
Trong trang này:
- 1. Giới thiệu
- 2. Accuracy
- 3. Confusion matrix
- 4. True/False Positive/Negative
- 5. Precision và Recall
- 6. Tóm tắt
- 7. Tài liệu tham khảo
Bạn có thể download toàn bộ source code dưới dạng Jupyter Notebook tại đây.
1. Giới thiệu
Khi xây dựng một mô hình Machine Learning, chúng ta cần một phép đánh giá để xem mô hình sử dụng có hiệu quả không và để so sánh khả năng của các mô hình. Trong bài viết này, tôi sẽ giới thiệu các phương pháp đánh giá các mô hình classification.
Hiệu năng của một mô hình thường được đánh giá dựa trên tập dữ liệu kiểm thử (test data). Cụ thể, giả sử đầu ra của mô hình khi đầu vào là tập kiểm thử được mô tả bởi vector y_pred - là vector dự đoán đầu ra với mỗi phần tử là class được dự đoán của một điểm dữ liệu trong tập kiểm thử. Ta cần so sánh giữa vector dự đoán y_pred này với vector class thật của dữ liệu, được mô tả bởi vector y_true.
Ví dụ với bài toán có 3 lớp dữ liệu được gán nhãn là 0, 1, 2. Trong bài toán thực tế, các class có thể có nhãn bất kỳ, không nhất thiết là số, và không nhất thiết bắt đầu từ 0. Chúng ta hãy tạm giả sử các class được đánh số từ 0 đến C-1 trong trường hợp có C lớp dữ liệu. Có 10 điểm dữ liệu trong tập kiểm thử với các nhãn thực sự được mô tả bởi y_true = [0, 0, 0, 0, 1, 1, 1, 2, 2, 2]. Giả sử bộ phân lớp chúng ta đang cần đánh giá dự đoán nhãn cho các điểm này là y_pred = [0, 1, 0, 2, 1, 1, 0, 2, 1, 2].
Có rất nhiều cách đánh giá một mô hình phân lớp. Tuỳ vào những bài toán khác nhau mà chúng ta sử dụng các phương pháp khác nhau. Các phương pháp thường được sử dụng là: accuracy score, confusion matrix, ROC curve, Area Under the Curve, Precision and Recall, F1 score, Top R error, etc.
Trong Phần 1 này, tôi sẽ trình bày về accuracy score, confusion matrix, ROC curve, và Area Under the Curve. Các phương pháp còn lại sẽ được trình bày trong Phần 2.
2. Accuracy
Cách đơn giản và hay được sử dụng nhất là accuracy (độ chính xác). Cách đánh giá này đơn giản tính tỉ lệ giữa số điểm được dự đoán đúng và tổng số điểm trong tập dữ liệu kiểm thử.
Trong ví dụ này, ta có thể đếm được có 6 điểm dữ liệu được dự đoán đúng trên tổng số 10 điểm. Vậy ta kết luận độ chính xác của mô hình là 0.6 (hay 60%). Để ý rằng đây là bài toán với chỉ 3 class, nên độ chính xác nhỏ nhất đã là khoảng 1/3, khi tất cả các điểm được dự đoán là thuộc vào một class nào đó.
from __future__ import print_function
import numpy as np
def acc(y_true, y_pred):
correct = np.sum(y_true == y_pred)
return float(correct)/y_true.shape[0]
y_true = np.array([0, 0, 0, 0, 1, 1, 1, 2, 2, 2])
y_pred = np.array([0, 1, 0, 2, 1, 1, 0, 2, 1, 2])
print('accuracy = ', acc(y_true, y_pred))
accuracy = 0.6
Và đây là cách tính bằng thư viên:
from sklearn.metrics import accuracy_score
print('accuracy = ',accuracy_score(y_true, y_pred))
accuracy = 0.6
3. Confusion matrix
Cách tính sử dụng accuracy như ở trên chỉ cho chúng ta biết được bao nhiêu phần trăm lượng dữ liệu được phân loại đúng mà không chỉ ra được cụ thể mỗi loại được phân loại như thế nào, lớp nào được phân loại đúng nhiều nhất, và dữ liệu thuộc lớp nào thường bị phân loại nhầm vào lớp khác. Để có thể đánh giá được các giá trị này, chúng ta sử dụng một ma trận được gọi là confusion matrix.
