
Trong trang này:
- 1. Giới thiệu
- 2. Một chút về Đại số tuyến tính
- 3. Singular Value Decomposition
- 4. Một vài ứng dụng của SVD
- 5. Thảo luận
- 6. Tài liệu tham khảo
1. Giới thiệu
Hẳn các bạn vẫn nhớ một loại bài toán được làm rất nhiều khi học Đại số tuyến tính: Bài toán chéo hoá ma trận. Bài toán đó nói rằng: Một ma trận vuông \(\mathbf{A} \in \mathbb{R}^{n\times n}\) được gọi là chéo hoá được (diagonalizable) nếu tồn tại ma trận đường chéo \(\mathbf{D}\) và ma trận khả nghịch \(\mathbf{P}\) sao cho: \[ \mathbf{A} = \mathbf{P} \mathbf{D} \mathbf{P}^{-1}~~~~(1) \] Số lượng phần tử khác 0 của ma trận đường chéo \(\mathbf{D}\) chính là rank của ma trận \(\mathbf{A}\).
Nhân cả hai vế của \((1)\) với \(\mathbf{P}\) ta có:
\[ \mathbf{AP} = \mathbf{PD}~~~~(2) \]
Gọi \(\mathbf{p}_i, \mathbf{d}_i\) lần lượt là cột thứ \(i\) của ma trận \(\mathbf{P}\) và \(\mathbf{D}\). Vì mỗi một cột của vế trái và vế phải của \((2)\) phải bằng nhau, ta sẽ có:
\[ \mathbf{Ap}_i = \mathbf{Pd}_i = d_{ii}\mathbf{p}_i ~~~~ (3) \] với \(d_{ii}\) là phần tử thứ \(i\) của \(\mathbf{p}_i\).
Dấu bằng thứ hai xảy ra vì \(\mathbf{D}\) là ma trận đường chéo, tức \(\mathbf{d}_i\) chỉ có thành phần \(d_{ii}\) là khác 0. Và nếu bạn vẫn nhớ, biểu thức \((3)\) chỉ ra rằng mỗi phần tử \(d_{ii}\) phải là một trị riêng (eigenvalue) của \(\mathbf{A}\) và mỗi vector cột \(\mathbf{p}_i\) phải là một vector riêng (eigenvector) của \(\mathbf{A}\) ứng với trị riêng \(d_{ii}\).
Cách phân tích một ma trận vuông thành nhân tử như \((1)\) còn được gọi là Eigen Decomposition.
Một điểm quan trọng là cách phân tích như \((1)\) chỉ được áp dụng với ma trận vuông và không phải lúc nào cũng tồn tại. Nó chỉ tồn tại nếu ma trận \(\mathbf{A}\) có \(n\) vector riêng độc lập tuyến tính, vì nếu không thì không tồn tại ma trận \(\mathbf{P}\) khả nghịch. Thêm nữa, cách phân tích này cũng không phải là duy nhất vì nếu \(\mathbf{P}, \mathbf{D}\) thoả mãn \((1)\) thì \(k\mathbf{P}, \mathbf{D}\) cũng thoả mãn với \(k\) là một số thực khác 0 bất kỳ.
Việc phân tích một ma trận ra thành tích của nhiều ma trận đặc biệt khác (Matrix Factorization hoặc Matrix Decomposition) mang lại nhiều ích lợi quan trọng mà các bạn sẽ thấy: giảm số chiều dữ liệu, nén dữ liệu, tìm hiểu các đặc tính của dữ liệu, giải các hệ phương trình tuyến tính, clustering, và nhiều ứng dụng khác. Recommendation System cũng là một trong rất nhiều ứng dụng của Matrix Factorization.
Trong bài viết này, tôi sẽ giới thiệu với các bạn một trong những phương pháp Matrix Factorization rất đẹp của Đại số tuyến tính. Phương pháp đó có tên là Singular Value Decomposition (SVD). Các bạn sẽ thấy, mọi ma trận, không nhất thiết là vuông, đều có thể được phân tích thành tích của ba ma trận đặc biệt.
Dưới đây, tôi sẽ phát biểu SVD cũng như các tính chất và ứng dụng điển hình của nó.
Trước hết, chúng ta cần ôn tập lại một chút về Đại số tuyến tính. Chú ý rằng các ma trận trong bài viết này đều được ngầm giả sử là ma trận thực.
2. Một chút về Đại số tuyến tính
2.1. Trị riêng và vector riêng
Cho một ma trận vuông \(\mathbf{A} \in \mathbb{R}^{n\times n}\), nếu số vô hướng \(\lambda\) và vector \(\mathbf{x} \neq \mathbf{0} \in \mathbb{R}^n\) thoả mãn:
\[ \mathbf{Ax} = \lambda \mathbf{x} \] thì \(\lambda\) được gọi là một trị riêng của \(\mathbf{A}\) và \(\mathbf{x}\) được gọi là vector riêng tương ứng với trị riêng đó.
Một vài tính chất:
-
Nếu \(\mathbf{x}\) là một vector riêng của \(\mathbf{A}\) ứng với \(\lambda\) thì \(k\mathbf{x}, k \neq 0\) cũng là vector riêng ứng với trị riêng đó.
-
Mọi ma trận vuông bậc \(n\) đều có \(n\) trị riêng (kể cả lặp) và có thể là các số phức.
-
Với ma trận đối xứng, tất cả các trị riêng đều là các số thực.
-
Với ma trận xác định dương, tất cả các trị riêng của nó đều là các số thực dương. Với ma trận nửa xác định dương, tất cả các trị riêng của nó đều là các số thực không âm.
