
Trong trang này:
- 1. Giới thiệu
- 2. Linear Discriminant Analysis cho bài toán với 2 classes
- 3. Linear Discriminant Analysis cho multi-class classification problems
- 4. Ví dụ trên Python
- 5.Thảo luận
- 6. Tài liệu tham khảo
1. Giới thiệu
Trong hai bài viết trước, tôi đã giới thiệu về thuật toán giảm chiều dữ liệu được sử dụng rộng rãi nhất - Principle Component Analysis (PCA). Như đã đề cập, PCA là một phương pháp thuộc loại unsupervised learning, tức là nó chỉ sử dụng các vector mô tả dữ liệu mà không dùng tới labels, nếu có, của dữ liệu. Trong bài toán classification, dạng điển hình nhất của supervised learning, việc sử dụng labels sẽ mang lại kết quả phân loại tốt hơn.
Nhắc lại một lần nữa, PCA là phương pháp giảm chiều dữ liệu sao cho lượng thông tin về dữ liệu, thể hiện ở tổng phương sai, được giữ lại là nhiều nhất. Tuy nhiên, trong nhiều trường hợp, ta không cần giữ lại lượng thông tin lớn nhất mà chỉ cần giữ lại thông tin cần thiết cho riêng bài toán. Xét ví dụ về bài toán phân lớp với 2 classes được mô tả trong Hình 1.
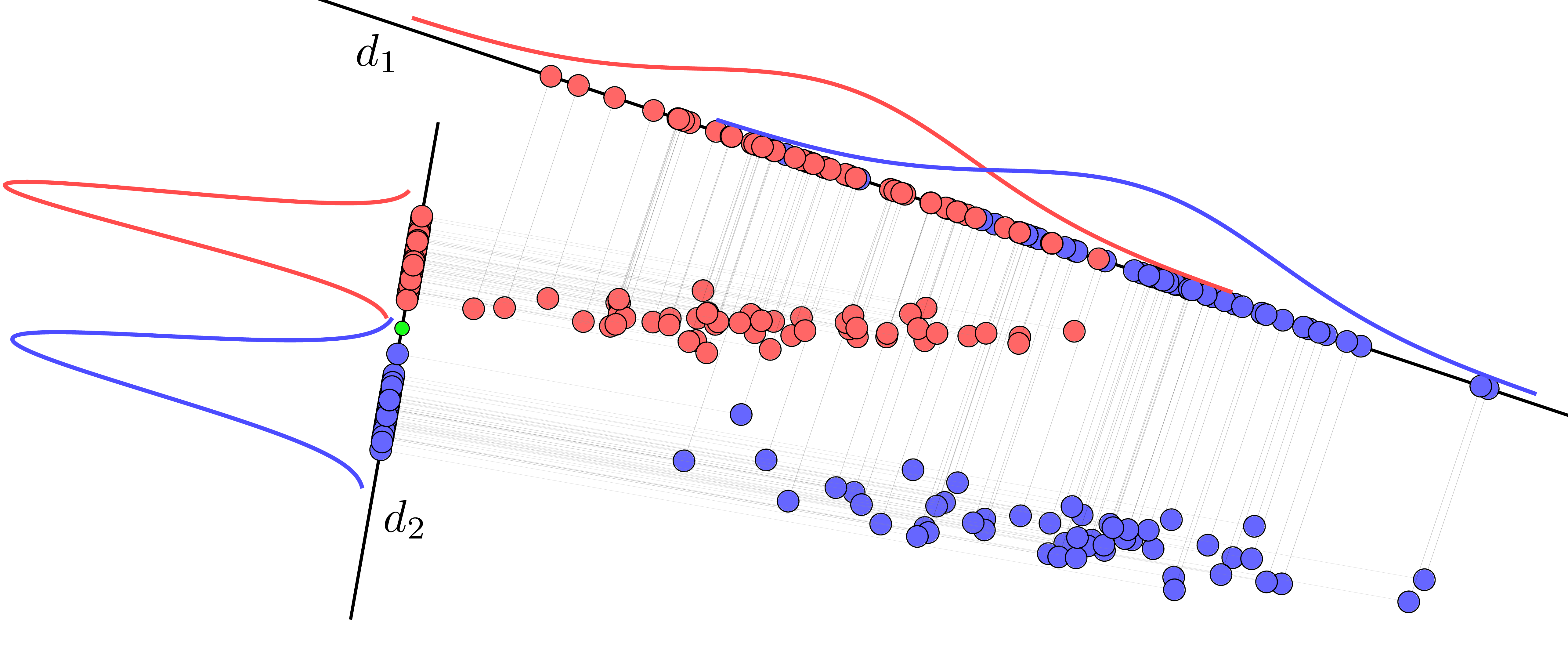
Trong Hình 1, ta giả sử rằng dữ liệu được chiếu lên 1 đường thẳng và mỗi điểm được đại diện bởi hình chiếu của nó lên đường thẳng kia. Như vậy, từ dữ liệu nhiều chiều, ta đã giảm nó về 1 chiều. Câu hỏi đặt ra là, đường thẳng cần có phương như thế nào để hình chiếu của dữ liệu trên đường thẳng này giúp ích cho việc classification nhất? Việc classification đơn giản nhất có thể được hiểu là việc tìm ra một ngưỡng giúp phân tách hai class một cách đơn giản và đạt kết quả tốt nhất.
Xét hai đường thằng \(d_1\) và \(d_2\). Trong đó phương của \(d_1\) gần với phương của thành phần chính nếu làm PCA, phương của \(d_2\) gần với phương của thành phần phụ tìm được bằng PCA. Nếu ra làm giảm chiều dữ liệu bằng PCA, ta sẽ thu được dữ liệu gần với các điểm được chiếu lên \(d_1\). Lúc này việc phân tách hai class trở nên phức tạp vì các điểm đại diện cho hai classes chồng lấn lên nhau. Ngược lại, nếu ta chiếu dữ liệu lên đường thẳng gần với thành phần phụ tìm được bởi PCA, tức \(d_2\), các điểm hình chiếu nằm hoàn toàn về hai phía khác nhau của điểm màu lục trên đường thẳng này. Với bài toán classification, việc chiếu dữ liệu lên \(d_2\) vì vậy sẽ mang lại hiệu quả hơn. Việc phân loại một điểm dữ liệu mới sẽ được xác định nhanh chóng bằng cách so sánh hình chiếu của nó lên \(d_2\) với điểm màu xanh lục này.
