Word2vec¶
Giới thiệu¶
Word2vec là một mô hình đơn giản và nổi tiếng giúp tạo ra các biểu diễn embedding của từ trong một không gian có số chiều thấp hơn nhiều lần so với số từ trong từ điển. Ý tưởng của word2vec đã được sử dụng trong nhiều bài toán với dữ liệu khác xa với dữ liệu ngôn ngữ. Trong cuốn sách này, ý tưởng của word2vec sẽ được trình bày và một ví dụ minh họa ứng dụng word2vec để tạo một mô hình product2vec giúp tạo ra các embedding khác nhau cho thực phẩm và đồ gia dụng.
Ý tưởng cơ bản của word2vec có thể được gói gọn trong các ý sau:
Hai từ xuất hiện trong những văn cảnh giống nhau thường có ý nghĩa gần với nhau.
Ta có thể đoán được một từ nếu biết các từ xung quanh nó trong câu. Ví dụ, với câu “Hà Nội là … của Việt Nam” thì từ trong dấu ba chấm khả năng cao là “thủ đô”. Với câu hoàn chỉnh “Hà Nội là thủ đô của Việt Nam”, mô hình word2vec sẽ xây dựng ra embeding của các từ sao cho xác suất để từ trong dấu ba chấm là “thủ đô” là cao nhất.
Một vài định nghĩa¶
Trong ví dụ trên đây, từ “thủ đô” đang được xét và được gọi là target word hay từ đích. Những từ xung quanh nó được gọi là context words hay từ ngữ cảnh. Với mỗi từ đích trong một câu của cơ sở dữ liệu, các từ ngữ cảnh được định nghĩa là các từ trong cùng câu có vị trí cách từ đích một khoảng không quá \(C/2\) với \(C\) là một số tự nhiên dương. Như vậy, với mỗi từ đích, ta sẽ có một bộ không quá \(C\) từ ngữ cảnh.
Xét ví dụ sau đây với câu tiếng Anh: “The quick brown fox jump over the lazy dog” với \(C = 4\).
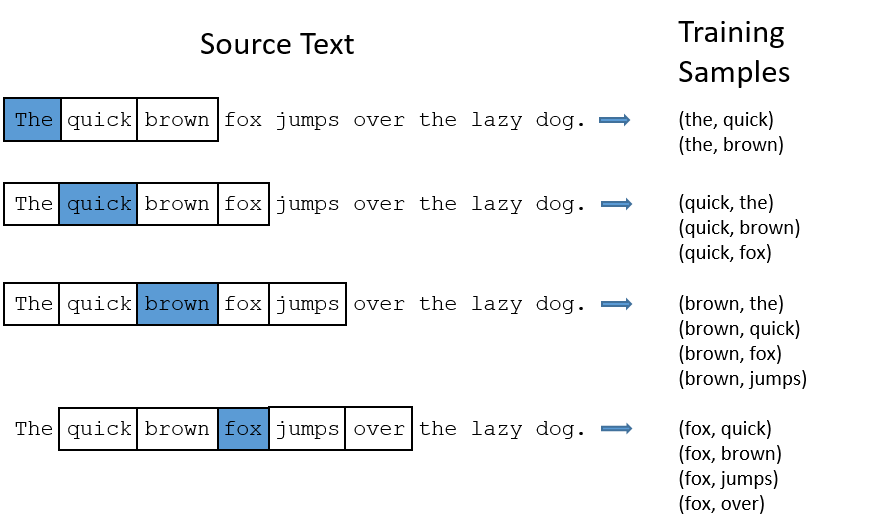
Fig. 10 Ví dụ về các cặp (từ đích, từ ngữ cảnh) (Nguồn: Word2Vec Tutorial - The Skip-Gram Model).¶
Khi “the” là từ đích, ta có cặp dữ liệu huấn luyện là (the, quick) và (the, brown). Khi “brown” là từ đích, ta có cặp dữ liệu huấn luyện là (brown, the), (brown, quick), (brown, fox) và (brown, jumps).
Word2vec định nghĩa hai embedding vector cùng chiều cho mỗi từ \(w\) trong từ điển. Khi nó là một từ đích, embedding vector của nó là \(\mathbf{u}\); khi nó là một từ ngữ cảnh, embedding của nó là \(\mathbf{v}\). Sở dĩ ta cần hai embedding khác nhau vì ý nghĩa của từ đó khi nó là từ đích và từ ngữ cảnh là khác nhau. Tương ứng với đó, ta có hai ma trận embedding \(\mathbf{U}\) và \(\mathbf{V}\) cho các từ đích và các từ ngữ cảnh.