Tính chất cuối cùng có thể được suy ra từ định nghĩa của ma trận (nửa) xác định dương. Thật vậy, gọi \(\mathbf{u} \neq \mathbf{0}\) là vector riêng ứng với một trị riêng \(\lambda\) của ma trận \(\mathbf{A}\) xác định dương, ta có: \[ \mathbf{Au} = \lambda \mathbf{u} \Rightarrow \mathbf{u}^T\mathbf{Au} = \lambda \mathbf{u}^T\mathbf{u} = \lambda ||\mathbf{u}||_2^2 \]
Vì \(\mathbf{A}\) là nửa xác định dương nên với mọi \(\mathbf{u} \neq \mathbf{0}\): \(\mathbf{u}^T\mathbf{Au} \geq 0\); \(\mathbf{u} \neq 0\) nên \(||\mathbf{u}||_2^2 > 0\). Từ đó suy ra \(\lambda\) là một số không âm.
2.2. Hệ trực giao và trực chuẩn
Một hệ cơ sở \({\mathbf{u}_1, \mathbf{u}_2,\dots, \mathbf{u}_m \in \mathbb{R}^m}\) được gọi là trực giao (orthogonal) nếu mỗi vector là khác 0 và tích của hai vector khác nhau bất kỳ bằng 0:
\[ \mathbf{u}_i \neq \mathbf{0}; ~~ \mathbf{u}_i^T \mathbf{u}_j = 0 ~ \forall ~1 \leq i \neq j \leq m \]
Một hệ cơ sở \({\mathbf{u}_1, \mathbf{u}_2,\dots, \mathbf{u}_m \in \mathbb{R}^m}\) được gọi là trực chuẩn (orthonormal) nếu nó là một hệ trực giao và độ dài Euclidean (norm 2) của mỗi vector bằng 1:
\[ \begin{eqnarray} \mathbf{u}_i^T \mathbf{u}_j = \left\{ \begin{matrix} 1 & \text{if} &i = j \newline 0 & \text{otherwise} \end{matrix} \right. ~~~~ (4) \end{eqnarray} \]
Gọi \(\mathbf{U} = [\mathbf{u}_1, \mathbf{u}_2,\dots, \mathbf{u}_m]\) với \({\mathbf{u}_1, \mathbf{u}_2,\dots, \mathbf{u}_m \in \mathbb{R}^m}\) là trực chuẩn, thế thì từ \((4)\) có thể suy ra ngay:
\[ \mathbf{UU}^T = \mathbf{U}^T\mathbf{U} = \mathbf{I} \]
trong đó \(\mathbf{I}\) là ma trận đơn vị bậc \(m\). Ta gọi \(\mathbf{U}\) là ma trận trực giao (orthogonal matrix). Ma trận loại này không được gọi là ma trận trực chuẩn, không có định nghĩa cho ma trận trực chuẩn.
Một vài tính chất:
-
\(\mathbf{U}^{-1} = \mathbf{U}^T\): nghịch đảo của một ma trận trực giao chính là chuyển vị của nó.
-
Nếu \(\mathbf{U}\) là ma trận trực giao thì chuyển vị của nó \(\mathbf{U}^T\) cũng là một ma trận trực giao.
-
Định thức (determinant) của ma trận trực giao bằng \(1\) hoặc \(-1\). Điều này có thể suy ra từ việc \(\det(\mathbf{U}) = \det(\mathbf{U}^T)\) và \(\det(\mathbf{U}) \det(\mathbf{U}^T) = \det(\mathbf{I}) = 1\).
-
Ma trận trực giao thể hiện cho phép xoay (rotate) một vector. Giả sử có hai vector \(\mathbf{x,y} \in \mathbb{R}^m\) và ma trận trực giao \(\mathbf{U} \in \mathbb{R}^{m \times m}\). Dùng ma trận này để xoay hai vector trên ta được \(\mathbf{Ux}, \mathbf{Uy}\). Tích vô hướng của hai vector mới là: \[ (\mathbf{Ux})^T (\mathbf{Uy}) = \mathbf{x}^T \mathbf{U}^T \mathbf{Uy} = \mathbf{x}^T\mathbf{y} \] như vậy phép xoay không làm thay đổi tích vô hướng giữa hai vector.
-
Giả sử \(\hat{\mathbf{U}} \in \mathbb{R}^{m \times r}, r < m\) là môt ma trận con của ma trận trực giao \(\mathbf{U}\) được tạo bởi \(r\) cột của \(\mathbf{U}\), ta sẽ có \(\hat{\mathbf{U}}^T\hat{\mathbf{U}} = \mathbf{I}_{r}\). Việc này có thể được suy ra từ \((4)\).
3. Singular Value Decomposition
Vì trong mục này cần nắm vững chiều của mỗi ma trận nên tôi sẽ thay đổi ký hiệu một chút để chúng ta dễ hình dung. Ta sẽ ký hiệu một ma trận cùng với số chiều của nó, ví dụ \(\mathbf{A}_{m \times n}\) nghĩa là ma trận \(\mathbf{A} \in \mathbb{R}^{m \times n}\).