Qua ví dụ trên ta thấy, không phải việc giữ lại thông tin nhiều nhất sẽ luôn mang lại kết quả tốt nhất. Chú ý rằng kết quả của phân tích trên đây không có nghĩa là thành phần phụ mang lại hiệu quả tốt hơn thành phần chính, nó chỉ là một trường hợp đặc biệt. Việc chiếu dữ liệu lên đường thẳng nào cần nhiều phân tích cụ thể hơn nữa. Cũng xin nói thêm, hai đường thằng \(d_1\) và \(d_2\) trên đây không vuông góc với nhau, tôi chỉ chọn ra hai hướng gần với các thành phần chính và phụ của dữ liệu để minh hoạ. Nếu bạn cần đọc thêm về thành phần chính/phụ, bạn sẽ thấy Bài 27 và Bài 28 về Principal Component Analysis (Phân tích thành phần chính) có ích.
Linear Discriminant Analysis (LDA) được ra đời nhằm giải quyết vấn đề này. LDA là một phương pháp giảm chiều dữ liệu cho bài toán classification. LDA có thể được coi là một phương pháp giảm chiều dữ liệu (dimensionality reduction), và cũng có thể được coi là một phương pháp phân lớp (classification), và cũng có thể được áp dụng đồng thời cho cả hai, tức giảm chiều dữ liệu sao cho việc phân lớp hiệu quả nhất. Số chiều của dữ liệu mới là nhỏ hơn hoặc bằng \(C-1\) trong đó \(C\) là số lượng classes. Từ ‘Discriminant’ được hiểu là những thông tin đặc trưng cho mỗi class, khiến nó không bị lẫn với các classes khác. Từ ‘Linear’ được dùng vì cách giảm chiều dữ liệu được thực hiện bởi một ma trận chiếu (projection matrix), là một phép biến đổi tuyến tính (linear transform).
Trong Mục 2 dưới đây, tôi sẽ trình bày về trường hợp binary classification, tức có 2 classes. Mục 3 sẽ tổng quát lên cho trường hợp với nhiều classes hơn 2. Mục 4 sẽ có các ví dụ và code Python cho LDA.
2. Linear Discriminant Analysis cho bài toán với 2 classes
2.1. Ý tưởng cơ bản
Mọi phương pháp classification đều được bắt đầu với bài toán binary classification, và LDA cũng không phải ngoại lệ.
Quay lại với Hinh 1, các đường hình chuông thể hiện đồ thị của các hàm mật độ xác suất (probability density function - pdf) của dữ liệu được chiếu xuống theo từng class. Phân phối chuẩn ở đây được sử dụng như là một đại diện, dữ liệu không nhất thiết luôn phải tuân theo phân phối chuẩn.
Độ rộng của mỗi đường hình chuông thể hiện độ lệch chuẩn của dữ liệu. Dữ liệu càng tập trung thì độ lệch chuẩn càng nhỏ, càng phân tán thì độ lệch chuẩn càng cao. Khi được chiếu lên \(d_1\), dữ liệu của hai classes bị phân tán quá nhiều, khiến cho chúng bị trộn lẫn vào nhau. Khi được chiếu lên \(d_2\), mỗi classes đều có độ lệch chuẩn nhỏ, khiến cho dữ liệu trong từng class tập trung hơn, dẫn đến kết quả tốt hơn.
Tuy nhiên, việc độ lệch chuẩn nhỏ trong mỗi class chưa đủ để đảm bảo độ Discriminant của dữ liệu. Xét các ví dụ trong Hình 2.
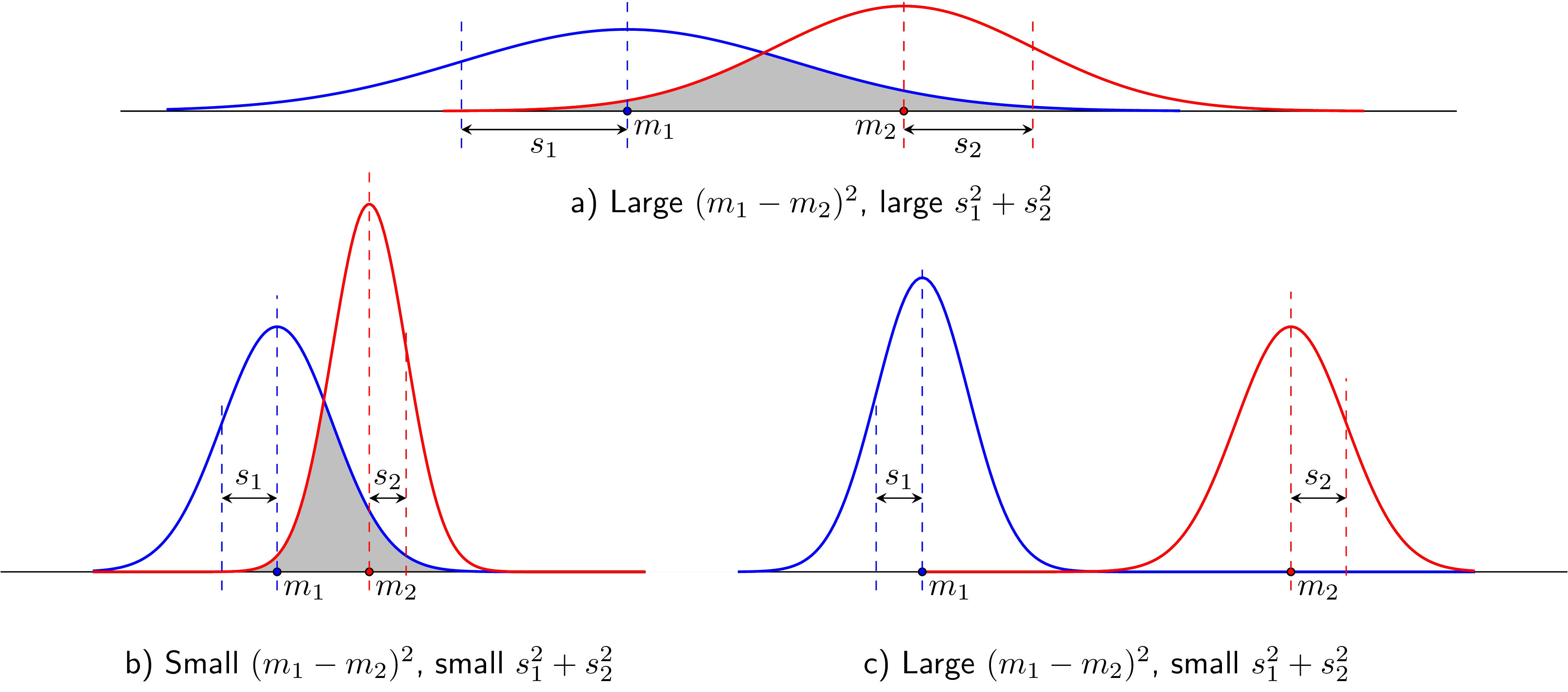
Hình 2a) giống với dữ liệu khi chiếu lên \(d_1\) ở Hình 1. Cả hai class đều quá phân tán khiến cho tỉ lệ chồng lấn (phần diện tích màu xám) là lớn, tức dữ liệu chưa thực sự discriminative.