Có hai cách khác nhau xây dựng mô hình word2vec:
Skip-gram: Dự đoán những từ ngữ cảnh nếu biết trước từ đích.
CBOW (Continuous Bag of Words): Dựa vào những từ ngữ cảnh để dự đoán từ đích.
Mỗi cách có những ưu nhược điểm khác nhau và áp dụng với những loại dữ liệu khác nhau.
Skip-gram¶
Xây dựng hàm mất mát¶
Mọi tính toán trong mục này được xây dựng xung quanh một từ ngữ cảnh. Hàm mất mát tổng cộng sẽ là tổng của hàm mất mát tại mỗi từ ngữ cảnh. Việc tối ưu hàm mất mát có thể được thực hiện thông qua Gradient Descent trên từng từ ngữ cảnh hoặc một batch các từ ngữ cảnh.
Xét ví dụ bên trên với từ đích là “fox” và các từ ngữ cảnh là “quick”, “brown”, “jumps” và “over”. Việc dự đoán xác suất xảy ra các từ ngữ cảnh khi biết từ đích được mô hình hóa bởi:
Ta có thể giả sử rằng sự xuất hiện của một từ ngữ cảnh khi biết từ đích độc lập với các từ ngữ cảnh khác để xấp xỉ xác suất trên đây bởi:
Note
Giả sử về việc các từ ngữ cảnh xuất hiện độc lập với nhau xunh quanh từ đích mâu thuẫn với ý tưởng của word2vec là những từ trong cùng văn cảnh có liên quan đến nhau. Tuy nhiên, giả thiết này giúp mô hình và độ phức tạp giảm đi rất nhiều trong khi vẫn mang lại kết quả khả quan.
Giả sử từ đích có chỉ số \(t\) trong từ điển \(\mathcal{V}\) và tập hợp các chỉ số của các từ ngữ cảnh tương ứng là \(\mathcal{C}_t\). Số lượng phần tử của \(\mathcal{C}_t\) dao động từ \(C/2\) (nếu \(w_t\) đứng đầu hoặc cuối câu) tới \(C\) (nếu \(w_t\) đứng ở giữa câu và có đủ \(C/2\) từ ngữ cảnh ở mỗi phía).
Từ dữ liệu đã có, ta cần một mô hình sao cho xác suất dưới đây càng lớn càng tốt với mỗi từ ngữ cảnh \(w_t\):
Để tránh các sai số tính toán khi nhân các số nhỏ hơn 1 với nhau, bài toán tối ưu này thường được đưa về bài toán tối thiểu đối số của log (thường được gọi là negative log loss):
Xác suất có điều kiện \(P(w_c|w_t)\) được định nghĩa bởi:
với \(N\) là số phần tử của từ điển \(\mathcal{V}\). Ở đây \(\exp(\mathbf{u}_t^T\mathbf{v}_c)\) thể hiện mỗi quan hệ giữa từ đích \(w_t\) và từ ngữ cảnh \(w_c\). Biểu thức này càng cao thì xác suất thu được càng lớn. Tích vô hướng \(\mathbf{u}_t^T\mathbf{v}_c\) cũng thể hiện sự tương tự giữa hai vector.
Biểu thức này rất giống với công thức Softmax. Việc định nghĩa xác suất như biểu thức (1) ở trên đảm bảo rằng
Tóm lại, hàm mất mát ứng với từ đích \(w_t\) theo \(\mathbf{U}, \mathbf{V}\) được cho bởi
Biểu diễn dưới dạng mạng neural¶
Ta có thể thấy:
Note
skip-gram word2vec là một mạng neural vô cùng đơn giản với chỉ một tầng ẩn không có hàm kích hoạt.
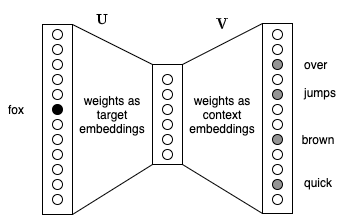
Fig. 11 Minh họa Skip-gram dưới dạng mạng neural.¶
Nhận xét này có thể được minh họa trên Fig. 11. Ở đây, \(\mathbf{u}_t\) chính là kết quả của phép nhân vector one-hot tương ứng với \(w_t\) với ma trận trọng số \(\mathbf{U}\), vì vậy đây chính là giá trị đầu ra của của tầng ẩn ở giữa khi xét từ đích \(w_t\). Tiếp theo, đầu ra của tầng ẩn không hàm kích hoạt này được nhân trực tiếp với ma trận trọng số đầu ra \(\mathbf{V}\) để được \(\mathbf{u}_t^T\mathbf{V}\), đây chính là giá trị vector logit trước khi đi vào hàm kích hoạt softmax như trong biểu thức (1).
