
Trong trang này:
- 1. Giới thiệu
- 2. Validation
- 3. Regularization
- 4. Các phương pháp khác
- 5. Tóm tắt nội dung
- 6. Tài liệu tham khảo
Overfitting không phải là một thuật toán trong Machine Learning. Nó là một hiện tượng không mong muốn thường gặp, người xây dựng mô hình Machine Learning cần nắm được các kỹ thuật để tránh hiện tượng này.
1. Giới thiệu
Đây là một câu chuyện của chính tôi khi lần đầu biết đến Machine Learning.
Năm thứ ba đại học, một thầy giáo có giới thiệu với lớp tôi về Neural Networks. Lần đầu tiên nghe thấy khái niệm này, chúng tôi hỏi thầy mục đích của nó là gì. Thầy nói, về cơ bản, từ dữ liệu cho trước, chúng ta cần tìm một hàm số để biến các các điểm đầu vào thành các điểm đầu ra tương ứng, không cần chính xác, chỉ cần xấp xỉ thôi.
Lúc đó, vốn là một học sinh chuyên toán, làm việc nhiều với đa thức ngày cấp ba, tôi đã quá tự tin trả lời ngay rằng Đa thức Nội suy Lagrange có thể làm được điều đó, miễn là các điểm đầu vào khác nhau đôi một! Thầy nói rằng “những gì ta biết chỉ là nhỏ xíu so với những gì ta chưa biết”. Và đó là những gì tôi muốn bắt đầu trong bài viết này.
Nhắc lại một chút về Đa thức nội suy Lagrange: Với \(N\) cặp điểm dữ liệu \((x_1, y_1), (x_2, y_2), \dots, (x_N, y_N)\) với các \(x_i\) kháu nhau đôi một, luôn tìm được một đa thức \(P(.)\) bậc không vượt quá \(N-1\) sao cho \(P(x_i) = y_i, ~\forall i = 1, 2, \dots, N\). Chẳng phải điều này giống với việc ta đi tìm một mô hình phù hợp (fit) với dữ liệu trong bài toán Supervised Learning hay sao? Thậm chí điều này còn tốt hơn vì trong Supervised Learning ta chỉ cần xấp xỉ thôi.
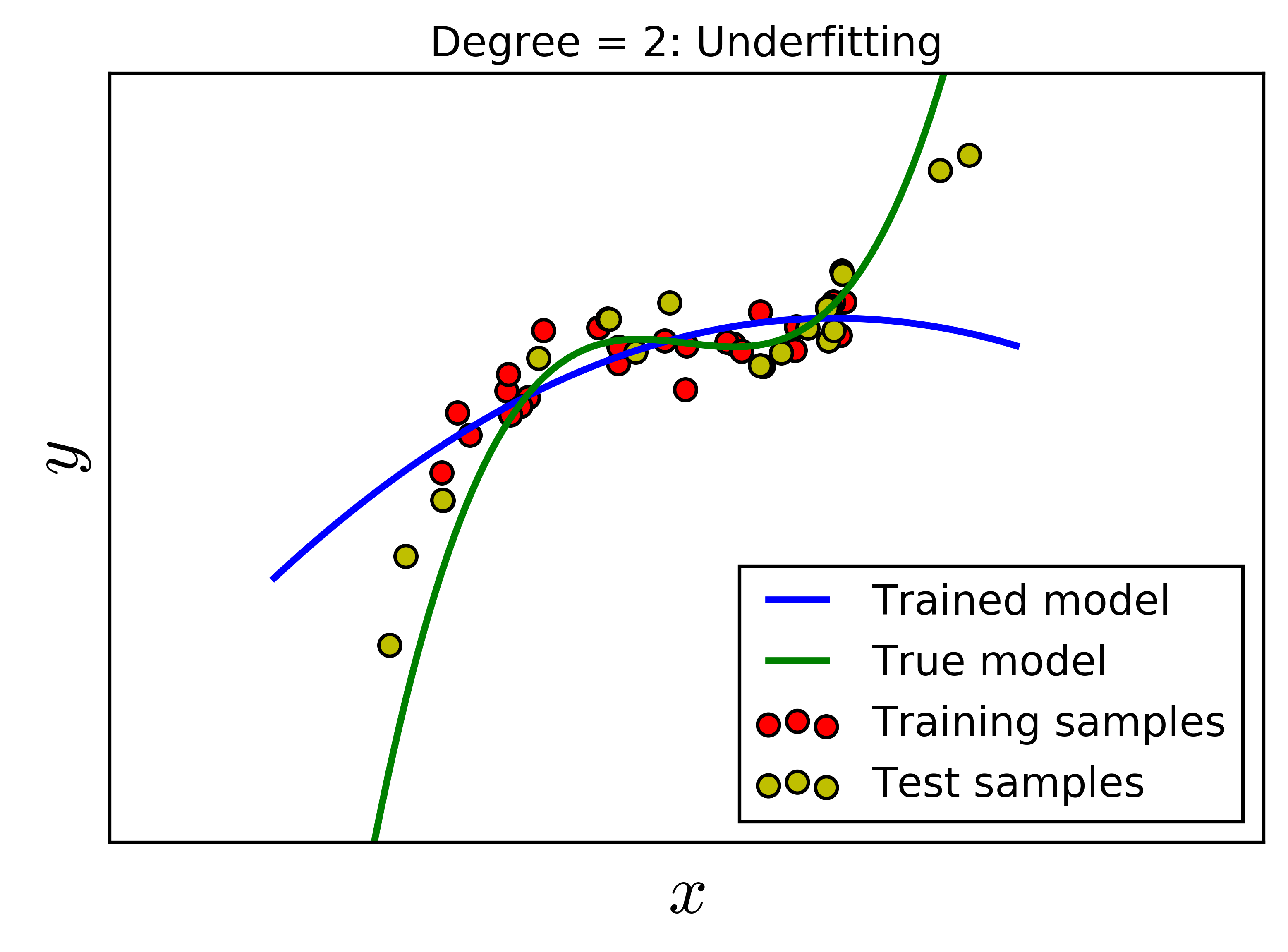
Sự thật là nếu một mô hình quá fit với dữ liệu thì nó sẽ gây phản tác dụng! Hiện tượng quá fit này trong Machine Learning được gọi là overfitting, là điều mà khi xây dựng mô hình, chúng ta luôn cần tránh. Để có cái nhìn đầu tiên về overfitting, chúng ta cùng xem Hình dưới đây. Có 50 điểm dữ liệu được tạo bằng một đa thức bậc ba cộng thêm nhiễu. Tập dữ liệu này được chia làm hai, 30 điểm dữ liệu màu đỏ cho training data, 20 điểm dữ liệu màu vàng cho test data. Đồ thị của đa thức bậc ba này được cho bởi đường màu xanh lục. Bài toán của chúng ta là giả sử ta không biết mô hình ban đầu mà chỉ biết các điểm dữ liệu, hãy tìm một mô hình “tốt” để mô tả dữ liệu đã cho.
|
|
|
|
Với những gì chúng ta đã biết từ bài Linear Regression, với loại dữ liệu này, chúng ta có thể áp dụng Polynomial Regression. Bài toán này hoàn toàn có thể được giải quyết bằng Linear Regression với dữ liệu mở rộng cho một cặp điểm \((x, y)\) là \((\mathbf{x}, y)\) với \(\mathbf{x} = [1, x, x^2, x^3, \dots, x^d]^T\) cho đa thức bậc \(d\). Điều quan trọng là chúng ta cần tìm bậc \(d\) của đa thức cần tìm.
