Embedding¶
Giới thiệu¶
Embedding là một kỹ thuật đưa một vector có số chiều lớn, thường ở dạng thưa, về một vector có số chiều nhỏ, thường ở dạng dày đặc. Phương pháp này đặc biệt hữu ích với những đặc trưng hạng mục có số phần tử lớn ở đó phương pháp chủ yếu để biểu diễn mỗi giá trị thường là một vector dạng one-hot. Một cách lý tưởng, các giá trị có ý nghĩa tương tự nhau nằm gần nhau trong không gian embedding.
Ví dụ nổi bật nhất là biểu diễn các từ trong một bộ từ điển dưới dạng số. Khi từ điển có hàng triệu từ, biểu diễn các từ dưới dạng one-hot vector dẫn tới số chiều vô cùng lớn. Hơn nữa, các từ này sẽ có khoảng cách đều nhau tới mọi từ khác (căn bậc hai của 2), dẫn đến việc thiếu thông tin giá trị cho việc huấn luyện mô hình machine learning. Chẳng hạn, một cách biểu diễn tốt các từ tiếng Việt cần mô tả tốt sự liên quan giữa cặp từ (vua, hoàng hậu) và (chồng, vợ) vì chúng có ý nghĩa gần nhau.
Biểu diễn toán học¶
Giả sử một từ điển nào đó chỉ có sáu giá trị (Hà Nội, Hải Phòng, Tp HCM, Bình Dương, Lào Cai, Sóc Trăng). Fig. 7 thể hiện cách biểu diễn của các giá trị này trong không gian one-hot và không gian embedding hai chiều.
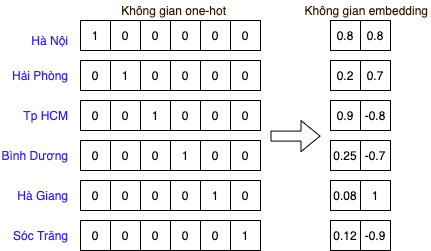
Fig. 7 Biểu diễn các giá trị hạng mục dưới dạng one-hot vector và embedding¶
Ở đây, các giá trị trong không gian embedding được lấy ví dụ bằng tay với chiều thứ nhất thể hiện dân số và chiều thứ hai thể hiện vĩ độ đã chuẩn hóa của mỗi giá trị. Vị trí của mỗi vector embedding trong không gian hai chiều được minh hoạ trong Fig. 8. Trong không gian này, Hà Nội, Hải Phòng và Hà Giang gần nhau về vị trí địa lý. Nếu chúng ta có một bài toán nào đó mà dân số có thể là một đặc trưng tốt, ta chỉ cần co trục tung và giãn trục hoành là có thể mang những tỉnh thành có dân số giống nhau gần với nhau hơn.

Fig. 8 Biểu diễn các vector embedding trong không gian¶
Với một từ điển bất kỳ với \(N\) từ \((w_1, w_2, \dots, w_{N})\). Giả sử số chiều của không gian embedding là \(d\), ta có thể biểu diễn toàn bộ các embedding cho \(N\) từ này dưới dạng một ma trận \(\mathbf{E} \in \mathbb{R}^{N\times k}\) với hàng thứ \(i\) là biểu diễn embedding cho từ \(w_{i}\).
Nếu vector \(\mathbf{o}_i \in \mathbb{R}^{N \times 1}\) là biểu diễn one-hot của từ \(w_i\), ta có ngay \(\mathbf{e} = \mathbf{o}_i^T\mathbf{E} \in \mathbb{R}^{1 \times k}\) là biểu diễn của từ đó trong không gian embedding.
Tạo embedding như thế nào?¶
Cách biểu diễn các tỉnh thành trong ví dụ trên đây chỉ là một ví dụ minh họa khi chúng ta có thể định nghĩa các trục một cách cụ thể dựa vào kiến thức nhất định đã có về dữ liệu. Cách làm này không khả thi với những dữ liệu vô cùng nhiều chiều và không có những ý nghĩa từng trục rõ ràng như trên. Việc tìm ra ma trận \(\mathbf{E}\) cần thông qua một quá trình “học” dựa trên mối quan hệ vốn có của dữ liệu.
Ta có thể thấy rằng ma trận \(\mathbf{E}\) có thể được coi là một ma trận trọng số của một tầng tuyến tính trong một mạng neural nhân tạo như trong Fig. 9.
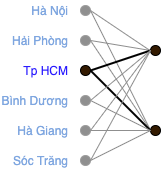
Fig. 9 Ma trận embedding có thể coi là một ma trận trọng số trong một mạng neural nhân tạo.¶
Như vậy, ma trận này cũng có thể được xây dựng bằng cách đặt nó vào một mạng neural với một hàm mất mát nào đó. Trong Tensorflow (phiên bản 2.5), tầng embedding có thể được khai báo bởi tf.keras.layers.Embedding. Trong Pytorch 1.8.1, ta có thể dùng torch.nn.Embedding. Trong cuốn sách này, chúng ta sẽ có một ví dụ về việc xây dựng embedding cho các sản phẩm dựa trên nền tảng Pytorch.
Embedding có thể được học trong cả một bài toán tổng thể hoặc học riêng rẽ khác trước khi đưa vào một bài toán cụ thể. Embedding thu được có thể được dùng như một đặc trưng nhiều chiều và có thể trong các mô hình không phải học sâu.