3.1. Phát biểu SVD
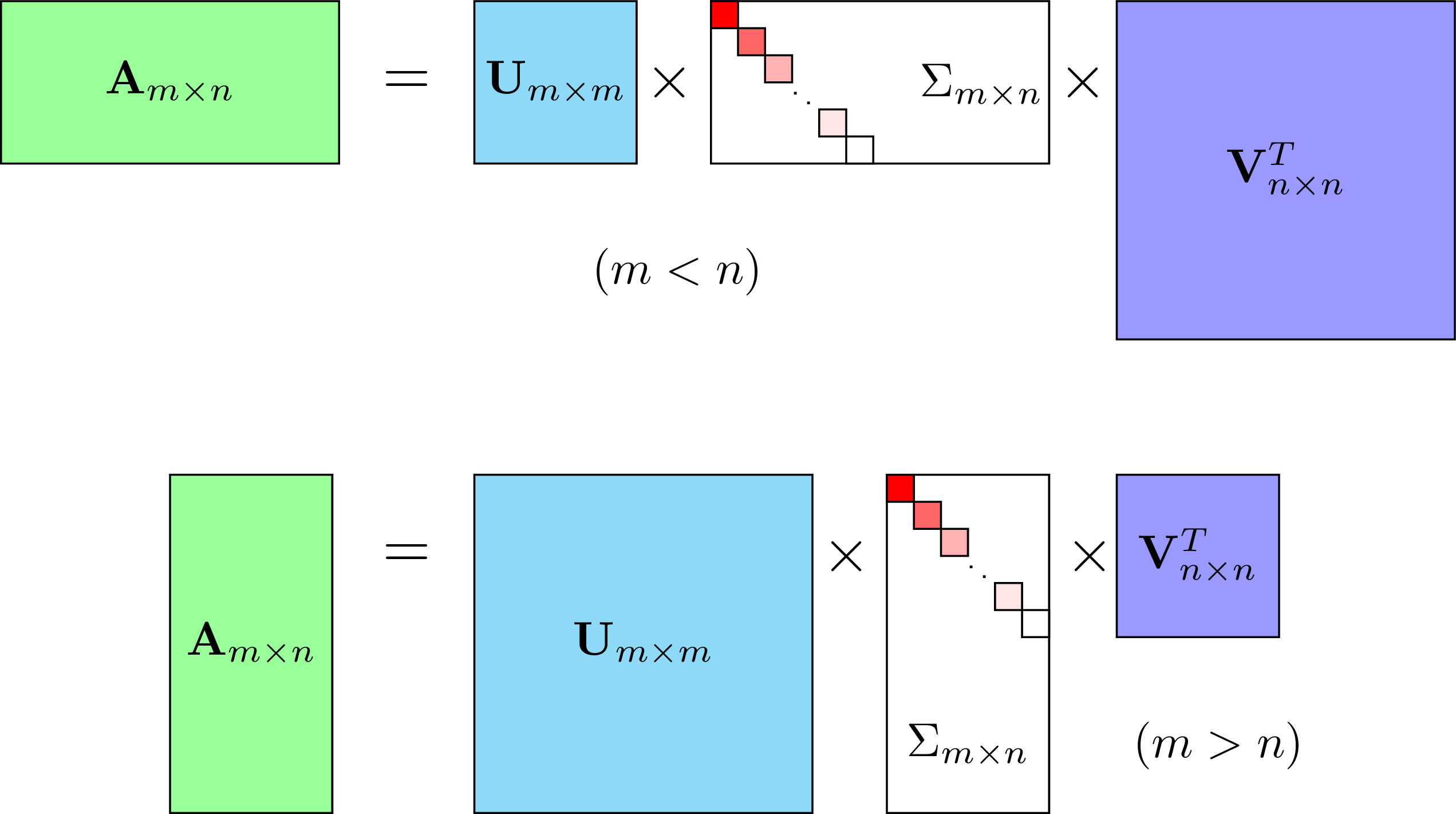
Một ma trận \(\mathbf{A}_{m \times n}\) bất kỳ đều có thể phân tích thành dạng:
\[ \mathbf{A}_{m \times n} = \mathbf{U}_{m \times m}\mathbf{\Sigma}_{m \times n} (\mathbf{V}_{n \times n})^T ~~~~ (5) \]
Trong đó, \(\mathbf{U}, \mathbf{V}\) là các ma trận trực giao, \(\mathbf{\Sigma}\) là ma trận đường chéo không vuông với các phần tử trên đường chéo \(\sigma_1 \geq \sigma_2 \geq \dots \geq\sigma_r \geq 0 = 0 = \dots = 0\) và \(r\) là rank của ma trận \(\mathbf{A}\). Lưu ý rằng mặc dù \(\Sigma\) không phải ma trận vuông, ta vẫn có thể coi nó là ma trận chéo nếu các thành phần khác không của nó chỉ nằm ở vị trí đường chéo, tức tại các vị trí có chỉ số hàng và chỉ số cột là như nhau.
Số lượng các phần tử khác 0 trong \(\Sigma\) chính là rank của ma trận \(\mathbf{A}\).
Nếu bạn muốn xem chứng minh về sự tồn tại của SVD, bạn có thể xem tại đây.
Chú ý rằng cách biểu diễn \((5)\) không là duy nhất vì ta chỉ cần đổi dấu của cả \(\mathbf{U}\) và \(\mathbf{V}\) thì \((5)\) vẫn thoả mãn. Tuy vậy, người ta vẫn thường dùng ‘the SVD’ thay vì ‘a SVD’.
Hình 1 mô tả SVD của ma trận \(\mathbf{A}_{m \times n}\) trong hai trường hợp: \(m < n\) và \(m > n\). Trường hợp \(m =n\) có thể xếp vào một trong hai trường hợp trên.