Hình 2b) là trường hợp khi độ lệch chuẩn của hai class đều nhỏ, tức dữ liệu tập trung hơn. Tuy nhiên, vấn đề với trường hợp này là khoảng cách giữa hai class, được đo bằng khoảng cách giữa hai kỳ vọng \(m_1\) và \(m_2\), là quá nhỏ, khiến cho phần chồng lấn cũng chiếm môt tỉ lệ lớn, và tất nhiên, cũng không tốt cho classification.
Hình 2c) là trường hợp khi hai độ lệch chuẩn là nhỏ và khoảng cách giữa hai kỳ vọng là lớn, phần chống lấn nhỏ không đáng kể.
Có thể bạn đang tự hỏi, độ lệch chuẩn và khoảng cách giữa hai kỳ vọng đại diện cho các tiêu chí gì:
-
Như đã nói, độ lệch chuẩn nhỏ thể hiện việc dữ liệu ít phân tán. Điều này có nghĩa là dữ liệu trong mỗi class có xu hướng giống nhau. Hai phương sai \(s_1^2, s_2^2\) còn được gọi là các within-class variances.
-
Khoảng cách giữa các kỳ vọng là lớn chứng tỏ rằng hai classes nằm xa nhau, tức dữ liệu giữa các classes là khác nhau nhiều. Bình phương khoảng cách giữa hai kỳ vọng \((m_1 - m_2)^2\) còn được gọi là between-class variance.
Hai classes được gọi là discriminative nếu hai class đó cách xa nhau (between-class variance lớn) và dữ liệu trong mỗi class có xu hướng giống nhau (within-class variance nhỏ). Linear Discriminant Analysis là thuật toán đi tìm một phép chiếu sao cho tỉ lệ giữa between-class variance và within-class variance lớn nhất có thể.
2.2. Xây dựng hàm mục tiêu
Giả sử rằng có \(N\) điểm dữ liệu \(\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_N\) trong đó \(N_1 < N\) điểm đầu tiên thuộc class thứ nhất, \(N_2 = N - N_1\) điểm cuối cùng thuộc class thứ hai. Ký hiệu \(\mathcal{C}_1 = \{n | 1 \leq n \leq N_1\}\) là tập hợp các chỉ số của các điểm thuộc class 1 và \(\mathcal{C}_2 = \{m| N_1 + 1 \leq m \leq N\})\) là tập hợp các chỉ số của các điểm thuộc class 2. Phép chiếu dữ liệu xuống 1 đường thẳng có thể được mô tả bằng một vector hệ số \(\mathbf{w}\), giá trị tương ứng của mỗi điểm dữ liệu mới được cho bởi: \[ y_n = \mathbf{w}^T\mathbf{x}_n, 1 \leq n \leq N \]
Vector kỳ vọng của mỗi class: \[ \mathbf{m}_k = \frac{1}{N_k}\sum_{n \in \mathcal{C}_k}\mathbf{x}_n,~~~ k = 1, 2 ~~~~ (1) \]
Khi đó: \[ m_1 - m_2 = \frac{1}{N_1}\sum_{i \in \mathcal{C}_1}y_i - \frac{1}{N_2}\sum_{j \in \mathcal{C}_2}y_j = \mathbf{w}^T(\mathbf{m}_1 - \mathbf{m}_2) ~~~~ (2) \]
Các within-class variances được định nghĩa là: \[ s_k^2 = \sum_{n \in \mathcal{C}_k} (y_n - m_k)^2, ~~ k = 1, 2 ~~~~ (3) \]
Chú ý rằng các within-class variances ở đây không được lấy trung bình như variance thông thường. Điều này được lý giải là tầm quan trọng của mỗi within-class variance nên tỉ lệ thuận với số lượng điểm dữ liệu trong class đó, tức within-class variance bằng variance nhân với số điểm trong class đó. Thế nên ta không chia trung bình nữa.
LDA là thuật toán đi tìm giá trị lớn nhất của hàm mục tiêu: \[ J(\mathbf{w}) = \frac{(m_1 - m_2)^2}{s_1^2 + s_2^2} ~~~~~~~~~ (4) \]
Tiếp theo, chúng ta sẽ đi tìm biểu thức phụ thuộc giữa tử số và mẫu số trong vế phải của \((4)\) vào \(\mathbf{w}\).
Với tử số: \[ \begin{eqnarray} (m_1 - m_2)^2 = \mathbf{w}^T \underbrace{(\mathbf{m}_1 - \mathbf{m}_2)(\mathbf{m}_1 - \mathbf{m}_2)^T}_{\mathbf{S}_B} \mathbf{w} = \mathbf{w}^T\mathbf{S}_B \mathbf{w} ~~~~ (5) \end{eqnarray} \] \(\mathbf{S}_B\) còn được gọi là between-class covariance matrix. Đây là một ma trận đối xứng nửa xác định dương.
Với mẫu số:
\[ \begin{eqnarray} s_1^2 + s_2^2 &=& \sum_{k=1}^2 \sum_{n \in \mathcal{C}_k} \left(\mathbf{w}^T(\mathbf{x}_n - \mathbf{m}_k)\right)^2 \newline &=&\mathbf{w}^T \underbrace{\sum_{k=1}^2 \sum_{n \in \mathcal{C}_k} (\mathbf{x}_n - \mathbf{m}_k)(\mathbf{x}_n - \mathbf{m}_k)^T}_{\mathbf{S}_W} \mathbf{w} = \mathbf{w}^T\mathbf{S}_W \mathbf{w}~~~~~(6) \end{eqnarray} \] \(\mathbf{S}_W\) còn được gọi là within-class covariance matrix. Đây cũng là một ma trận đối xứng nửa xác định dương vì nó là tổng của hai ma trận đối xứng nửa xác định dương.