Về cơ bản, confusion matrix thể hiện có bao nhiêu điểm dữ liệu thực sự thuộc vào một class, và được dự đoán là rơi vào một class. Để hiểu rõ hơn, hãy xem bảng dưới đây:
Total: 10 | Predicted | Predicted | Predicted |
| as: 0 | as: 1 | as: 2 |
-----------|-----------|-----------|-----------|---
True: 0 | 2 | 1 | 1 | 4
-----------|-----------|-----------|-----------|---
True: 1 | 1 | 2 | 0 | 3
-----------|-----------|-----------|-----------|---
True: 2 | 0 | 1 | 2 | 3
-----------|-----------|-----------|-----------|---
Có tổng cộng 10 điểm dữ liệu. Chúng ta xét ma trận tạo bởi các giá trị tại vùng 3x3 trung tâm của bảng.
Ma trận thu được được gọi là confusion matrix. Nó là một ma trận vuông với kích thước mỗi chiều bằng số lượng lớp dữ liệu. Giá trị tại hàng thứ i, cột thứ j là số lượng điểm lẽ ra thuộc vào class i nhưng lại được dự đoán là thuộc vào class j. Như vậy, nhìn vào hàng thứ nhất (0), ta có thể thấy được rằng trong số bốn điểm thực sự thuộc lớp 0, chỉ có hai điểm được phân loại đúng, hai điểm còn lại bị phân loại nhầm vào lớp 1 và lớp 2.
Chú ý: Có một số tài liệu định nghĩa ngược lại, tức giá trị tại cột thứ i, hàng thứ j là số lượng điểm lẽ ra thuộc vào class i nhưng lại được dự đoán là thuộc vào class j. Khi đó ta sẽ được confusion matrix là ma trận chuyển vị của confusion matrix như cách tôi đang làm. Tôi chọn cách này vì đây chính là cách thư viện sklearn sử dụng.
Chúng ta có thể suy ra ngay rằng tổng các phần tử trong toàn ma trận này chính là số điểm trong tập kiểm thử. Các phần tử trên đường chéo của ma trận là số điểm được phân loại đúng của mỗi lớp dữ liệu. Từ đây có thể suy ra accuracy chính bằng tổng các phần tử trên đường chéo chia cho tổng các phần tử của toàn ma trận. Đoạn code dưới đây mô tả cách tính confusion matrix:
def my_confusion_matrix(y_true, y_pred):
N = np.unique(y_true).shape[0] # number of classes
cm = np.zeros((N, N))
for n in range(y_true.shape[0]):
cm[y_true[n], y_pred[n]] += 1
return cm
cnf_matrix = my_confusion_matrix(y_true, y_pred)
print('Confusion matrix:')
print(cnf_matrix)
print('\nAccuracy:', np.diagonal(cnf_matrix).sum()/cnf_matrix.sum())
Confusion matrix:
[[ 2. 1. 1.]
[ 1. 2. 0.]
[ 0. 1. 2.]]
Accuracy: 0.6
Cách biểu diễn trên đây của confusion matrix còn được gọi là unnormalized confusion matrix, tức ma confusion matrix chưa chuẩn hoá. Để có cái nhìn rõ hơn, ta có thể dùng normalized confuion matrix, tức confusion matrix được chuẩn hoá. Để có normalized confusion matrix, ta lấy mỗi hàng của unnormalized confusion matrix sẽ được chia cho tổng các phần tử trên hàng đó. Như vậy, ta có nhận xét rằng tổng các phần tử trên một hàng của normalized confusion matrix luôn bằng 1. Điều này thường không đúng trên mỗi cột. Dưới đây là cách tính normalized confusion matrix:
normalized_confusion_matrix = cnf_matrix/cnf_matrix.sum(axis = 1, keepdims = True)
print('\nConfusion matrix (with normalizatrion:)')
print(normalized_confusion_matrix)
Confusion matrix (with normalizatrion:)
[[ 0.5 0.25 0.25 ]
[ 0.33333333 0.66666667 0. ]
[ 0. 0.33333333 0.66666667]]
Và cách tính sử dụng thư viện:
from sklearn.metrics import confusion_matrix
cnf_matrix = confusion_matrix(y_true, y_pred)
print('Confusion matrix:')
print(cnf_matrix)
Confusion matrix:
[[2 1 1]
[1 2 0]
[0 1 2]]
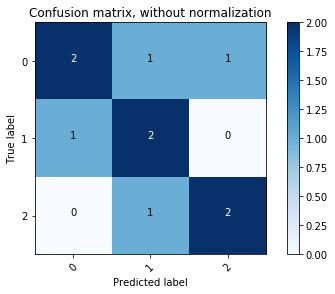
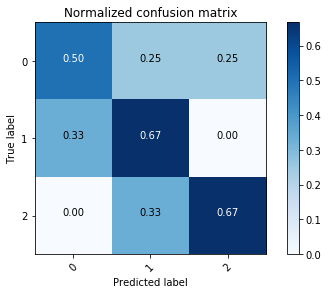
Confusion matrix thường được minh hoạ bằng màu sắc để có cái nhìn rõ ràng hơn. Đoạn code dưới đây giúp hiển thị confusion matrix ở cả hai dạng (Nguồn: Confusion matrix):
import matplotlib.pyplot as plt
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1, keepdims = True)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
# Plot non-normalized confusion matrix
class_names = [0, 1, 2]
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names,
title='Confusion matrix, without normalization')
# Plot normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names, normalize=True,
title='Normalized confusion matrix')
plt.show()
|
|
Với các bài toán với nhiều lớp dữ liệu, cách biểu diễn bằng màu này rất hữu ích. Các ô màu đậm thể hiện các giá trị cao. Một mô hình tốt sẽ cho một confusion matrix có các phần tử trên đường chéo chính có giá trị lớn, các phần tử còn lại có giá trị nhỏ. Nói cách khác, khi biểu diễn bằng màu sắc, đường chéo có màu càng đậm so với phần còn lại sẽ càng tốt. Từ hai hình trên ta thấy rằng confusion matrix đã chuẩn hoá mang nhiều thông tin hơn. Sự khác nhau được thấy ở ô trên cùng bên trái. Lớp dữ liệu 0 được phân loại không thực sự tốt nhưng trong unnormalized confusion matrix, nó vẫn có màu đậm như hai ô còn lại trên đường chéo chính.