3.2. Nguồn gốc tên gọi Singular Value Decomposition
Tạm bỏ qua chiều của mỗi ma trận, từ \((5)\) ta có: \[ \begin{eqnarray} \mathbf{AA}^T &=& \mathbf{U}\mathbf{\Sigma} \mathbf{V}^T (\mathbf{U}\mathbf{\Sigma} \mathbf{V}^T)^T \newline &=& \mathbf{U}\mathbf{\Sigma} \mathbf{V}^T \mathbf{V}\mathbf{\Sigma}^T\mathbf{U}^T \newline &=& \mathbf{U}\mathbf{\Sigma}\mathbf{\Sigma}^T\mathbf{U}^T = \mathbf{U}\mathbf{\Sigma}\mathbf{\Sigma}^T\mathbf{U}^{-1} ~~~~~ (6) \end{eqnarray} \]
Dấu bằng cuối cùng xảy ra vì \(\mathbf{V}^T\mathbf{V} = \mathbf{I}\) do \(\mathbf{V}\) là một ma trận trực giao.
Quan sát thấy rằng \(\Sigma\Sigma^T\) là một ma trận đường chéo với các phần tử trên đường chéo là \(\sigma_1^2, \sigma_2^2, \dots\). Vậy \((6)\) chính là Eigen Decomposition của \(\mathbf{A}\mathbf{A}^T\). Thêm nữa, \(\sigma_1^2, \sigma_2^2, \dots\) chính là các trị riêng của \(\mathbf{A}\mathbf{A}^T\).
Ma trận \(\mathbf{A}\mathbf{A}^T\) luôn là ma trận nửa xác định dương nên các trị riêng của nó là không âm. Các \(\sigma_i\) là căn bậc hai của các trị riêng của \(\mathbf{A}\mathbf{A}^T\) còn được gọi là singular values của \(\mathbf{A}\). Cái tên Singular Value Decomposition xuất phát từ đây.
Cũng theo đó, mỗi cột của \(\mathbf{U}\) chính là một vector riêng của \(\mathbf{A}\mathbf{A}^T\). Ta gọi mỗi cột này là left-singular vectors của \(\mathbf{A}\). Tương tự như thế, \(\mathbf{A}^T\mathbf{A} = \mathbf{V}\Sigma^T\Sigma \mathbf{V}^T\) và các cột của \(\mathbf{V}\) còn được gọi là các right-singular vectors của \(\mathbf{A}\).
Trong Python, để tính SVD của một ma trận, chúng ta sử dụng module linalg của numpy như sau:
import numpy as np
from numpy import linalg as LA
m, n = 2, 3
A = np.random.rand(m, n)
U, S, V = LA.svd(A)
# checking if U, V are orthogonal and S is a diagonal matrix with
# nonnegative decreasing elements
print 'Frobenius norm of (UU^T - I) =', \
LA.norm(U.dot(U.T) - np.eye(m))
print '\n S = ', S, '\n'
print 'Frobenius norm of (VV^T - I) =', \
LA.norm(V.dot(V.T) - np.eye(n))
Frobenius norm of (UU^T - I) = 3.14018491737e-16
S = [ 1.82891093 0.2125061 ]
Frobenius norm of (VV^T - I) = 7.77403895378e-16
Lưu ý rằng biến S được trả về chỉ bao gồm các phần tử trên đường chéo của \(\Sigma\). Biến V trả về là \(\mathbf{V}^T\) trong \((5)\).
3.3. Compact SVD
Viết lại biểu thức \((5)\) dưới dạng tổng của các ma trận rank 1: \[ \mathbf{A} = \sigma_1 \mathbf{u}_1 \mathbf{v}^T_1 + \sigma_2\mathbf{u}_2\mathbf{v}_2^2 + \dots + \sigma_r\mathbf{u}_r\mathbf{v}_r^T \]
với chú ý rằng mỗi \(\mathbf{u}_1 \mathbf{v}^T_i, 1 \leq i \leq r\) là một ma trận có rank bằng 1.
Rõ ràng trong cách biểu diễn này, ma trận \(\mathbf{A}\) chỉ phụ thuộc vào \(r\) cột đầu tiên của \(\mathbf{U, V}\) và \(r\) giá trị khác 0 trên đường chéo của ma trận \(\Sigma\). Vì vậy ta có một cách phân tích gọn hơn và gọi là compact SVD:
\[ \mathbf{A} = {\mathbf{U}}_r{\Sigma}_r({\mathbf{V}}_r)^T \]
Với \(\mathbf{U}_r, \mathbf{V}_r \) lần lượt là ma trận được tạo bởi \(r\) cột đầu tiên của \(\mathbf{U}\) và \(\mathbf{V}\). \(\Sigma_r\) là ma trận con được tạo bởi \(r\) hàng đầu tiên và \(r\) cột đầu tiên của \(\Sigma\). Nếu ma trận \(\mathbf{A}\) có rank nhỏ hơn rất nhiều so với số hàng và số cột \(r \ll m, n\), ta sẽ được lợi nhiều về việc lưu trữ.
Dưới đây là ví dụ minh hoạ với \(m = 4, n = 6, r = 2\).