Trong \((5)\) và \((6)\), ta đã sử dụng đẳng thức: \[ (\mathbf{a}^T\mathbf{b})^2 = (\mathbf{a}^T\mathbf{b})(\mathbf{a}^T\mathbf{b}) = \mathbf{a}^T\mathbf{b}\mathbf{b}^T\mathbf{a} \] với \(\mathbf{a}, \mathbf{b}\) là hai vectors cùng chiều bất kỳ.
Như vậy, bài toán tối ưu cho LDA trở thành: \[ \mathbf{w} = \arg\max_{\mathbf{w}}\frac{\mathbf{w}^T\mathbf{S}_B \mathbf{w}}{\mathbf{w}^T\mathbf{S}_W\mathbf{w}} ~~~~~~~~ (7) \]
2.3. Nghiệm của bài toán tối ưu
Nghiệm \(\mathbf{w}\) của \((7)\) sẽ là nghiệm của phương trình đạo hàm hàm mục tiêu bằng 0. Sử dụng chain rule cho đạo hàm hàm nhiều biến và công thức \(\nabla_{\mathbf{w}}\mathbf{w} \mathbf{A}\mathbf{w} = 2\mathbf{Aw}\) nếu \(\mathbf{A}\) là một ma trận đối xứng, ta có:
\[ \begin{eqnarray} \nabla_{\mathbf{w}} J(\mathbf{w}) &=& \frac{1}{(\mathbf{w}^T\mathbf{S}_{W}\mathbf{w})^2} \left( 2\mathbf{S}_B \mathbf{w} (\mathbf{w}^T\mathbf{S}_{W}\mathbf{w}) - 2\mathbf{w}^T\mathbf{S}_{B}\mathbf{w}^T\mathbf{S}_W \mathbf{w} \right) = \mathbf{0}& (8)\newline \Leftrightarrow \mathbf{S}_B\mathbf{w} &=& \frac{\mathbf{w}^T\mathbf{S}_B \mathbf{w}}{\mathbf{w}^T\mathbf{S}_W\mathbf{w}}\mathbf{S}_W\mathbf{w}& (9) \newline \mathbf{S}_W^{-1}\mathbf{S}_B \mathbf{w} &=& J(\mathbf{w})\mathbf{w} & (10) \end{eqnarray} \]
Lưu ý: Trong \((10)\), ta đã giả sử rằng ma trận \(\mathbf{S}_W\) là khả nghịch. Điều này không luôn luôn đúng, nhưng có một trick nhỏ là ta có thể xấp xỉ \(\mathbf{S}_W\) bởi \( \bar{\mathbf{S}}_W \approx \mathbf{S}_W + \lambda\mathbf{I}\) với \(\lambda\) là một số thực dương nhỏ. Ma trận mới này là khả nghịch vì trị riêng nhỏ nhất của nó bằng với trị riêng nhỏ nhất của \(\mathbf{S}_W\) cộng với \(\lambda\) tức không nhỏ hơn \(\lambda > 0\). Điều này được suy ra từ việc \(\mathbf{S}_W\) là một ma trận nửa xác định dương. Từ đó suy ra \(\bar{\mathbf{S}}_W\) là một ma trận xác định dương vì mọi trị riêng của nó là thực dương, và vì thế, nó khả nghịch. Khi tính toán, ta có thể sử dụng nghịch đảo của \(\bar{\mathbf{S}}_W\).
Kỹ thuật này được sử dụng rất nhiều khi ta cần sử dụng nghịch đảo của một ma trận nửa xác định dương và chưa biết nó có thực sự là xác định dương hay không.
Quay trở lại với \((10)\), vì \(J(\mathbf{w})\) là một số vô hướng, ta suy ra \(\mathbf{w}\) phải là một vector riêng của \(\mathbf{S}_W^{-1}\mathbf{S}_B\) ứng với một trị riêng nào đó. Hơn nữa, giá trị của trị riêng này bằng với \(J(\mathbf{w})\). Vậy, để hàm mục tiêu là lớn nhất thì \(J(\mathbf{w})\) chính là trị riêng lớn nhất của \(\mathbf{S}_W^{-1}\mathbf{S}_B\). Dấu bằng xảy ra khi \(\mathbf{w}\) là vector riêng ứng với trị riêng lớn nhất đó. Bạn đọc có thể hiểu phần này hơn khi xem cách lập trình trên Python ở Mục 4.
Từ có thể thấy ngay rằng nếu \(\mathbf{w}\) là nghiệm của \((7)\) thì \(k\mathbf{w}\) cũng là nghiệm với \(k\) là số thực khác không bất kỳ. Vậy ta có thể chọn \(\mathbf{w}\) sao cho \((\mathbf{m}_1 - \mathbf{m}_2)^T\mathbf{w} = J(\mathbf{w}) = L =\) trị riêng lớn nhất của \(\mathbf{S}_W^{-1}\mathbf{S}_B\) . Khi đó, thay định nghĩa của \(\mathbf{S}_B\) ở \((5)\) vào \((10)\) ta có:
\[ L \mathbf{w} = \mathbf{S}_{W}^{-1}(\mathbf{m}_1 - \mathbf{m}_2)\underbrace{(\mathbf{m}_1 - \mathbf{m}_2)^T\mathbf{w}}_L = L\mathbf{S}_{W}^{-1}(\mathbf{m}_1 - \mathbf{m}_2) \] Điều này có nghĩa là ta có thể chọn: \[ \mathbf{w} = \alpha\mathbf{S}_{W}^{-1}(\mathbf{m}_1 - \mathbf{m}_2) ~~~~ (11) \] với \(\alpha \neq 0\) bất kỳ.
Biểu thức \((11)\) còn được biết như là Fisher’s linear discriminant, được đặt theo tên nhà khoa học Ronald Fisher.
3. Linear Discriminant Analysis cho multi-class classification problems
3.1. Xây dựng hàm mất mát
Trong mục này, chúng ta sẽ xem xét trường hợp tổng quát khi có nhiều hơn 2 classes. Giả sử rằng chiều của dữ liệu \(D\) lớn hơn số lượng classes \(C\).
Giả sử rằng chiều mà chúng ta muốn giảm về là \(D’ < D\) và dữ liệu mới ứng với mỗi điểm dữ liệu \(\mathbf{x}\) là: \[ \mathbf{y} = \mathbf{W}^T\mathbf{x} \] với \(\mathbf{W} \in \mathbb{R}^{D\times D’}\).