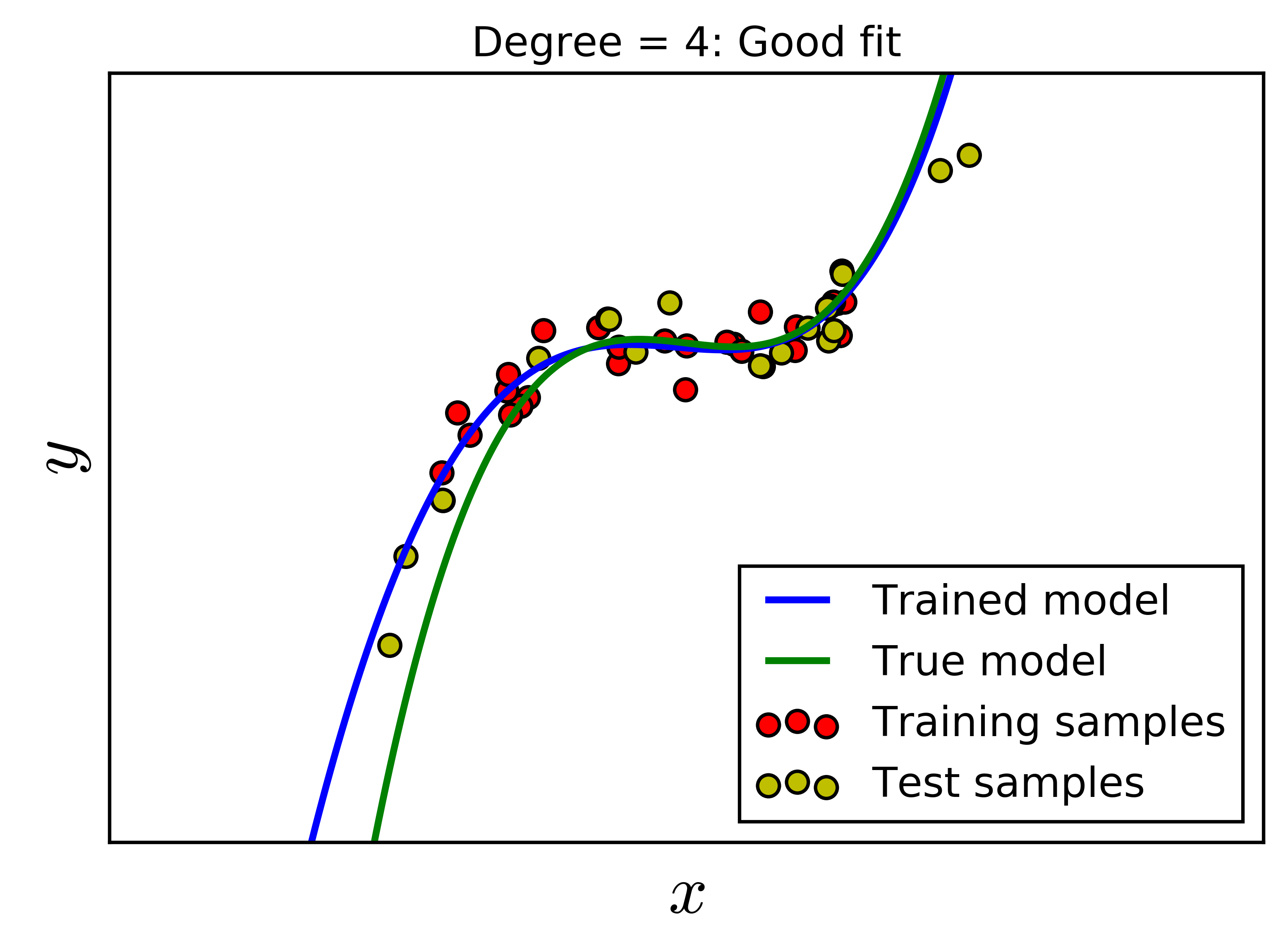
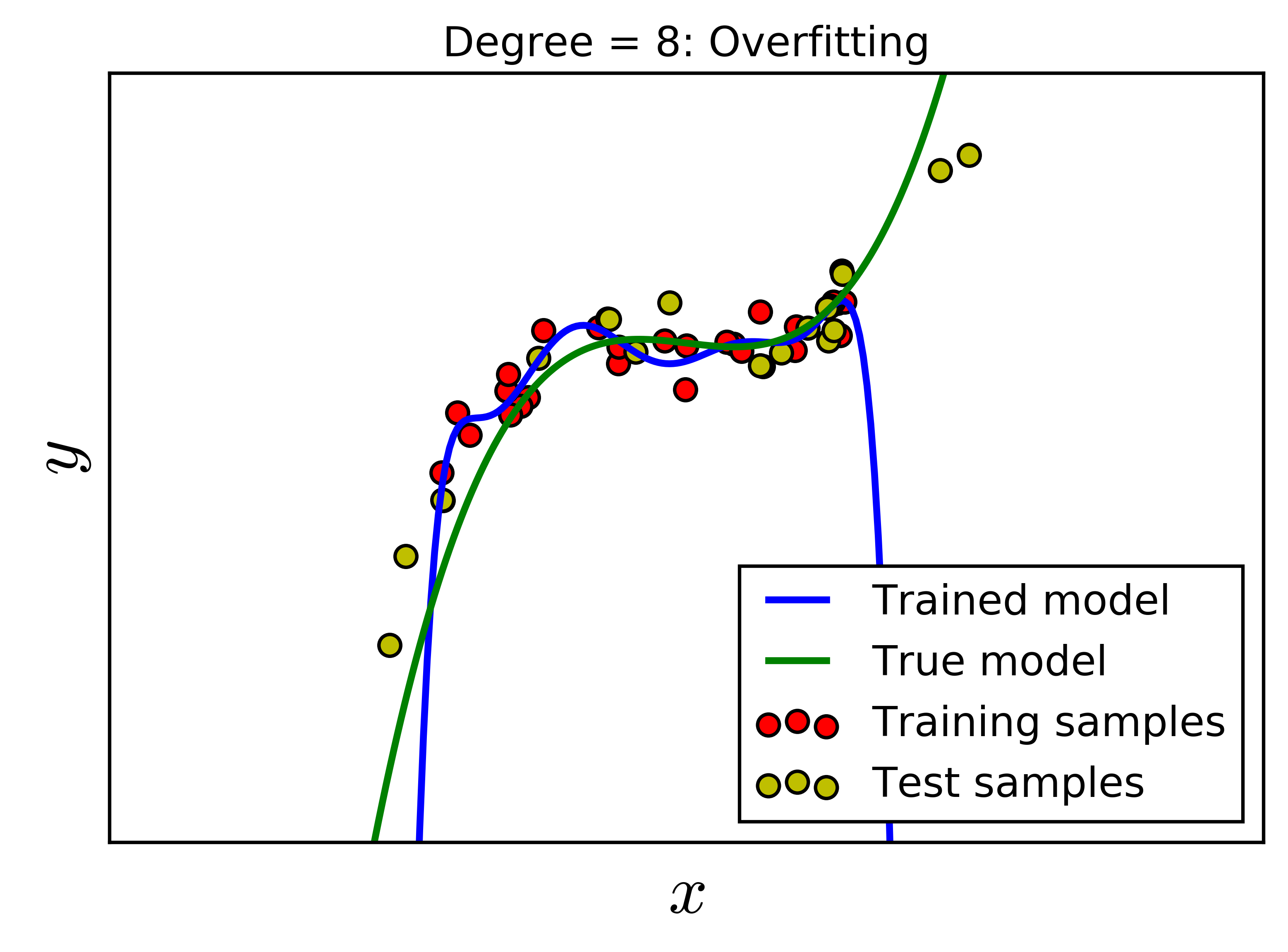
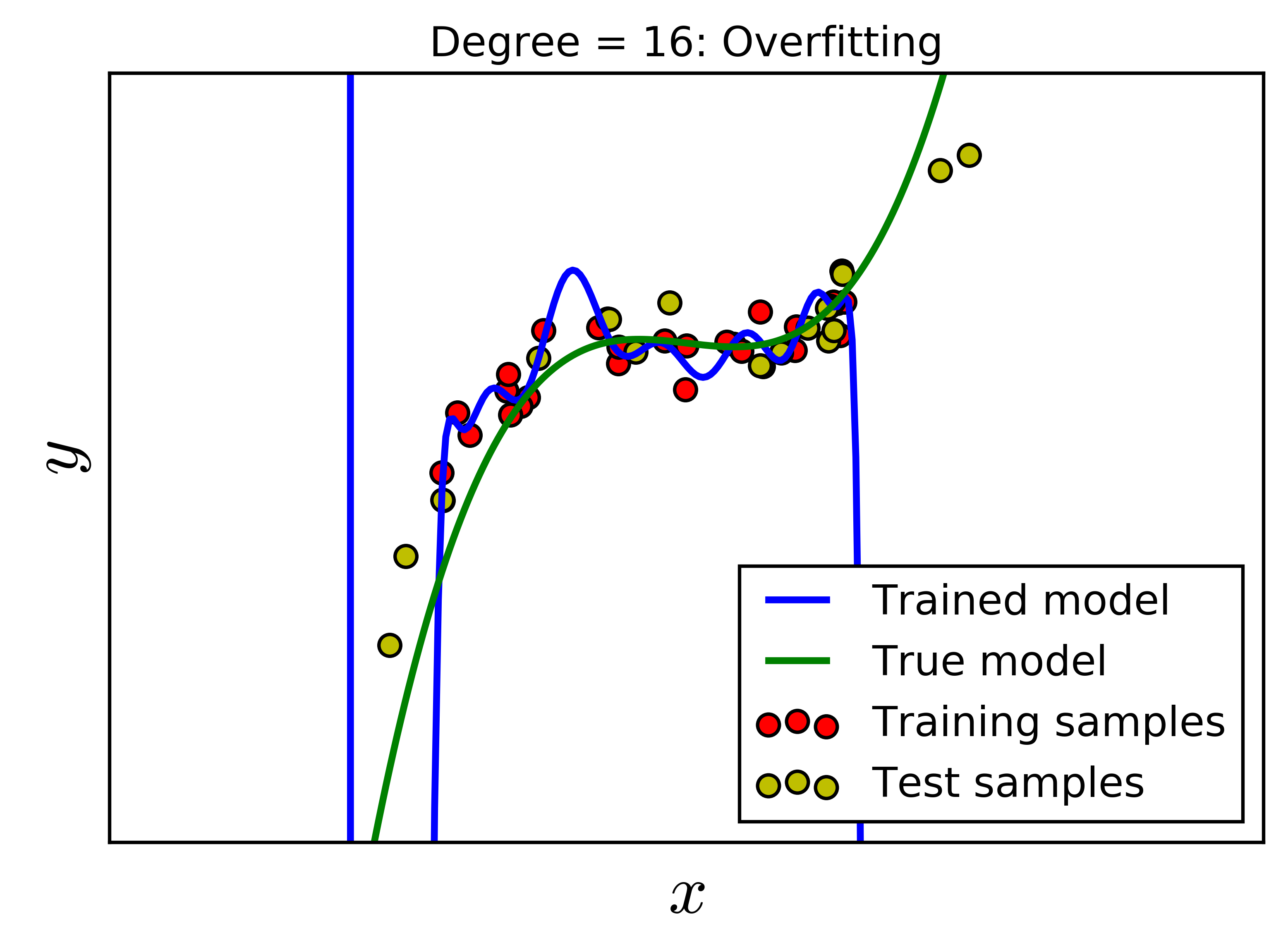
Rõ ràng là một đa thức bậc không vượt quá 29 có thể fit được hoàn toàn với 30 điểm trong training data. Chúng ta cùng xét vài giá trị \(d = 2, 4, 8, 16\). Với \(d = 2\), mô hình không thực sự tốt vì mô hình dự đoán quá khác so với mô hình thực. Trong trường hợp này, ta nói mô hình bị underfitting. Với \(d = 8\), với các điểm dữ liệu trong khoảng của training data, mô hình dự đoán và mô hình thực là khá giống nhau. Tuy nhiên, về phía phải, đa thức bậc 8 cho kết quả hoàn toàn ngược với xu hướng của dữ liệu. Điều tương tự xảy ra trong trường hợp \(d = 16\). Đa thức bậc 16 này quá fit dữ liệu trong khoảng đang xét, và quá fit, tức không được mượt trong khoảng dữ liệu training. Việc quá fit trong trường hợp bậc 16 không tốt vì mô hình đang cố gắng mô tả nhiễu hơn là dữ liệu. Hai trường hợp đa thức bậc cao này được gọi là Overfitting.
Nếu bạn nào biết về Đa thức nội suy Lagrange thì có thể hiểu được hiện tượng sai số lớn với các điểm nằm ngoài khoảng của các điểm đã cho. Đó chính là lý do phương pháp đó có từ “nội suy”, với các trường hợp “ngoại suy”, kết quả thường không chính xác.
Với \(d = 4\), ta được mô hình dự đoán khá giống với mô hình thực. Hệ số bậc cao nhất tìm được rất gần với 0 (xem kết quả trong source code), vì vậy đa thức bậc 4 này khá gần với đa thức bậc 3 ban đầu. Đây chính là một mô hình tốt.