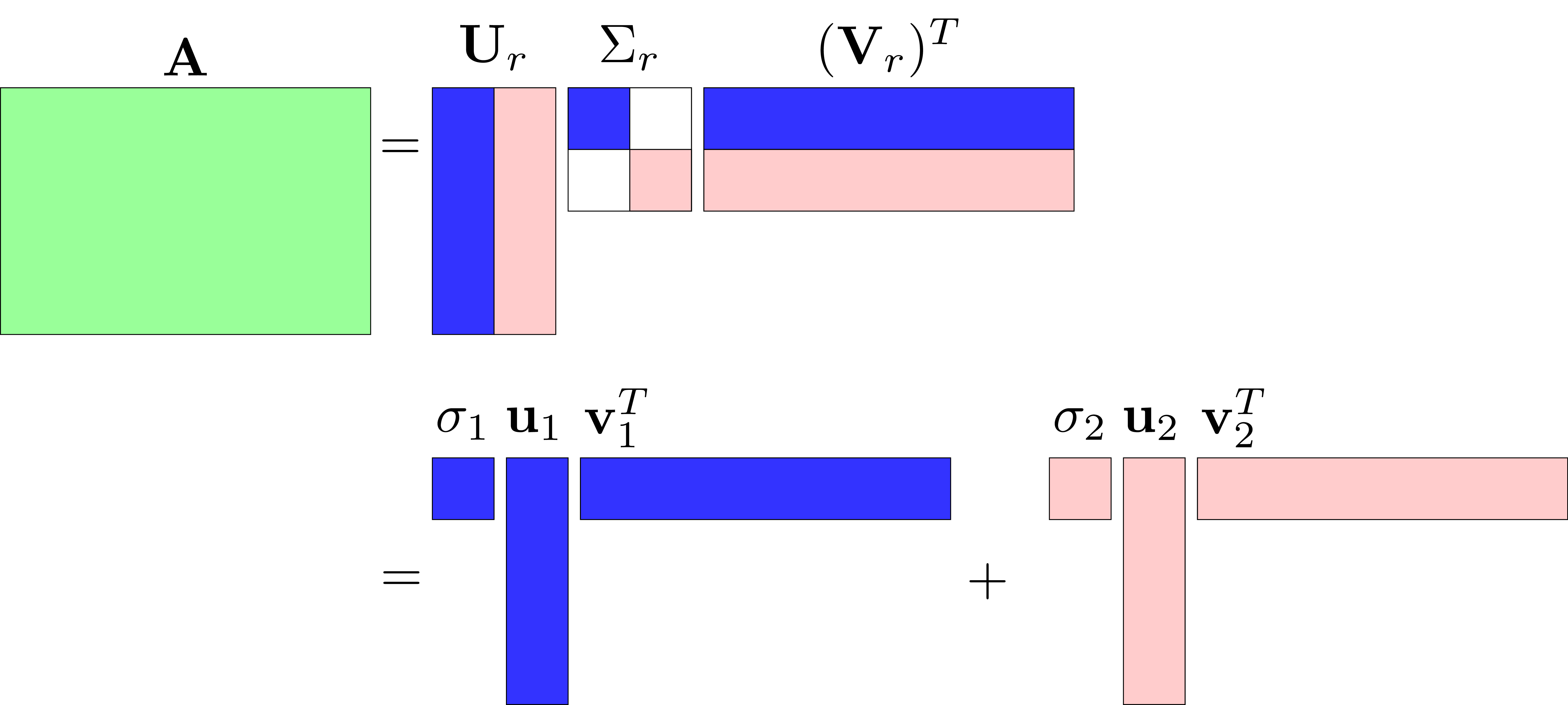
3.4. Truncated SVD
Chú ý rằng trong ma trận \(\Sigma\), các giá trị trên đường chéo là không âm và giảm dần \(\sigma_1 \geq \sigma_2 \geq \dots, \geq \sigma_r \geq 0 = 0 = \dots = 0\). Thông thường, chỉ một lượng nhỏ các \(\sigma_i\) mang giá trị lớn, các giá trị còn lại thường nhỏ và gần 0. Khi đó ta có thể xấp xỉ ma trận \(\mathbf{A}\) bằng tổng của \(k < r\) ma trận có rank 1:
\[ \mathbf{A} \approx \mathbf{A}_k = \mathbf{U}_k \Sigma_k (\mathbf{V}_k)^T = \sigma_1 \mathbf{u}_1 \mathbf{v}^T_1 + \sigma_2\mathbf{u}_2\mathbf{v}_2^2 + \dots + \sigma_k\mathbf{u}_k\mathbf{v}k^T ~~~~ (7) \] Dưới đây là một định lý thú vị. Định lý này nói rằng sai số do cách xấp xỉ trên chính là căn bậc hai của tổng bình phương của các singular values mà ta đã bỏ qua ở phần cuối của \(\Sigma\). Ở đây sai số được định nghĩa là Frobineous norm của hiệu hai ma trận:
Định lý: \[ ||\mathbf{A} - \mathbf{A}_k||_F^2 = \sum_{i = k + 1}^r \sigma_i^2 ~~~ (8) \]
Chứng minh:
Sử dụng tính chất \(||\mathbf{X}||_F^2 = \text{trace}(\mathbf{X}\mathbf{X}^T)\) và \(\text{trace}(\mathbf{XY}) = \text{trace}(\mathbf{YX})\) với mọi ma trận \(\mathbf{X, Y}\) ta có:
\[ \begin{eqnarray} ||\mathbf{A} - \mathbf{A}_k||_F^2 & = & ||\sum_{i = k + 1}^r \sigma_i \mathbf{u}_i\mathbf{v}_i^T ||_F^2 & (9)\newline & = & \text{trace}\left\{ \left(\sum_{i = k + 1}^r \sigma_i \mathbf{u}_i\mathbf{v}_i^T\right) \left(\sum_{j = k + 1}^r \sigma_j \mathbf{u}_j\mathbf{v}_j^T\right)^T \right\} & (10) \newline &=& \text{trace}\left\{ \sum_{i = k + 1}^r \sum_{j = k + 1}^r \sigma_i\sigma_j \mathbf{u}_i\mathbf{v}_i^T \mathbf{v}_j \mathbf{u}_j^T \right\} & (11) \newline &=& \text{trace}\left\{ \sum_{i = k + 1}^r \sigma_i^2\mathbf{u}_i\mathbf{u}_i^T \right\} & (12) \newline &=& \text{trace}\left\{ \sum_{i = k + 1}^r \sigma_i^2\mathbf{u}_i^T\mathbf{u}_i \right\} & (13) \newline &=& \text{trace}\left\{ \sum_{i = k + 1}^r \sigma_i^2 \right\} & (14) \newline & = & \sum_{i = k + 1}^r \sigma_i^2 & (15) \end{eqnarray} \]
Dấu bằng ở \((12)\) là vì \(\mathbf{V}\) là ma trận trực giao (xem \((4)\)).