Chú ý rằng LDA ở đây không sử dụng bias.
Một vài ký hiệu:
-
\(\mathbf{X}_k, \mathbf{Y}_k = \mathbf{W}^T\mathbf{X}_k\) lần lượt là ma trận dữ liệu của class \(k\) trong không gian ban đầu và không gian mới với số chiều nhỏ hơn.
-
\(\mathbf{m}_k = \frac{1}{N_k}\sum_{n \in \mathcal{C}_k}\mathbf{x}_k \in \mathbb{R}^{D}\) là vector kỳ vọng của class \(k\) trong không gian ban đầu.
-
\(\mathbf{e}_k = \frac{1}{N_k}\sum_{n \in \mathcal{C}_k} \mathbf{y}_n = \mathbf{W}^T\mathbf{m}_k \in \mathbb{R}^{D’}\) là vector kỳ vọng của class \(k\) trong không gian mới.
-
\(\mathbf{m}\) là vector kỳ vọng của toàn bộ dữ liệu trong không gian ban đầu và \(\mathbf{e}\) là vector kỳ vọng trong không gian mới.
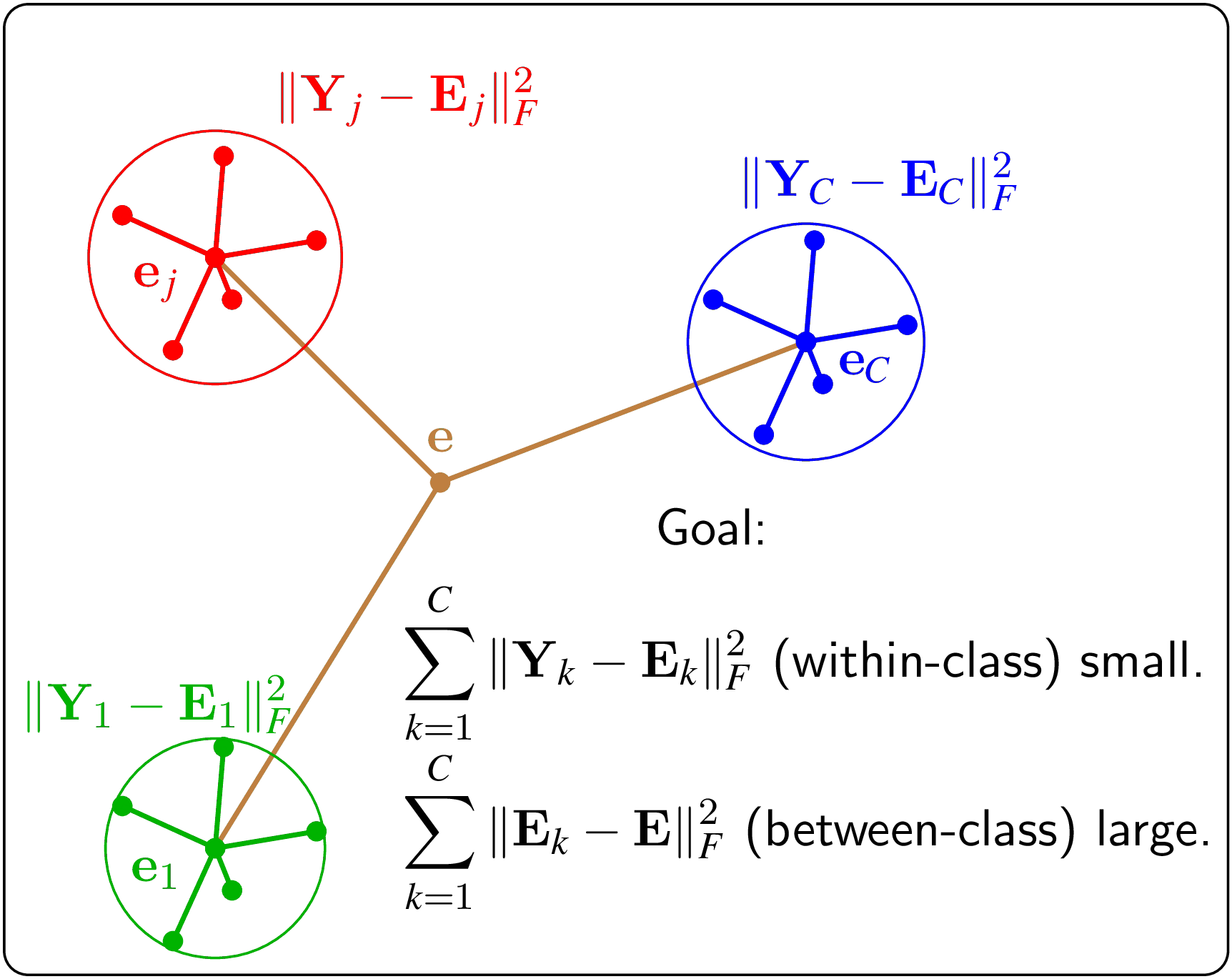
Một trong những cách xây dựng hàm mục tiêu cho multi-class LDA được minh họa trong Hình 3.
|
Hình 3: LDA cho multi-class classification problem. Mục đích cũng là sự khác nhau giữa các thành phần trong 1 class (within-class) là nhỏ và sự khác nhau giữa các classes là lớn. Các điểm dữ liệu có màu khác nhau thể hiện các class khác nhau. |
Độ phân tán của một tập hợp dữ liệu có thể được coi như tổng bình phương khoảng cách từ mỗi điểm tới vector kỳ vọng của chúng. Nếu tất cả các điểm đều gần vector kỳ vọng của chúng thì độ phân tán của tập dữ liệu đó được coi là nhỏ. Ngược lại, nếu tổng này là lớn, tức trung bình các điểm đều xa trung tâm, tập hợp này có thể được coi là có độ phân tán cao.