Overfitting là hiện tượng mô hình tìm được quá khớp với dữ liệu training. Việc quá khớp này có thể dẫn đến việc dự đoán nhầm nhiễu, và chất lượng mô hình không còn tốt trên dữ liệu test nữa. Dữ liệu test được giả sử là không được biết trước, và không được sử dụng để xây dựng các mô hình Machine Learning.
Về cơ bản, overfitting xảy ra khi mô hình quá phức tạp để mô phỏng training data. Điều này đặc biệt xảy ra khi lượng dữ liệu training quá nhỏ trong khi độ phức tạp của mô hình quá cao. Trong ví dụ trên đây, độ phức tạp của mô hình có thể được coi là bậc của đa thức cần tìm. Trong Multi-layer Perceptron, độ phức tạp của mô hình có thể được coi là số lượng hidden layers và số lượng units trong các hidden layers.
Vậy, có những kỹ thuật nào giúp tránh Overfitting?
Trước hết, chúng ta cần một vài đại lượng để đánh giá chất lượng của mô hình trên training data và test data. Dưới đây là hai đại lượng đơn giản, với giả sử \(\mathbf{y}\) là đầu ra thực sự (có thể là vector), và \(\mathbf{\hat{y}}\) là đầu ra dự đoán bởi mô hình:
Train error: Thường là hàm mất mát áp dụng lên training data. Hàm mất mát này cần có một thừa số \(\frac{1}{N_{\text{train}}} \) để tính giá trị trung bình, tức mất mát trung bình trên mỗi điểm dữ liệu. Với Regression, đại lượng này thường được định nghĩa: \[ \text{train error}= \frac{1}{N_{\text{train}}} \sum_{\text{training set}} \|\mathbf{y} - \mathbf{\hat{y}}\|_p^2 \] với \(p\) thường bằng 1 hoặc 2.