Dấu bằng ở \((13)\) là vì hàm \(\text{trace}\) có tính chất giao hoán.
Dấu bằng ở \((15)\) là vì biểu thức trong dấu ngoặc của \((14)\) là một số vô hướng.
Thay \(k = 0\) ta sẽ có: \[||\mathbf{A}||_F^2 = \sum_{i = 1}^r \sigma_i^2~~~~ (16) \]
Từ đó:
\[ \frac{||\mathbf{A} - \mathbf{A}_k||_F^2}{||\mathbf{A}||_F^2} = {\frac{\sum_{i = k + 1}^r \sigma_i^2}{\sum_{j = 1}^r \sigma_j^2}} ~~~~ (17) \]
Như vậy, sai số do xấp xỉ càng nhỏ nếu phần singular values bị truncated có giá trị càng nhỏ so với phần singular values được giữ lại. Đây là một định lý quan trọng giúp xác định việc xấp xỉ ma trận dựa trên lượng thông tin muốn giữ lại.
Ví dụ, nếu ta muốn giữ lại ít nhất 90% lương thông tin trong \(\mathbf{A}\), trước hết ta tính \(\sum_{j = 1}^r \sigma_j^2\), sau đó chọn \(k\) là số nhỏ nhất sao cho:
\[ \frac{\sum_{i = 1}^k \sigma_i^2}{\sum_{j = 1}^r \sigma_j^2} \geq 0.9 \]
Khi \(k\) nhỏ, ma trận \(\mathbf{A}_k\) có rank là \(k\), là một ma trận có rank nhỏ. Vì vậy, Truncated SVD còn được coi là một phương pháp Low-rank approximation.
3.5. Best Rank \(k\) Approximation
Người ta chứng minh được rằng (Singular Value Decomposition - Princeton) \(\mathbf{A}_k\) chính là nghiệm của bài toán tối ưu:
\[ \begin{eqnarray} \min_{\mathbf{B}} &&||\mathbf{A} - \mathbf{B}||_F \newline \text{s.t.} && \text{rank}(\mathbf{B}) = k ~~~~~~~~~~~~~~ (17) \end{eqnarray} \]
và như đã chứng minh ở trên \(||\mathbf{A} - \mathbf{A}_k||_F^2 = \sum_{i = k + 1}^r \sigma_i^2\).
Nếu sử dụng norm 2 của ma trận thay vì Frobenius norm để đo sai số, \(\mathbf{A}_k\) cũng là nghiệm của bài toán tối ưu:
\[ \begin{eqnarray} \min_{\mathbf{B}} &&||\mathbf{A} - \mathbf{B}||_2 \newline \text{s.t.} && \text{rank}(\mathbf{B}) = k ~~~~~~~~~~~~~~ (18) \end{eqnarray} \]
và sai số: \(||\mathbf{A} - \mathbf{A}_k||_2^2 = \sigma_{k+1}^2\). Định nghĩa của norm 2 của một ma trận là:
\[ ||\mathbf{A}||_2 = \max_{||\mathbf{x}||_2 = 1} ||\mathbf{Ax}||_2 \]
Đây là lý do căn bậc hai của tổng bình phương của các phần tử của một ma trận không được gọi là norm 2 như đối với vector.
Nếu bạn muốn biết thêm: \[ ||\mathbf{A}||_2 = \sigma_1 \] tức norm 2 của một ma trận chính là singular value lớn nhất của ma trận đó.
Frobenius norm và norm 2 là hai norms được sử dụng nhiều nhất trong ma trận. Như vậy, xét trên cả hai norm này, Truncated SVD đều cho xấp xỉ tốt nhất. Vì vậy Truncated SVD còn được gọi là Best low-rank Approximation.