Dựa vào nhận xét này, ta có thể xây dựng các đại lượng:
3.1.1. Within-class nhỏ
Within-class variance của class \(k\) có thể được tính như sau: \[ \begin{eqnarray} \sigma_k^2 &=& \sum_{n \in \mathcal{C}_k} ||\mathbf{y}_n -\mathbf{e}_k||_F^2 = ||\mathbf{Y}_k - \mathbf{E}_k||_2^2 & (15) \newline &=& ||\mathbf{W}^T (\mathbf{X}_k - \mathbf{M}_k) ||_F^2 & (16)\newline &=& \text{trace}\left(\mathbf{W}^T (\mathbf{X}_k - \mathbf{M}_k)(\mathbf{X}_k - \mathbf{M}_k)^T \mathbf{W}\right) \end{eqnarray} \] Với \(\mathbf{E}_k\) một ma trận có các cột giống hệt nhau và bằng với vector kỳ vọng \(\mathbf{e}_k\). Có thể nhận thấy \( \mathbf{E}_k = \mathbf{W}^T\mathbf{M}_k\) với \(\mathbf{M}_k\) là ma trận có các cột giống hệt nhau và bằng với vector kỳ vọng \(\mathbf{m}_k\) trong không gian ban đầu.
Vậy đại lượng đo within-class trong multi-class LDA có thể được đo bằng: \[ \begin{eqnarray} s_W = \sum_{k = 1}^C \sigma_k^2 &=& \sum_{k=1}^C \text{trace}\left(\mathbf{W}^T (\mathbf{X}_k - \mathbf{M}_k)(\mathbf{X}_k - \mathbf{M}_k)^T \mathbf{W}\right)& (17)\newline &=& \text{trace}\left( \mathbf{W}^T\mathbf{S}_W \mathbf{W}\right) & (18) \end{eqnarray} \] với: \[ \mathbf{S}_W = \sum_{k=1}^C ||\mathbf{X}_k- \mathbf{M}_k ||_F^2 = \sum_{k=1}^C \sum_{n \in \mathcal{C}_k} (\mathbf{x}_n - \mathbf{m}_k)(\mathbf{x}_n - \mathbf{m}_k)^T ~~~~~(19) \] và nó có thể được coi là within-class covariance matrix của multi-class LDA. Ma trận \(\mathbf{S}_B\) này là một ma trận nửa xác định dương theo định nghĩa.
3.1.2. Between-class lớn
Việc betwwen-class lớn, như đã đề cập, có thể đạt được nếu tất cả các điểm trong không gian mới đều xa vector kỳ vọng chung \(\mathbf{e}\). Việc này cũng có thể đạt được nếu các vector kỳ vọng của mỗi class xa các vector kỳ vọng chung (trong không gian mới). Vậy ta có thể định nghĩa đại lượng between-class như sau: \[ s_B = \sum_{k=1}^C N_k ||\mathbf{e}_k - \mathbf{e} ||_F^2 = \sum_{k=1}^C ||\mathbf{E}_k - \mathbf{E} ||_F^2~~~~~ (20) \] Ta lấy \(N_k\) làm trọng số vì có thể có những class có nhiều phần tử so với các classes còn lại.
Chú ý rằng ma trận \(\mathbf{E}\) có thể có số cột linh động, phụ thuộc vào số cột của ma trận \(\mathbf{E}_k\) mà nó đi cùng (và bằng \(N_k\)).
Lập luận tương tự như \((17), (18)\), bạn đọc có thể chứng minh được: \[ s_B = \text{trace} \left(\mathbf{W}^T \mathbf{S}_B \mathbf{W} \right) ~~~ (21) \]
với: \[ \mathbf{S}_B = \sum_{k = 1}^C (\mathbf{M}_k - \mathbf{M})(\mathbf{M}_k - \mathbf{M})^T = \sum_{k=1}^C N_k (\mathbf{m}_k - \mathbf{m})(\mathbf{m}_k - \mathbf{m})^T ~~~~~ (22) \]
và số cột của ma trận \(\mathbf{M}\) cũng linh động theo số cột của \(\mathbf{M}_k\). Ma trận này là tổng của các ma trận đối xứng nửa xác định dương, nên nó là một ma trận đối xứng nửa xác định dương.
3.2. Hàm mất mát cho multi-class LDA
Với cách định nghĩa và ý tưởng về within-class nhỏ và between-class lớn như trên, ta có thể xây dựng bài toán tối ưu:
\[ \mathbf{W} = \arg\max_{\mathbf{W}}J(\mathbf{W}) = \arg\max_{\mathbf{W}} \frac{\text{trace}(\mathbf{W}^T\mathbf{S}_B\mathbf{W})}{\text{trace}(\mathbf{W}^T\mathbf{S}_W\mathbf{W})} \]
Nghiệm cũng được tìm bằng cách giải phương trình đạo hàm hàm mục tiêu bằng 0. Nhắc lại về đạo hàm của hàm \(\text{trace}\) theo ma trận: \[ \nabla_{\mathbf{W}} \text{trace}(\mathbf{W}^T\mathbf{A} \mathbf{W}) = 2\mathbf{A}\mathbf{W} \] với \(\mathbf{A} \in \mathbb{R}^{D \times D}\) là một ma trận đối xứng. (Xem trang 597 của tài liệu này).
Với cách tính tương tự như \((8) - (10)\), ta có: \[ \begin{eqnarray} \nabla_{\mathbf{W}} J(\mathbf{W}) &=& \frac{2 \left( \mathbf{S}_B\mathbf{W} \text{trace}(\mathbf{W}^T\mathbf{S}_W\mathbf{W}) - \text{trace}(\mathbf{W}^T\mathbf{S}_B\mathbf{W})\mathbf{S}_W \mathbf{W} \right)}{\left(\text{trace}(\mathbf{W}^T\mathbf{S}_W\mathbf{W})\right)^2} = \mathbf{0} & (23)\newline \Leftrightarrow \mathbf{S}_W^{-1}\mathbf{S}_B\mathbf{W}&=& J \mathbf{W} & (24) \end{eqnarray} \]
Từ đó suy ra mỗi cột của \(\mathbf{W}\) là một vector riêng của \(\mathbf{S}_W^{-1} \mathbf{S}_B\) ứng với trị riêng lớn nhất của ma trận này.
Nhận thấy rằng các cột của \(\mathbf{W}\) cần phải độc lập tuyến tính. Vì nếu không, dữ liệu trong không gian mới \(\mathbf{y} = \mathbf{W}^T\mathbf{x}\) sẽ phụ thuộc tuyến tính và có thể tiếp tục được giảm số chiều mà không ảnh hưởng gì.
Vậy các cột của \(\mathbf{W}\) là các vector độc lập tuyến tính ứng với trị riêng cao nhất của \(\mathbf{S}_W^{-1} \mathbf{S}_B\). Câu hỏi đặt ra là: Có nhiều nhất bao nhiêu vector riêng độc lập tuyến tính ứng với trị riêng lớn nhất của \(\mathbf{S}_W^{-1} \mathbf{S}_B\)?