Word2vec là một trong những phương pháp tiên phong về việc xây dựng embedding cho các từ dựa trên một mạng học sâu. Các vector embedding này được học chỉ dựa trên thứ tự các từ trong câu của một bộ dữ liệu lớn mà không cần biết ý nghĩa cụ thể của từng câu hay mối quan hệ đặc biệt nào giữa chúng. Các vector embedding này có thể được dùng để tạo các biểu diễn cho một câu hay một văn bản để giải quyết các bài toán khác.
Độ tương tự giữa hai embedding¶
Quay lại với mục đích chính của việc tạo embedding là đưa các giá trị hạng mục về một không gian số sao cho embedding của những giá trị tương tự nằm gần nhau trong không gian. Vậy khoảng cách này thường được tính như thế nào.
Có ba phép đo thường được sử dụng để tính khoảng cách giữa hai embedding là khoảng cách Euclid, tích vô hướng của hai vector, và độ tương tự cosine.
Khoảng cách Euclid¶
Công thức tính khoảng cách Euclid giữa hai vector embedding
Khoảng cách này không âm và càng nhỏ thì hai vector embedding càng gần nhau. Ở đây, \(\|\mathbf{e}\| = \sqrt{\sum_{i=1}^d e_i^2}\) là độ lớn của vector \(\mathbf{e} \in \mathbb{R}^d\).
Để giảm sự phức tạp khi khai căn, bình phương khoảng cách Euclid thường được sử dụng. Việc lấy bình phương không ảnh hưởng tới việc so sánh khoảng cách vì bình phương là một hàm đồng biến.
Tích vô hướng¶
Công thức tính độ tương tự theo tích vô hướng (dot product) giữa hai vector embedding:
Tính vô hướng giữa hai vector càng cao thể hiện các embedding càng giống nhau. Giá trị này lớn nếu góc giữa hai vector nhỏ và các vector này có độ dài lớn.
Tương tự cosine¶
Tương tự cosin cũng được sử dụng để đo độ tương tự giữa hai vector:
Góc giữa hai vector càng nhỏ thì độ tương tự cosin càng cao. Độ tương tự cosin nhỏ nhất bằng -1 nếu hai vector này trái dấu nhau.
Trong ba độ đo trên đây, tích vô hướng có công thức đơn giản nhất và thường được sử dụng trong các bài toán quy mô lớn. Tương tự cosine không quan tâm tới độ lớn của hai vector mà chỉ xét tới góc giữa chúng, phép đo này phù hợp với các bài toán yêu cầu tìm sự trái ngược giữa các giá trị hạng mục. Nếu các vector embedding có cùng độ dài, ba phép đo này có ý nghĩa như nhau.
Tìm embedding gần nhất¶
Embedding được dùng nhiều trong bài toán tìm kiếm các điểm trong cơ sở dữ liệu (item embeddings) gần nhất với một embedding truy vấn (query embedding) nào đó.
Giả sử \(\mathbf{E} \in \mathbb{R}^{N\times d}\) và \(\mathbf{q} \in \mathbb{R}^d\) lần lượt là ma trận embedding của các giá trị trong cơ sở dữ liệu và vector truy vấn.
Với khoảng cách Euclid, khoảng cách giữa \(\mathbf{q}\) và một embedding \(\mathbf{e}_i\) trong \(\mathbf{E}\) được tính bởi:
Chỉ số của embedding gần \(\mathbf{q}\) được tính bởi:
Với độ tương tự tích vô hướng, chỉ số của embedding gần \(\mathbf{q}\) được tính như sau:
Với độ tương tự cosine, chỉ số của embedding gần \(\mathbf{q}\) được tính bởi:
Bài toán đi tìm những điểm trong cơ sở dữ liệu có embedding gần với một embedding cho trước có thể được triển khai như sau:
import numpy as np
class NearestNeighbor:
"""Class supporting finding neareast embeddings of a query embeddings.
Attrubutes:
item_embeddings: a matrix of shape [N, k], such that row i is the embedding of
item i.
measure: One of ("cosine", "dot", "l2") specifying the similarity measure to be used
"""
def __init__(self, item_embeddings, measure="cosine"):
assert measure in ("dot", "cosine", "l2")
self.measure = measure
self.item_embeddings = item_embeddings
if self.measure == "cosine":
# nomalize embeding
self.item_embeddings = item_embeddings / np.linalg.norm(
item_embeddings, axis=1, keepdims=True
)
elif self.measure == "l2":
self.squared_item_embedding = (item_embeddings ** 2).sum(axis=1)
def find_nearest_neighbors(self, query_embedding, k=10):
"""Returns indices of k nearest neighbors"""
# Denote q as query_emebdding vector, V as item_embeddings matrix.
dot_products = query_embedding.dot(self.item_embeddings.T)
if self.measure in ("dot", "cosine"):
scores = dot_products
elif self.measure == "l2":
# ignore squared_query_embedding since it's the same for all item_embeddings
scores = -(self.squared_item_embedding - 2 * dot_products)
return (-scores).argsort()[:k]
def test_nearest_neighbors():
query = np.array([1, 2])
items = np.array(
[
[1, 2.2], # neareast in l2
[10, 21], # neareast in dot product similarity
[2, 4], # nearest in cosine similarity
]
)
assert NearestNeighbor(items, "l2").find_nearest_neighbors(query, 1)[0] == 0
assert NearestNeighbor(items, "dot").find_nearest_neighbors(query, 1)[0] == 1
assert NearestNeighbor(items, "cosine").find_nearest_neighbors(query, 1)[0] == 2
print("All tests passed")
test_nearest_neighbors()
All tests passed
Ở các phần sau của cuốn sách, chúng ta sẽ trực tiếp sử dụng module tabml.utils.embedding cho các tác vụ liên quan đến embedding.