4. Một vài ứng dụng của SVD
4.1. Image Compression
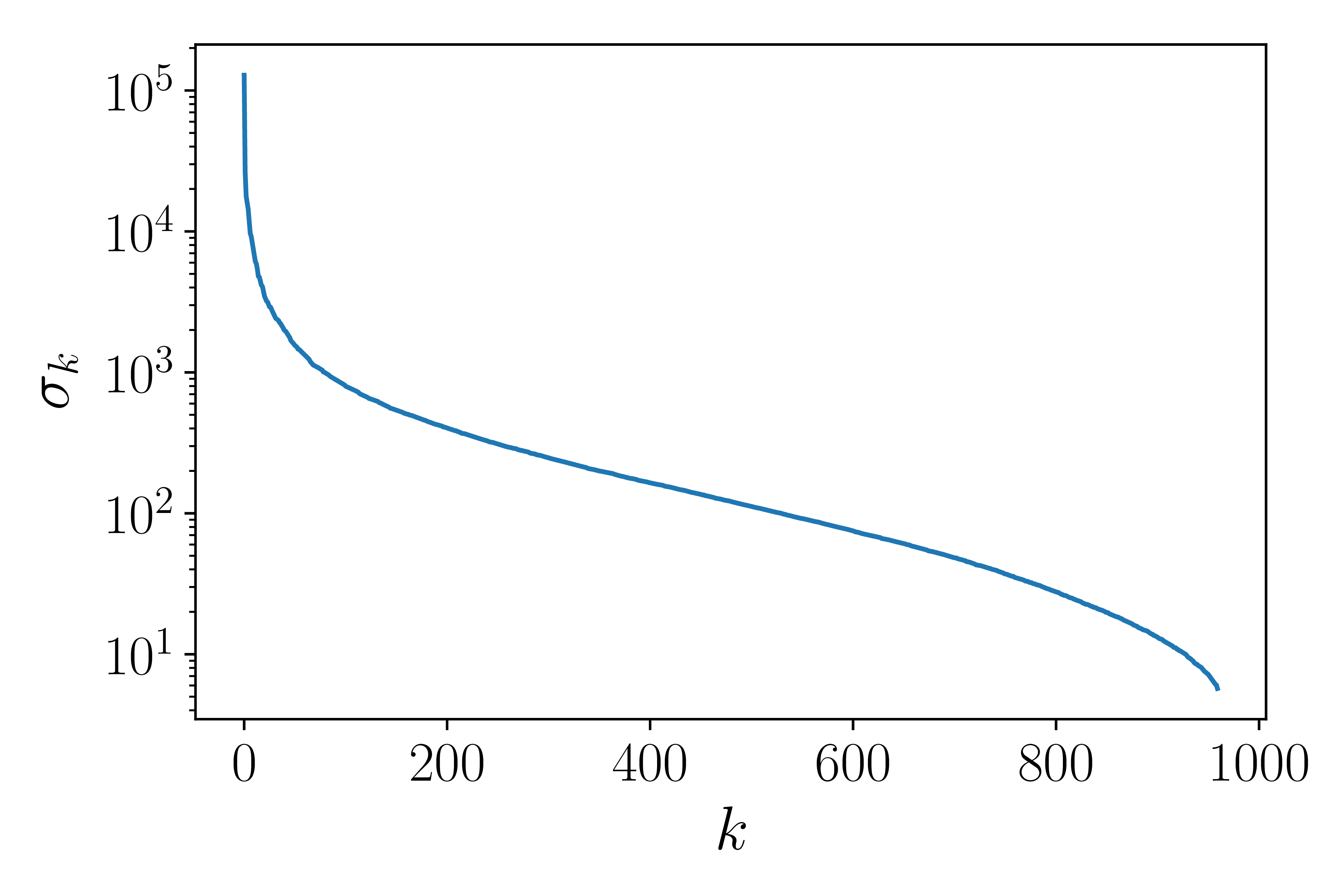
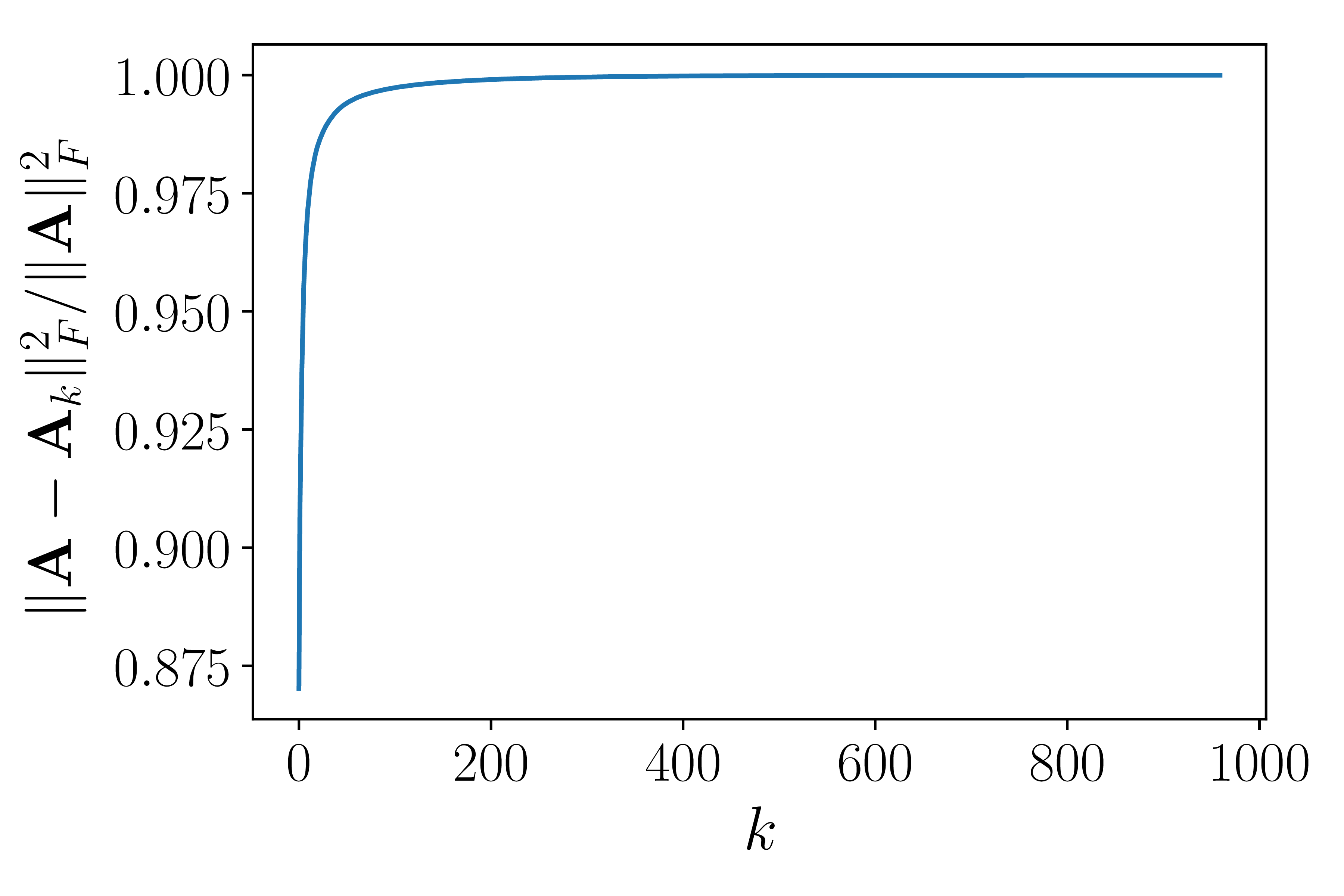
Xét ví dụ trong Hình 3 dưới đây:

a) |
b) |
c) |
Hình 3: Ví dụ về SVD cho ảnh. a) Bức ảnh gốc là 1 ảnh xám, là một ma trận cỡ \(960 \times 1440\). b) Giá trị của các singular values của ma trận ảnh theo logscale. Có thể thấy rằng các singular value giảm nhanh ở khoảng \(k = 200\). c) Biểu diễn lượng thông tin được giữ lại khi chọn các \(k\) khác nhau. Có thể nhận thấy từ khoảng \(k = 200\), lượng thông tin giữ lại là gần bằng 1. Vậy ta có thể xấp xỉ ma trận ảnh này bằng 1 ma trận có rank nhỏ hơn. |
Hình 3 mô tả chất lượng ảnh khi chọn các giá trị \(k\) khác nhau. Khi \(k\) gần 100, lượng thông tin mất đi rơi vào khoảng nhỏ hơn 2%, ảnh thu được có chất lượng gần như ảnh gốc.