Kiến trúc đơn giản này giúp word2vec hoạt động tốt ngay cả khi số lượng từ trong từ điển là cực lớn (có thể lên tới nhiều triệu từ). Lưu ý rằng kích thước đầu vào và đầu ra của mạng word2vec này bằng với số lượng từ trong từ điển.
Tối ưu hàm mất mát¶
Việc tối ưu hai ma trận trọng số \(\mathbf{U}\) và \(\mathbf{V}\) được thực hiện thông qua các thuật toán Gradient Descent. Các thuật toán tối ưu dạng này yêu cầu tính gradient cho từng ma trận.
Xét riêng số hạng
Đạo hàm theo \(\mathbf{u}_t\):
Như vậy, mặc dù gradient này rất đẹp, chúng ta vẫn cần phải tính toán các xác suất \(P(w_j | w_t)\). Mỗi xác suất này phụ thuộc toàn bộ ma trận trọng số \(\mathbf{V}\) và vector \(\mathbf{u}_t\). Như vậy ta cần cập nhập tổng cộng \(N*d + d\) trọng số. Đây rõ ràng là một con số rất lớn với \(N\) lớn.
Xấp xỉ hàm mất mát và Lấy mẫu âm¶
Để tránh việc cập nhật rất nhiều tham số này trong một lượt, một phương pháp xấp xỉ được đề xuất giúp cải thiện tốc độ tính toán đáng kể. Mỗi xác suất \(P(w_c | w_t)\) được mô hình bởi một hàm sigmoid thay vì hàm softmax:
Lưu ý rằng tổng các xác suất \(\sum_{w_c \in \mathbf{V}} P(w_c | w_t)\) không còn bằng 1 nữa. Tuy nhiên, nó vẫn mang ý nghĩa về xác suất có mặt của riêng từ ngữ cảnh \(w_c\) đi cùng với từ đích \(w_t\).
Lúc này, việc tính toán \(P(w_c | w_t)\) chỉ còn phụ thuộc vào vector \(\mathbf{u}_t\) và vector \(\mathbf{v}_c\) (thay vì cả ma trận \(\mathbf{V}\)). Tương ứng với số hạng này, sẽ chỉ có \(2d\) trọng số cần được cập nhật cho mỗi cặp \((w_t, w_c)\). Số lượng trọng số này không phụ thuộc vào kích thước từ điển, khiến cho cách mô hình này có thể hoạt động tốt với \(N\) rất lớn.
Có một vấn đề lớn với cách mô hình hóa này!
Vì không có sự ràng buộc giữa các xác suất \(P(w_c | w_t)\), khi cố gắng tối đa hóa mỗi xác suất sẽ dẫn đến việc nghiệm thu được thỏa mãn mọi \(P(w_c | w_t)\) đều cao. Điều này sẽ đạt được khi \(\exp(-\mathbf{u}_t^T \mathbf{v}_c)\) xấp xỉ 0. Chỉ cần toàn bộ các phần tử của \(\mathbf{U}\) và \(\mathbf{V}\) tiến tới dương vô cùng là thỏa mãn. Việc xấp xỉ này bây giờ trở nên tầm thường và vô nghĩa. Để tránh vấn đề này, ta cần thêm đưa thêm các ràng buộc sao cho tồn tại các xác suất \(P(w_n | w_t)\) khác cần được tối thiểu hóa khi xét tới từ đích \(w_t\).
Bản chất của bài toán tối ưu ban đầu là xây dựng mô hình sao cho với mỗi từ đích, xác suất của một từ ngữ cảnh xảy ra là cao trong khi xác suất của toàn bộ các từ ngoài ngữ cảnh đó là thấp – việc này được thể hiện trong hàm softmax. Để hạn chế tính toán, trong phương pháp này ta chỉ lấy mẫu ngẫu nhiên một vài từ ngoài ngữ cảnh đó để tối ưu. Các từ trong ngữ cảnh được gọi là “từ dương”, các từ ngoài ngữ cảnh được gọi là “từ âm”; vì vậy phương pháp này còn có tên gọi khác là “lấy mẫu âm” (negative sampling).