Số lượng lớn nhất các vector riêng độc lập tuyến tính ứng với 1 trị riêng chính là rank của không gian riêng ứng với trị riêng đó, và không thể lớn hơn rank của ma trận.
Ta có một bổ đề quan trọng:
Bổ đề: \[ \text{rank}(\mathbf{S}_B) \leq C - 1 ~~~~~~ (23) \]
Chứng minh: (Tuy nhiên, việc chứng minh này không thực sự quan trọng, chỉ phù hợp với những bạn muốn hiểu sâu)
Viết lại \((22)\) dưới dạng: \[ \mathbf{S}_B = \mathbf{P}\mathbf{P}^T \] với \(\mathbf{P} \in {R}^{D \times C}\) mà cột thứ \(k\) cuả nó là: \[ \mathbf{p}_k = \sqrt{N_k} (\mathbf{m}_k - \mathbf{m}) \]
Thêm nữa, cột cuối cùng là một tổ hợp tuyến tính của các cột còn lại. Lý do là: \[ \mathbf{m}_C - \mathbf{m} = \mathbf{m}_C - \frac{\sum_{k=1}^C N_k \mathbf{m}_k}{N} = \sum_{k=1}^{C-1} \frac{N_k}{N} (\mathbf{m}_k - \mathbf{m}) \]
Như vậy ma trận \(\mathbf{P}\) có nhiều nhất \(C-1\) cột độc lập tuyến tính, vậy nên rank của nó không vượt quá \(C -1\).
Cuối cùng, \(\mathbf{S}_B\) là tích của hai ma trận với rank không quá \(C-1\), nên \(\text{rank}(\mathbf{S}_B)\) không vượt quá \(C-1\). \(~~~~~~\square\).
Nếu bạn cần ôn lại vài kiến thức về rank:
-
Hạng (rank) của một ma trận, không nhất thiết vuông, là số lượng lớn nhất các cột độc lập tuyến tính của ma trận đó. Vậy nên rank của một ma trận không thể lớn hơn số cột của ma trận đó.
-
\(\text{rank}(\mathbf{A}) = \text{rank}(\mathbf{A}^T)\). Vậy nên số lượng lớn nhất các cột độc lập tuyến tính cũng chính bằng số lượng lớn nhất các hàng độc lập tuyến tính.
-
\(\text{rank}(\mathbf{AB}) \leq \min \left\{\text{rank}(\mathbf{A}), \text{rank}(\mathbf{B}) \right\}\) với \(\mathbf{A}, \mathbf{B}\) là hai ma trận bất kỳ có thể nhân với nhau được.
-
\(\text{rank}(\mathbf{A} + \mathbf{B}) \leq \text{rank}(\mathbf{A}) + \text{rank}(\mathbf{B})\) với \(\mathbf{A}, \mathbf{B}\) là hai ma trận cùng chiều bất kỳ.
Từ đó ra có \(\text{rank}\left(\mathbf{S}_W^{-1} \mathbf{S}_B\right) \leq \text{rank}\mathbf{S}_B \leq C - 1\).
Vậy số chiều của không gian mới là một số không lớn hơn \(C-1\). Xem ra số chiều theo multi-class LDA đã được giảm đi rất nhiều. Nhưng chất lượng của dữ liệu mới như thế nào, chúng ta cần làm một vài thí nghiệm.
Tóm lại, nghiệm của bài toán multi-class LDA là các vector riêng độc lập tuyến tính ứng với trị riêng cao nhất của \(\mathbf{S}_W^{-1} \mathbf{S}_B\).
Lưu ý: Có nhiều cách khác nhau để xây dựng hàm mục tiêu cho multi-class LDA dựa trên việc định nghĩa within-class variance nhỏ và between-class variance lớn. Chúng ta đang sử dụng hàm \(\text{trace}\) để đong đếm hai đại lượng này. Có nhiều cách khác nữa, ví dụ như sử dụng định thức. Tuy nhiên, có một điểm chung giữa các cách tiếp cận này là chiều của không gian mới sẽ không vượt quá \(C-1\).
4. Ví dụ trên Python
4.1. LDA với 2 classes
Tạo dữ liệu giả:
# To support both python 2 and python 3
from __future__ import division, print_function, unicode_literals
# list of points
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.backends.backend_pdf import PdfPages
np.random.seed(22)
means = [[0, 5], [5, 0]]
cov0 = [[4, 3], [3, 4]]
cov1 = [[3, 1], [1, 1]]
N0 = 50
N1 = 40
N = N0 + N1
X0 = np.random.multivariate_normal(means[0], cov0, N0) # each row is a data point
X1 = np.random.multivariate_normal(means[1], cov1, N1)
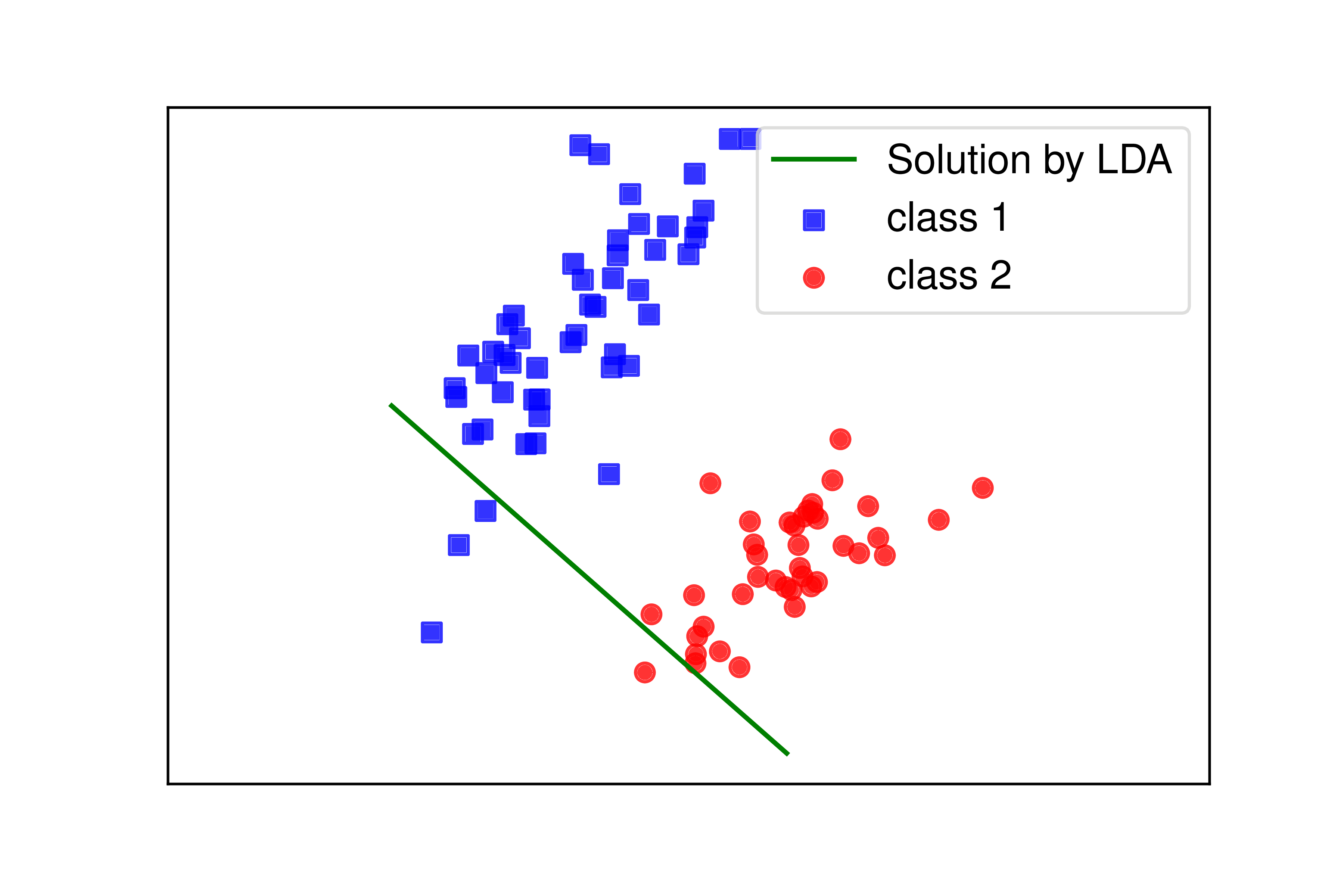