Với Classification, trung bình cộng của cross entropy có thể được sử dụng.
Test error: Tương tự như trên nhưng áp dụng mô hình tìm được vào test data. Chú ý rằng, khi xây dựng mô hình, ta không được sử dụng thông tin trong tập dữ liệu test. Dữ liệu test chỉ được dùng để đánh giá mô hình. Với Regression, đại lượng này thường được định nghĩa: \[ \text{test error}= \frac{1}{N_{\text{test}}} \sum_{\text{test set}} \|\mathbf{y} - \mathbf{\hat{y}}\|_p^2 \]
với \(p\) giống như \(p\) trong cách tính train error phía trên.
Việc lấy trung bình là quan trọng vì lượng dữ liệu trong hai tập hợp training và test có thể chênh lệch rất nhiều.
Một mô hình được coi là tốt (fit) nếu cả train error và test error đều thấp. Nếu train error thấp nhưng test error cao, ta nói mô hình bị overfitting. Nếu train error cao và test error cao, ta nói mô hình bị underfitting. Nếu train error cao nhưng test error thấp, tôi không biết tên của mô hình này, vì cực kỳ may mắn thì hiện tượng này mới xảy ra, hoặc có chỉ khi tập dữ liệu test quá nhỏ.
Chúng ta cùng đi vào phương pháp đầu tiên
2. Validation
2.1. Validation
Chúng ta vẫn quen với việc chia tập dữ liệu ra thành hai tập nhỏ: training data và test data. Và một điều tôi vẫn muốn nhắc lại là khi xây dựng mô hình, ta không được sử dụng test data. Vậy làm cách nào để biết được chất lượng của mô hình với unseen data (tức dữ liệu chưa nhìn thấy bao giờ)?
Phương pháp đơn giản nhất là trích từ tập training data ra một tập con nhỏ và thực hiện việc đánh giá mô hình trên tập con nhỏ này. Tập con nhỏ được trích ra từ training set này được gọi là validation set. Lúc này, training set là phần còn lại của training set ban đầu. Train error được tính trên training set mới này, và có một khái niệm nữa được định nghĩa tương tự như trên validation error, tức error được tính trên tập validation.
Việc này giống như khi bạn ôn thi. Giả sử bạn không biết đề thi như thế nào nhưng có 10 bộ đề thi từ các năm trước. Để xem trình độ của mình trước khi thi thế nào, có một cách là bỏ riêng một bộ đề ra, không ôn tập gì. Việc ôn tập sẽ được thực hiện dựa trên 9 bộ còn lại. Sau khi ôn tập xong, bạn bỏ bộ đề đã để riêng ra làm thử và kiểm tra kết quả, như thế mới “khách quan”, mới giống như thi thật. 10 bộ đề ở các năm trước là “toàn bộ” training set bạn có. Để tránh việc học lệch, học tủ theo chỉ 10 bộ, bạn tách 9 bộ ra làm training set thật, bộ còn lại là validation test. Khi làm như thế thì mới đánh giá được việc bạn học đã tốt thật hay chưa, hay chỉ là học tủ. Vì vậy, Overfitting còn có thể so sánh với việc Học tủ của con người.
Với khái niệm mới này, ta tìm mô hình sao cho cả train error và validation error đều nhỏ, qua đó có thể dự đoán được rằng test error cũng nhỏ. Phương pháp thường được sử dụng là sử dụng nhiều mô hình khác nhau. Mô hình nào cho validation error nhỏ nhất sẽ là mô hình tốt.
Thông thường, ta bắt đầu từ mô hình đơn giản, sau đó tăng dần độ phức tạp của mô hình. Tới khi nào validation error có chiều hướng tăng lên thì chọn mô hình ngay trước đó. Chú ý rằng mô hình càng phức tạp, train error có xu hướng càng nhỏ đi.
Hình dưới đây mô tả ví dụ phía trên với bậc của đa thức tăng từ 1 đến 8. Tập validation bao gồm 10 điểm được lấy ra từ tập training ban đầu.

Chúng ta hãy tạm chỉ xét hai đường màu lam và đỏ, tương ứng với train error và validation error. Khi bậc của đa thức tăng lên, train error có xu hướng giảm. Điều này dễ hiểu vì đa thức bậc càng cao, dữ liệu càng được fit. Quan sát đường màu đỏ, khi bậc của đa thức là 3 hoặc 4 thì validation error thấp, sau đó tăng dần lên. Dựa vào validation error, ta có thể xác định được bậc cần chọn là 3 hoặc 4. Quan sát tiếp đường màu lục, tương ứng với test error, thật là trùng hợp, với bậc bằng 3 hoặc 4, test error cũng đạt giá trị nhỏ nhất, sau đó tăng dần lên. Vậy cách làm này ở đây đã tỏ ra hiệu quả.
Việc không sử dụng test data khi lựa chọn mô hình ở trên nhưng vẫn có được kết quả khả quan vì ta giả sử rằng validation data và test data có chung một đặc điểm nào đó. Và khi cả hai đều là unseen data, error trên hai tập này sẽ tương đối giống nhau.
Nhắc lại rằng, khi bậc nhỏ (bằng 1 hoặc 2), cả ba error đều cao, ta nói mô hình bị underfitting.
2.2. Cross-validation
Trong nhiều trường hợp, chúng ta có rất hạn chế số lượng dữ liệu để xây dựng mô hình. Nếu lấy quá nhiều dữ liệu trong tập training ra làm dữ liệu validation, phần dữ liệu còn lại của tập training là không đủ để xây dựng mô hình. Lúc này, tập validation phải thật nhỏ để giữ được lượng dữ liệu cho training đủ lớn. Tuy nhiên, một vấn đề khác nảy sinh. Khi tập validation quá nhỏ, hiện tượng overfitting lại có thể xảy ra với tập training còn lại. Có giải pháp nào cho tình huống này không?
Câu trả lời là cross-validation.
Cross validation là một cải tiến của validation với lượng dữ liệu trong tập validation là nhỏ nhưng chất lượng mô hình được đánh giá trên nhiều tập validation khác nhau. Một cách thường đường sử dụng là chia tập training ra \(k\) tập con không có phần tử chung, có kích thước gần bằng nhau. Tại mỗi lần kiểm thử , được gọi là run, một trong số \(k\) tập con được lấy ra làm validate set. Mô hình sẽ được xây dựng dựa vào hợp của \(k-1\) tập con còn lại. Mô hình cuối được xác định dựa trên trung bình của các train error và validation error. Cách làm này còn có tên gọi là k-fold cross validation.
Khi \(k\) bằng với số lượng phần tử trong tập training ban đầu, tức mỗi tập con có đúng 1 phần tử, ta gọi kỹ thuật này là leave-one-out.
Sklearn hỗ trợ rất nhiều phương thức cho phân chia dữ liệu và tính toán scores của các mô hình. Bạn đọc có thể xem thêm tại Cross-validation: evaluating estimator performance.