Khi đó, với mỗi từ đích, ta có một bộ các từ ngữ cảnh với nhãn là 1 và 0 tương ứng với các từ ngữ cảnh ban đầu (gọi là ngữ cảnh dương) và các từ ngữ cảnh âm được lấy mẫu từ ngoài tập ngữ cảnh dương đó. Với các từ ngữ cảnh dương, \(-\log(P(w_c | w_t))\) tương tự với hàm mất mát trong hồi quy logistic với nhãn bằng 1. Tương tự, ta có thể dùng \(-\log(1 - P(w_c | w_t))\) như là hàm mất mát cho các từ ngữ cảnh âm với nhãn bằng 0.
Continous Bag of Words (CBOW)¶
Ngược với Skip-gram, Continous bag of Words đi tìm xác suất xảy ra từ đích khi biết các từ ngữ cảnh xung quanh. Ta cần mô hình hóa dữ liệu sao cho xác suất sau đây đạt giá trị lớn:
Vì có nhiều từ ngữ cảnh trong điều kiện, chúng thường được đơn giản hóa bằng cách lấy một từ “trung bình” làm đại diện.
với \(\bar{w}_{\mathcal{C}_t}\) là trung bình cộng của các từ trong ngữ cảnh của từ đích \(w_t\). Embedding của từ trung bình này là trung bình của embedding các từ ngữ cảnh. Xác xuất này cũng được định nghĩa tương tự như trong Skip-gram:
Biểu diễn mạng neural cho CBOW được thể hiện như trong Fig. 12 dưới đây:

Fig. 12 Minh họa CBOW dưới dạng mạng neural.¶
Lưu ý rằng giá trị tại tầng ẩn là trung bình cộng của các embedding của các từ ngữ cảnh.
Kỹ thuật tối ưu likelihood này cũng tương tự như trong Skip-gram và phương pháp lấy mẫu âm với các từ đích cũng có thể được sử dụng một cách tương tự.
Câu hỏi: Sau khi huấn luyện mô hình xong, ta sẽ lấy ma trận nào làm embedding cho các từ?
Thảo luận¶
Word2vec là một phương pháp xây dựng embedding cho các từ trong từ điển dựa vào các ngữ cảnh trong câu.
Với mỗi ngữ cảnh, ta định nghĩa “từ đích” là từ trung tâm, “từ ngữ cảnh” là các từ xung quanh nó.
Có hai cách mô hình hóa dữ liệu là Skip-gram và CBOW. Skip-gram giả sử rằng từ một từ đích ta có thể suy ra các từ ngữ cảnh. CBOW giả sử rằng từ các từ ngữ cảnh, ta có thể đoán được từ đích.
Skip-gram làm việc tốt với dữ liệu nhỏ, nó có khả năng biểu diễn tốt những từ có tần suất thấp. Việc này hợp lý vì ta xây dựng được nhiều mẫu huấn luyện xung quanh từ có tần suất thấp này.
CBOW phù hợp với các bộ dữ liệu lớn khi mà số mẫu huấn luyện được tạo ra từ mỗi ngữ cảnh (chỉ là một) ít hơn nhiều so với Skip-gram (tỉ lệ với kích thước cửa số ngữ cảnh). CBOW biểu diễn tốt hơn các từ xảy ra thường xuyên.
Word2vec không chỉ có thể sử dụng để tạo embedding cho các từ mà còn có thể áp dụng cho các bộ dữ liệu khác mà sự xuất hiện của một đối tượng phụ thuộc vào các đối tượng khác trong cùng văn cảnh. Trong bài Using Word2vec for Music Recommendations, tác giả coi mỗi một lượt nghe nhạc của người dùng là một “câu” và mỗi bài nhạc là một “từ”. Từ đó xây dựng được các embedding cho các bài hát và gợi ý những bài hát mà người dùng có khả năng thích nghe. Trong phần tiếp theo, chúng ta sẽ sử dụng Skip-gram Word2vec để xây dựng embedding cho các sản phẩm trong bộ dữ liệu Instacart.
Ngoài lấy mẫu âm, softmax phân tầng cũng là một phương pháp làm giảm độ phức tạp khi tối ưu hàm mất mát cho word2vec.