Các điểm cho 2 classes này được minh hoạ bởi các điểm màu lam và đỏ trên Hình 4.
Tiếp theo, chúng ta đi tính các within-class và between-class covariance matrices:
# Build S_B
m0 = np.mean(X0.T, axis = 1, keepdims = True)
m1 = np.mean(X1.T, axis = 1, keepdims = True)
a = (m0 - m1)
S_B = a.dot(a.T)
# Build S_W
A = X0.T - np.tile(m0, (1, N0))
B = X1.T - np.tile(m1, (1, N1))
S_W = A.dot(A.T) + B.dot(B.T)
Nghiệm của bài toán là vector riêng ứng với trị riêng lớn nhất của np.linalg.inv(S_W).dot(S_B)
_, W = np.linalg.eig(np.linalg.inv(S_W).dot(S_B))
w = W[:,0]
print(w)
[ 0.75091074 -0.66040371]
Đường thẳng có phương w được minh hoạ bởi đường màu lục trên Hình 4. Ta thấy rằng nghiệm này hợp lý với dữ liệu có được.
|
Hình 4: Ví dụ minh hoạ về LDA trong không gian 2 chiều. Đường thẳng màu lục là đường thẳng mà dữ liệu sẽ được chiếu lên. Ta có thể thấy rằng, nếu chiếu lên được thẳng này, dữ liệu của hai classes sẽ nằm về hai phía của một điểm trên đường thẳng đó. |
Để kiểm chứng độ chính xác của nghiệm tìm được, ta cùng so sánh nó với nghiệm tìm được bởi thư viện sklearn.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
X = np.concatenate((X0, X1))
y = np.array([0]*N0 + [1]*N1)
clf = LinearDiscriminantAnalysis()
clf.fit(X, y)
print(clf.coef_/np.linalg.norm(clf.coef_)) # normalize
[[ 0.75091074 -0.66040371]]
Ta thấy rằng nghiệm tìm theo công thức và nghiệm tìm theo thư viện là như nhau. Như vậy việc phân tích ở Mục 2 là hoàn toàn chính xác.
Một ví dụ khác so sánh PCA và LDA có thể được tìm thấy tại đây: Comparison of LDA and PCA 2D projection of Iris dataset.
5.Thảo luận
-
LDA là một phương pháp giảm chiều dữ liệu có sử dụng thông tin về label của dữ liệu. LDA là một thuật toán supervised.
-
Ý tưởng cơ bản của LDA là tìm một không gian mới với số chiều nhỏ hơn không gian ban đầu sao cho hình chiếu của các điểm trong cùng 1 class lên không gian mới này là gần nhau trong khi hình chiếu của các điểm của các classes khác nhau là khác nhau.
-
Trong PCA, số chiều của không gian mới có thể là bất kỳ số nào không lớn hơn số chiều và số điểm của dữ liệu. Trong LDA, với bài toán có \(C\) classes, số chiều của không gian mới chỉ có thể không vượt quá \(C-1\).
-
LDA có giả sử ngầm rằng dữ liệu của các classes đều tuân theo phân phối chuẩn và các ma trận hiệp phương sai của các classes là gần nhau.
-
Với bài toán có 2 classes, từ Hình 1 ta có thể thấy rằng hai classes là linearly separable nếu và chỉ nếu tồn tại một đường thẳng và 1 điểm trên đường thẳng đó (điểm mùa lục) sao cho: dữ liệu hình chiếu trên đường thẳng của hai classes nằm về hai phía khác nhau của điểm đó.
-
LDA hoạt động rất tốt nếu các classes là linearly separable, tuy nhiên, chất lượng mô hình giảm đi rõ rệt nếu các classes là không linearly separable. Điều này dễ hiểu vì khi đó, chiếu dữ liệu lên phương nào thì cũng bị chồng lần, và việc tách biệt không thể thực hiện được như ở không gian ban đầu.
-
Mặc dù có hạn chế, ý tưởng về small within-class và large between-class được sử dụng rất nhiều trong các mô hình classification khác. Ví dụ Fisher discrimination dictionary learning for sparse representation - ICCV 2011.
6. Tài liệu tham khảo
[1] Linear discriminant analysis.
[2] Bishop, Christopher M. “Pattern recognition and Machine Learning.”, Springer (2006). Chapter 4. (book)