3. Regularization
Một nhược điểm lớn của cross-validation là số lượng training runs tỉ lệ thuận với \(k\). Điều đáng nói là mô hình polynomial như trên chỉ có một tham số cần xác định là bậc của đa thức. Trong các bài toán Machine Learning, lượng tham số cần xác định thường lớn hơn nhiều, và khoảng giá trị của mỗi tham số cũng rộng hơn nhiều, chưa kể đến việc có những tham số có thể là số thực. Như vậy, việc chỉ xây dựng một mô hình thôi cũng là đã rất phức tạp rồi. Có một cách giúp số mô hình cần huấn luyện giảm đi nhiều, thậm chí chỉ một mô hình. Cách này có tên gọi chung là regularization.
Regularization, một cách cơ bản, là thay đổi mô hình một chút để tránh overfitting trong khi vẫn giữ được tính tổng quát của nó (tính tổng quát là tính mô tả được nhiều dữ liệu, trong cả tập training và test). Một cách cụ thể hơn, ta sẽ tìm cách di chuyển nghiệm của bài toán tối ưu hàm mất mát tới một điểm gần nó. Hướng di chuyển sẽ là hướng làm cho mô hình ít phức tạp hơn mặc dù giá trị của hàm mất mát có tăng lên một chút.
Một kỹ thuật rất đơn giản là early stopping.
3.1. Early Stopping
Trong nhiều bài toán Machine Learning, chúng ta cần sử dụng các thuật toán lặp để tìm ra nghiệm, ví dụ như Gradient Descent. Nhìn chung, hàm mất mát giảm dần khi số vòng lặp tăng lên. Early stopping tức dừng thuật toán trước khi hàm mất mát đạt giá trị quá nhỏ, giúp tránh overfitting.
Vậy dừng khi nào là phù hợp?
Một kỹ thuật thường được sử dụng là tách từ training set ra một tập validation set như trên. Sau một (hoặc một số, ví dụ 50) vòng lặp, ta tính cả train error và validation error, đến khi validation error có chiều hướng tăng lên thì dừng lại, và quay lại sử dụng mô hình tương ứng với điểm và validation error đạt giá trị nhỏ.

Hình trên đây mô tả cách tìm điểm stopping. Chúng ta thấy rằng phương pháp này khá giống với phương pháp tìm bậc của đa thức ở phần trên của bài viết.
3.2. Thêm số hạng vào hàm mất mát
Kỹ thuật regularization phổ biến nhất là thêm vào hàm mất mát một số hạng nữa. Số hạng này thường dùng để đánh giá độ phức tạp của mô hình. Số hạng này càng lớn, thì mô hình càng phức tạp. Hàm mất mát mới này thường được gọi là regularized loss function, thường được định nghĩa như sau: \[ J_{\text{reg}}(\theta) = J(\theta) + \lambda R(\theta) \]
Nhắc lại rằng \(\theta\) được dùng để ký hiệu các biến trong mô hình, chẳng hạn như các hệ số \(\mathbf{w}\) trong Neural Networks. \(J(\theta)\) ký hiệu cho hàm mất mát (loss function) và \(R(\theta)\) là số hạng regularization. \(\lambda\) thường là một số dương để cân bằng giữa hai đại lượng ở vế phải.
Việc tối thiểu regularized loss function, nói một cách tương đối, đồng nghĩa với việc tối thiểu cả loss function và số hạng regularization. Tôi dùng cụm “nói một cách tương đối” vì nghiệm của bài toán tối ưu loss function và regularized loss function là khác nhau. Chúng ta vẫn mong muốn rằng sự khác nhau này là nhỏ, vì vậy tham số regularization (regularization parameter) \(\lambda\) thường được chọn là một số nhỏ để biểu thức regularization không làm giảm quá nhiều chất lượng của nghiệm.
Với các mô hình Neural Networks, một số kỹ thuật regularization thường được sử dụng là:
3.3. \(l_2\) regularization
Trong kỹ thuật này: \[ R(\mathbf{w}) = \|\mathbf{w}\|_2^2 \] tức norm 2 của hệ số.
Nếu bạn đọc chưa quen thuộc với khái niệm norm, bạn được khuyến khích đọc phần phụ lục này.
Hàm số này có một vài đặc điểm đang lưu ý:
- Thứ nhất, \(\|\mathbf{w}\|_2^2\) là một hàm số rất mượt, tức có đạo hàm tại mọi điểm, đạo hàm của nó đơn giản là \(\mathbf{w}\), vì vậy đạo hàm của regularized loss function cũng rất dễ tính, chúng ta có thể hoàn toàn dùng các phương pháp dựa trên gradient để cập nhật nghiệm. Cụ thể: \[ \frac{\partial J_{\text{reg}} }{\partial \mathbf{w}} = \frac{\partial J}{\partial \mathbf{w}} + \lambda \mathbf{w} \]
- Thứ hai, việc tối thiểu \(\|\mathbf{w}\|_2^2\) đồng nghĩa với việc khiến cho các giá trị của hệ số \(\mathbf{w}\) trở nên nhỏ gần với 0. Với Polynomial Regression, việc các hệ số này nhỏ có thể giúp các hệ số ứng với các số hạng bậc cao là nhỏ, giúp tránh overfitting. Với Multi-layer Perceptron, việc các hệ số này nhỏ giúp cho nhiều hệ số trong các ma trận trọng số là nhỏ. Điều này tương ứng với việc số lượng các hidden units hoạt động (khác không) là nhỏ, cũng giúp cho MLP tránh được hiện tượng overfitting.
\(l_2\) regularization là kỹ thuật được sử dụng nhiều nhất để giúp Neural Networks tránh được overfitting. Nó còn có tên gọi khác là weight decay. Decay có nghĩa là tiêu biến.
Trong Xác suất thống kê, Linear Regression với \(l_2\) regularization được gọi là Ridge Regression. Hàm mất mát của Ridge Regression có dạng: \[ J(\mathbf{w}) = \frac{1}{2} \|\mathbf{y} - \mathbf{Xw}\|_2^2 + \lambda \|\mathbf{w}\|_2^2 \] trong đó, số hạng đầu tiên ở vế phải chính là hàm mất mát của Linear Regression. Số hạng thứ hai chính là phần regularization.
Ví dụ về Weight Decay với MLP
Chúng ta sử dụng mô hình MLP giống như bài trước nhưng dữ liệu có khác đi đôi chút.
# To support both python 2 and python 3
from __future__ import division, print_function, unicode_literals
import math
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(4)
means = [[-1, -1], [1, -1], [0, 1]]
cov = [[1, 0], [0, 1]]
N = 20
X0 = np.random.multivariate_normal(means[0], cov, N)
X1 = np.random.multivariate_normal(means[1], cov, N)
X2 = np.random.multivariate_normal(means[2], cov, N)
Dữ liệu được tạo là ba cụm tuân theo phân phối chuẩn có tâm ở [[-1, -1], [1, -1], [0, 1]].
Trong ví dụ này, chúng ta sử dụng số hạng regularization: \[ \lambda R(\mathbf{W}) = \lambda \sum_{l=1}^L \|\mathbf{W}^{(l)}\|_F^2 \]
với \(\|.\|_F\) là Frobenius norm, là căn bậc hai của tổng bình phường các phẩn tử của ma trận.
(Bạn đọc được khuyến khích đọc bài MLP để hiểu các ký hiệu).
