cho ta thấy rằng cột “Pclass” và cột “Fare” có tương quan ngược với hệ số tương quan màu cam đậm, tức là “Pclass” càng nhỏ thì “Fare” càng lớn và ngược lại. Điều này dễ hiểu vì hạng ghế và giá vé có quan hệ chặt chẽ với nhau.
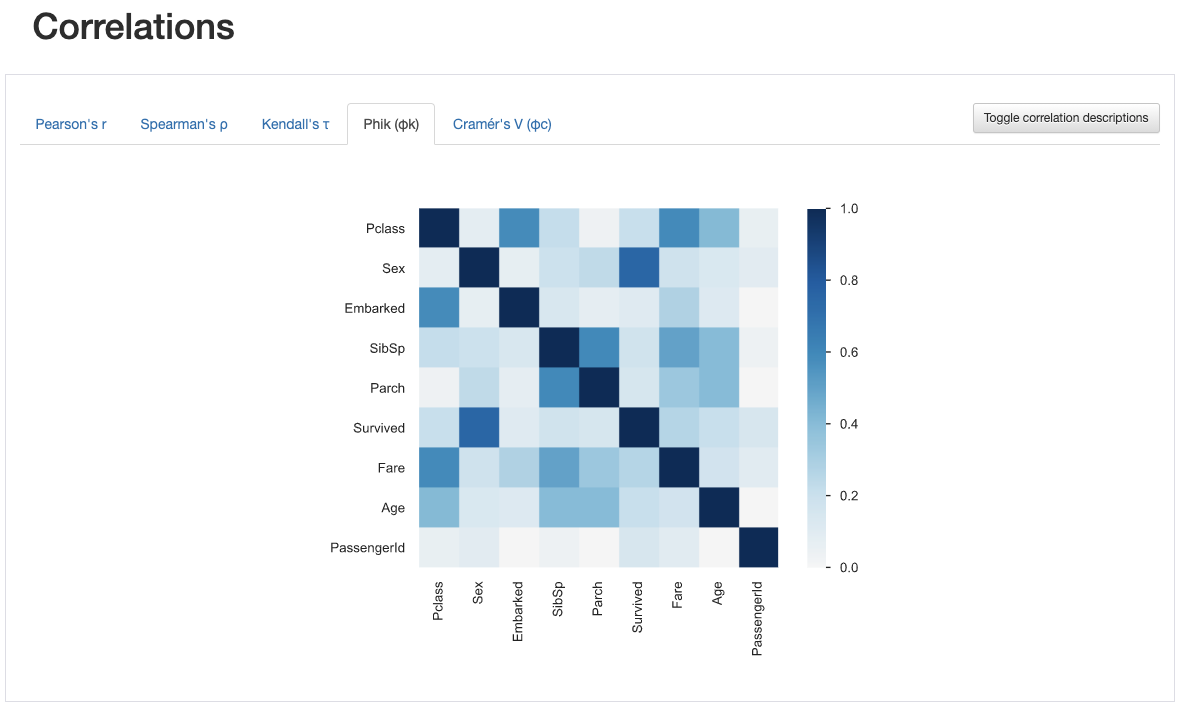
Fig. 6 Ma trận tương quan Phik¶
Cuối cùng, mở tab “Phik” như trong Fig. 6 để tìm độ tương quan giữa các cột và cột nhãn “Survived”, ta thấy rằng cột “Sex” có màu đậm nhất, tức có độ tương quan cao nhất. Điều này chỉ ra rằng các đặc trưng liên quan đến giới tính sẽ cho kết quả tốt. Đây có thể là lý do mà ban tổ chức cho một file nộp bài mẫu với kết quả dự đoán dựa trên giới tính của hành khách.
Bạn đọc có thể xem thêm kết quả của bộ dữ liệu California Housing tại đây.
%%capture
import pandas as pd
from pandas_profiling import ProfileReport
df_housing = pd.read_csv("../data/california_housing/housing.csv")
profile = ProfileReport(
df_housing, title="Pandas Profiling Report for California Housing train dataset"
)
profile.to_file("../data_to_web/california_housing_profiling.html")
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-2-2b16053be3a5> in <module>
2 from pandas_profiling import ProfileReport
3
----> 4 df_housing = pd.read_csv("../data/california_housing/housing.csv")
5
6 profile = ProfileReport(
~/w/tabml_book/tabml_book_env/lib/python3.8/site-packages/pandas/io/parsers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
686 )
687
--> 688 return _read(filepath_or_buffer, kwds)
689
690
~/w/tabml_book/tabml_book_env/lib/python3.8/site-packages/pandas/io/parsers.py in _read(filepath_or_buffer, kwds)
452
453 # Create the parser.
--> 454 parser = TextFileReader(fp_or_buf, **kwds)
455
456 if chunksize or iterator:
~/w/tabml_book/tabml_book_env/lib/python3.8/site-packages/pandas/io/parsers.py in __init__(self, f, engine, **kwds)
946 self.options["has_index_names"] = kwds["has_index_names"]
947
--> 948 self._make_engine(self.engine)
949
950 def close(self):
~/w/tabml_book/tabml_book_env/lib/python3.8/site-packages/pandas/io/parsers.py in _make_engine(self, engine)
1178 def _make_engine(self, engine="c"):
1179 if engine == "c":
-> 1180 self._engine = CParserWrapper(self.f, **self.options)
1181 else:
1182 if engine == "python":
~/w/tabml_book/tabml_book_env/lib/python3.8/site-packages/pandas/io/parsers.py in __init__(self, src, **kwds)
2008 kwds["usecols"] = self.usecols
2009
-> 2010 self._reader = parsers.TextReader(src, **kwds)
2011 self.unnamed_cols = self._reader.unnamed_cols
2012
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source()
FileNotFoundError: [Errno 2] No such file or directory: '../data/california_housing/housing.csv'
Các ma trận tương quan này rất hữu ích trong việc chọn ra các cột quan trọng trong việc xây dựng mô hình đầu tiên cho mỗi bài toán. Bạn có thể xem tất cả các tab để chọn ra những cột đó. Nên nhớ cần kiểm tra xem có hiện tượng rò rỉ dữ liệu (data leakage) hay không.
Trong mục tiếp theo, chúng ta sẽ tìm hiểu các kỹ thuật làm sạch dữ liệu và tạo đặc trưng trước khi xây dựng mô hình.