Để lưu ảnh với Truncated SVD, ta sẽ lưu các ma trận \(\mathbf{U}_k \in \mathbb{R}^{m \times k}, \Sigma_k \in \mathbb{R}^{k \times k}, \mathbf{V}_k \in \mathbb{R}^{n \times k}\). Tổng số phần tử phải lưu là \(k(m + n + 1)\) với chú ý rằng ta chỉ cần lưu các giá trị trên đường chéo của \(\Sigma_k\). Giả sử mỗi phần tử được lưu bởi một số thực 4 byte, thế thì số byte cần lưu trữ là \(4k(m + n + 1)\). Nếu so giá trị này với ảnh gốc có kích thước \(mn\), mỗi giá trị là 1 số nguyên 1 byte, tỉ lệ nén là:
\[ \frac{4k(m + n + 1)}{mn} \] Khi \(k \ll m, n\), ta được một tỉ lệ nhỏ hơn 1. Trong ví dụ của chúng ta \(m = 960, n = 1440, k = 100\), ta có tỉ lệ nén xấp xỉ 0.69, tức đã tiết kiệm được khoảng 30% bộ nhớ.
4.2. Truncated SVD cho Recommendation System
Như đã nhắc ở Mục 1, SVD là một phương pháp Matrix Factorization, vì vậy, nó cũng hoàn toàn có thể được áp dụng vào bài toán Recommendation Systems như trong Bài 25.
Ý tưởng hoàn toàn tương tự, ta sẽ xấp xỉ Utility Matrix đã được chuẩn hoá (theo user-based hoặc item-based). Giá trị của ma trận xấp xỉ có rank nhỏ hơn chính là giá trị được dự đoán.
Kết quả (RMSE) với cơ sở dữ liệu tương tự như Bài 25 là:
-
MovieLens 100k, user-based: 1.018 (tốt hơn so với 1.06 của Matrix Factorization).
-
MovieLens 100k, item-based: 1.014 (tốt hơn so với 1.05)
-
MovieLens 1M, item-based: 0.95 (tốt hơn so với 0.98)
Như vậy, Truncated SVD cho kết quả tốt hơn so với Matrix Factorization giải bằng Gradient Descent một chút.
Một cách giải thích thú vị về mối liên quan giữa SVD và Utility Matrix với user-
5. Thảo luận
-
Ngoài hai ứng dụng nêu trên, SVD còn có mối liên quan chặt chẽ đến giả nghịch đảo Moore Penrose. (Xem thêm The Moore-Penrose Pseudoinverse (Math 33A - UCLA)). Giả nghịch đảo đóng một vài trò quan trọng trong giải hệ phương trình tuyến tính. Một ví dụ của nó đã được đề cập trong Bài 3: Linear Regression.
-
Còn nhiều tính chất và ứng dụng thú vị khác của SVD, chúng ta sẽ dần tìm hiểu. Trước tiên là trong Dimensionality Reduction với Principle Component Analysis. Chúng ta sẽ cùng trao đổi tới vấn đề này trong bài tiếp theo.
-
Khi ma trận \(\mathbf{A}\) lớn, việc tính toán SVD của nó tốn nhiều thời gian. Cách tính Truncated SVD với \(k\) nhỏ bằng cách tính SVD như tôi sử dụng trong bài trở nên không khả thi. Thay vào đó, có một phương pháp lặp giúp tính các trị riêng và vector riêng của một ma trận lớn một cách hiệu quả, và ta chỉ cần tìm \(k\) trị riêng lớn nhất của \(\mathbf{AA}^T\) và các vector riêng tương ứng, việc này sẽ tiết kiệm được khá nhiều thời gian. Bạn đọc có thể tìm đọc thêm Power method for approximating eigenvalues. Phương pháp này cũng là phần chính của thuật toán nổi tiếng Google PageRank, tôi sẽ có một bài về vấn đề này khi thấy phù hợp.
6. Tài liệu tham khảo
[1] Singular Value Decomposition - Stanford University