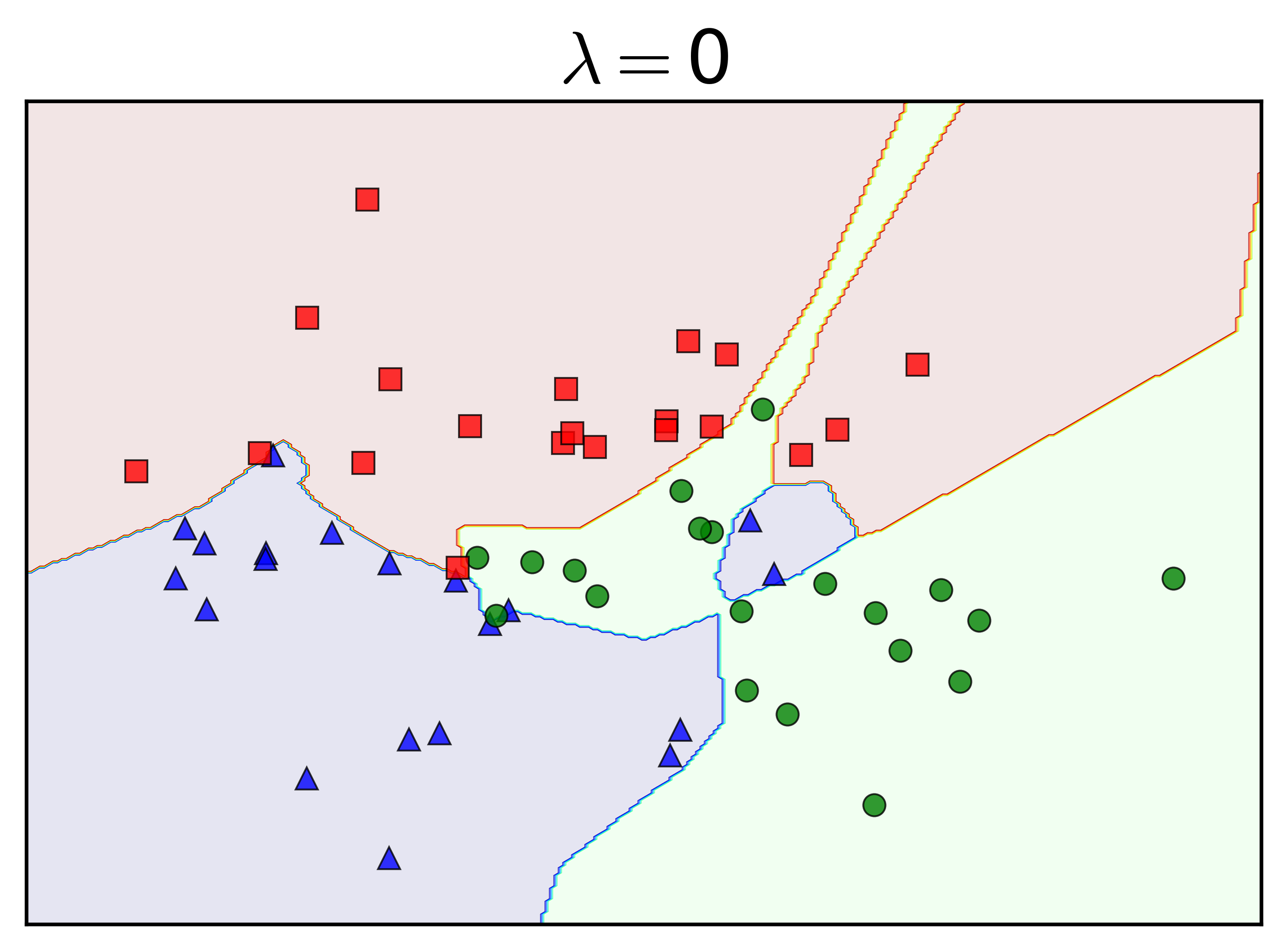
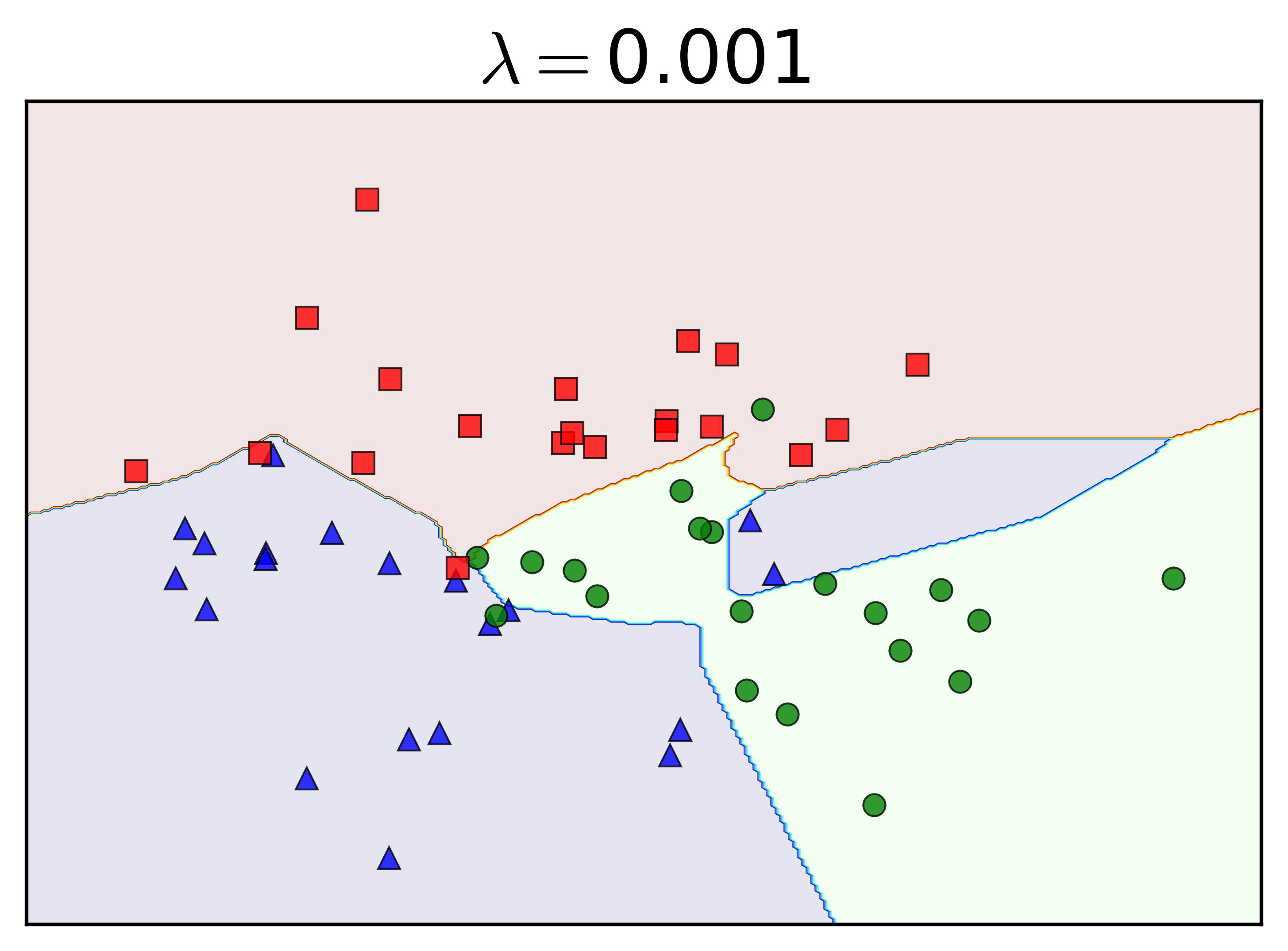
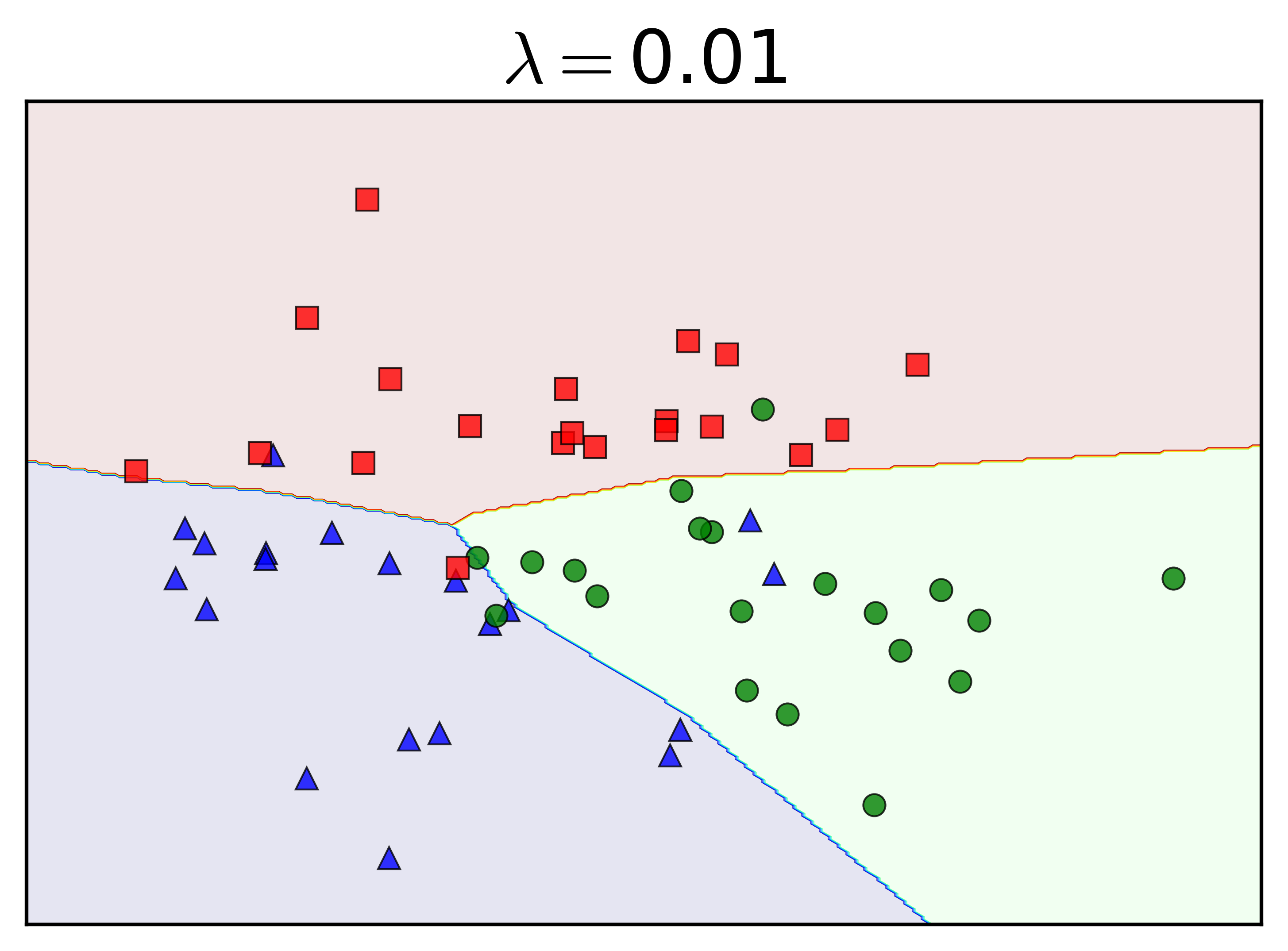
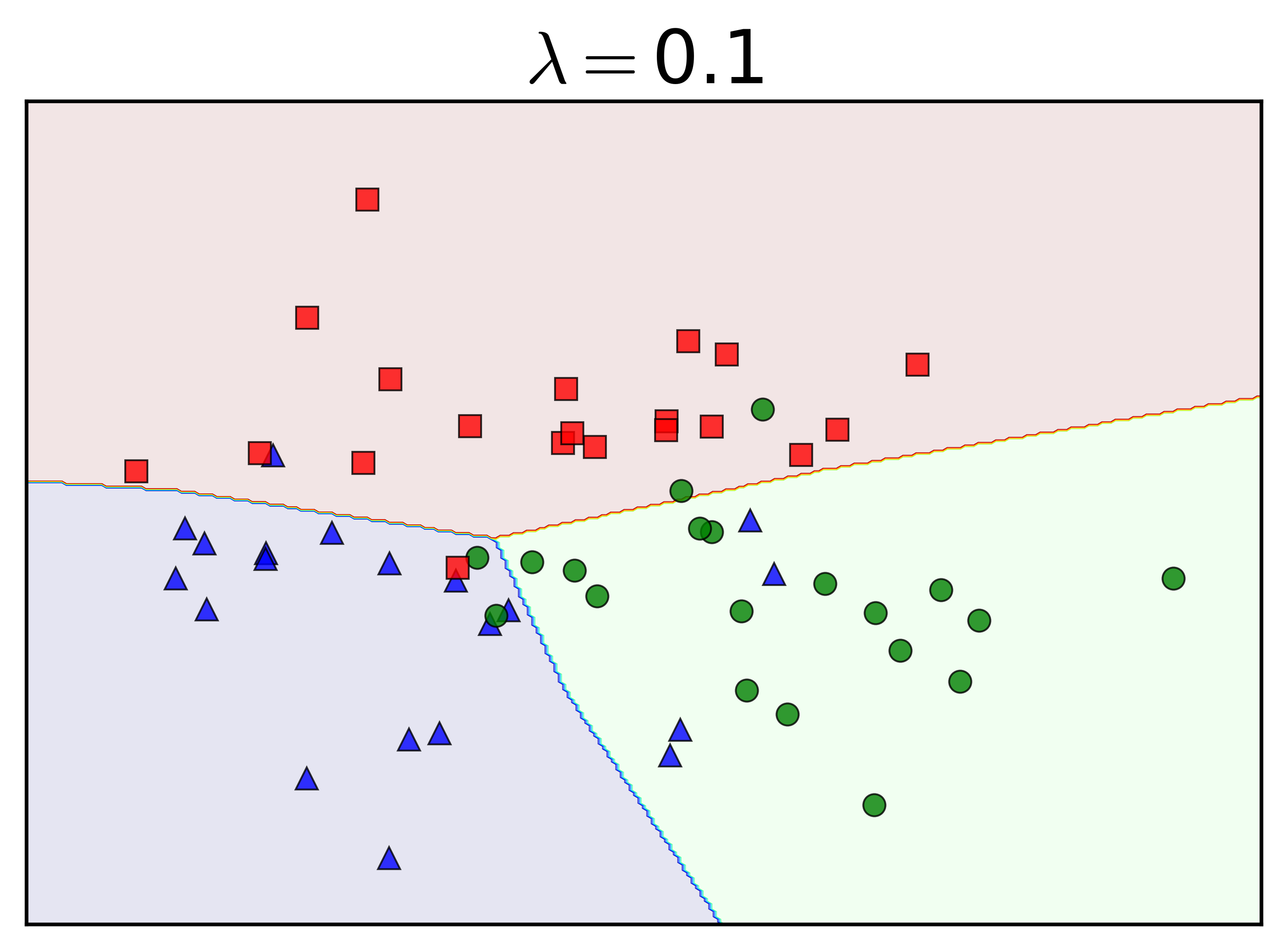
Chú ý rằng weight decay ít khi được áp dụng lên biases. Tôi thay đổi tham số regularization \(\lambda\) và nhận được kết quả như sau:
|
|
|
|
Khi \(\lambda = 0\), tức không có regularization, ta nhận thấy gần như toàn bộ dữ liệu trong tập training được phân lớp đúng. Việc này khiến cho các class bị phân làm nhiều mảnh không được tự nhiên. Khi \(\lambda = 0.001\), vẫn là một số nhỏ, các đường phân chia trông tự nhiên hơn, nhưng lớp màu xanh lam vẫn bị chia làm hai bởi lớp màu xanh lục. Đây chính là biểu hiện của overfitting.
Khi \(\lambda\) tăng lên, tức sự ảnh hưởng của regularization tăng lên (xem hàng dưới), đường ranh giới giữa các lớp trở lên tự nhiên hơn. Nói cách khác, với \(\lambda\) đủ lớn, weight decay có tác dụng hạn chế overfitting trong MLP.
Bạn đọc hãy thử vào trong Source code, thay \(\lambda = 1\) bằng cách thay dòng cuối cùng:
mynet(1)
rồi chạy lại toàn bộ code, xem các đường phân lớp trông như thế nào. Gợi ý: underfitting.
Khi \(\lambda\) quá lớn, tức ta xem phần regularization quan trọng hơn phần loss fucntion, một hiện tượng xấu xảy ra là các phần tử của \(\mathbf{w}\) tiến về 0 để thỏa mãn regularization là nhỏ.
Sklearn có cung cấp rất nhiều chức năng cho MLP, trong đó ta có thể lựa chọn số lượng hidden layers và số lượng hidden units trong mỗi layer, activation functions, weight decay, learning rate, hệ số momentum, nesterovs_momentum, có early stopping hay không, lượng dữ liệu được tách ra làm validation set, và nhiều chức năng khác.
3.4. Tikhonov regularization
\[ \lambda R(\mathbf{w}) = \|\Gamma \mathbf{w}\|_2^2 \]
Với \(\Gamma\) (viết hoa của gamma) là một ma trận. Ma trận \(\Gamma\) hay được dùng nhất là ma trận đường chéo. Nhận thấy rằng \(l_2\) regularization chính là một trường hợp đặc biệt của Tikhonov regularization với \(\Gamma = \lambda \mathbf{I}\) với \(\mathbf{I}\) là ma trận đơn vị (the identity matrix), tức các phần tử trên đường chéo của \(\Gamma\) là như nhau.
Khi các phần tử trên đường chéo của \(\Gamma\) là khác nhau, ta có một phiên bản gọi là weighted \(l_2\) regularization, tức đánh trọng số khác nhau cho mỗi phần tử trong \(\mathbf{w}\). Phần tử nào càng bị đánh trọng số cao thì nghiệm tương ứng càng nhỏ (để đảm bảo rằng hàm mất mát là nhỏ). Với Polynomial Regression, các phần tử ứng với hệ số bậc cao sẽ được đánh trọng số cao hơn, khiến cho xác suất để chúng gần 0 là lớn hơn.
3.5. Regularizers for sparsity
Trong nhiều trường hợp, ta muốn các hệ số thực sự bằng 0 chứ không phải là nhỏ gần 0 như \(l_2\) regularization đã làm phía trên. Lúc đó, có một regularization khác được sử dụng, đó là \(l_0\) regularization: \[ R(\mathbf{W}) = \|\mathbf{w}\|_0 \]
Norm 0 không phải là một norm thực sự mà là giả norm. (Bạn được khuyến khích đọc thêm về norms (chuẩn)). Norm 0 của một vector là số các phần tử khác không của vector đó. Khi norm 0 nhỏ, tức rất nhiều phần tử trong vector đó bằng 0, ta nói vector đó là sparse.
Việc giải bài toán tổi thiểu norm 0 nhìn chung là khó vì hàm số này không convex, không liên tục. Thay vào đó, norm 1 thường được sử dụng: \[ R(\mathbf{W}) = \|\mathbf{w}\|_1 = \sum_{i=0}^d |w_i| \]
Norm 1 là tổng các trị tuyệt đối của tất cả các phần tử. Người ta đã chứng minh được rằng tối thiểu norm 1 sẽ dẫn tới nghiệm có nhiều phần tử bằng 0. Ngoài ra, vì norm 1 là một norm thực sự (proper norm) nên hàm số này là convex, và hiển nhiên là liên tục, việc giải bài toán này dễ hơn việc giải bài toán tổi thiểu norm 0. Về \(l_1\) regularization, bạn đọc có thể đọc thêm trong lecture note này. Việc giải bài toán \(l_1\) regularization nằm ngoài mục đích của tôi trong bài viết này. Tôi hứa sẽ quay lại phần này sau. (Vì đây là phần chính trong nghiên cứu của tôi).
Trong Thống Kê, việc sử dụng \(l_1\) regularization còn được gọi là LASSO (Least Absolute Shrinkage and Selection Operator).
Khi cả \(l_2\) và \(l_1\) regularization được sử dụng, ta có mô hình gọi là Elastic Net Regression.
3.6. Regularization trong sklearn
Trong sklearn, ví dụ Logistic Regression, bạn cũng có thể sử dụng các \(l_1\) và \(l_2\) regularizations bằng cách khai báo biến penalty='l1' hoặc penalty = 'l2' và biến C, trong đó C là nghịch đảo của \(\lambda\). Trong các bài trước khi chưa nói về Overfitting và Regularization, tôi có sử dụng C = 1e5 để chỉ ra rằng \(\lambda\) là một số rất nhỏ.
4. Các phương pháp khác
Ngoài các phương pháp đã nêu ở trên, với mỗi mô hình, nhiều phương pháp tránh overfitting khác cũng được sử dụng. Điển hình là Dropout trong Deep Neural Networks mới được đề xuất gần đây. Một cách ngắn gọn, dropout là một phương pháp tắt ngẫu nhiên các units trong Networks. Tắt tức cho các unit giá trị bằng không và tính toán feedforward và backpropagation bình thường trong khi training. Việc này không những giúp lượng tính toán giảm đi mà còn làm giảm việc overffitng. Tôi xin được quay lại vấn đề này nếu có dịp nói sâu về Deep Learning trong tương lai.
Bạn đọc có thể tìm đọc thêm với các từ khóa: pruning (tránh overfitting trong Decision Trees), VC dimension (đo độ phức tạp của mô hình, độ phức tạp càng lớn thì càng dễ bị overfitting).
5. Tóm tắt nội dung
-
Một mô hình mô tốt là mộ mô hình có tính tổng quát, tức mô tả được dữ liệu cả trong lẫn ngoài tập training. Mô hình chỉ mô tả tốt dữ liệu trong tập training được gọi là overfitting.
-
Để tránh overfitting, có rất nhiều kỹ thuật được sử dụng, điển hình là cross-validation và regularization. Trong Neural Networks, weight decay và dropout thường được dùng.
6. Tài liệu tham khảo
[2] Cross-validation - Wikipedia
[3] Pattern Recognition and Machine Learning
[4] Krogh, Anders, and John A. Hertz. “A simple weight decay can improve generalization.” NIPS. Vol. 4. 1991.
[5] Srivastava, Nitish, et al. “Dropout: A Simple Way to Prevent Neural Networks from Overfitting” Journal of Machine Learning Research 15.1 (2014): 1929-1958.