4. True/False Positive/Negative
4.1. True/False Positive/Negative
Cách đánh giá này thường được áp dụng cho các bài toán phân lớp có hai lớp dữ liệu. Cụ thể hơn, trong hai lớp dữ liệu này có một lớp nghiêm trọng hơn lớp kia và cần được dự đoán chính xác. Ví dụ, trong bài toán xác định có bệnh ung thư hay không thì việc không bị sót (miss) quan trọng hơn là việc chẩn đoán nhầm âm tính thành dương tính. Trong bài toán xác định có mìn dưới lòng đất hay không thì việc bỏ sót nghiêm trọng hơn việc báo động nhầm rất nhiều. Hay trong bài toán lọc email rác thì việc cho nhầm email quan trọng vào thùng rác nghiêm trọng hơn việc xác định một email rác là email thường.
Trong những bài toán này, người ta thường định nghĩa lớp dữ liệu quan trọng hơn cần được xác định đúng là lớp Positive (P-dương tính), lớp còn lại được gọi là Negative (N-âm tính). Ta định nghĩa True Positive (TP), False Positive (FP), True Negative (TN), False Negative (FN) dựa trên confusion matrix chưa chuẩn hoá như sau:
| Predicted | Predicted |
| as Positive | as Negative |
------------------|---------------------|---------------------|
Actual: Positive | True Positive (TP) | False Negative (FN) |
------------------|---------------------|---------------------|
Actual: Negative | False Positive (FP) | True Negative (TN) |
------------------|---------------------|---------------------|
Người ta thường quan tâm đến TPR, FNR, FPR, TNR (R - Rate) dựa trên normalized confusion matrix như sau:
| Predicted | Predicted |
| as Positive | as Negative |
------------------|--------------------|--------------------|
Actual: Positive | TPR = TP/(TP + FN) | FNR = FN/(TP + FN) |
------------------|--------------------|--------------------|
Actual: Negative | FPR = FP/(FP + TN) | TNR = TN/(FP + TN) |
------------------|--------------------|--------------------|
False Positive Rate còn được gọi là False Alarm Rate (tỉ lệ báo động nhầm), False Negative Rate còn được gọi là Miss Detection Rate (tỉ lệ bỏ sót). Trong bài toán dò mìn, thà báo nhầm còn hơn bỏ sót, tức là ta có thể chấp nhận False Alarm Rate cao để đạt được Miss Detection Rate thấp.
Chú ý::
-
Việc biết một cột của confusion matrix này sẽ suy ra được cột còn lại vì tổng các hàng luôn bằng 1 và chỉ có hai lớp dữ liệu.
-
Với các bài toán có nhiều lớp dữ liệu, ta có thể xây dựng bảng True/False Positive/Negative cho mỗi lớp nếu coi lớp đó là lớp Positive, các lớp còn lại gộp chung thành lớp Negative, giống như cách làm trong one-vs-rest. Bạn có thể xem thêm ví dụ tại đây.
4.2. Receiver Operating Characteristic curve
Trong một số bài toán, việc tăng hay giảm FNR, FPR có thể được thực hiện bằng việc thay đổi một ngưỡng (threshold) nào đó. Lấy ví dụ khi ta sử dụng thuật toán Logistic Regression, đầu ra của mô hình có thể là các lớp cứng 0 hay 1, hoặc cũng có thể là các giá trị thể hiện xác suất để dữ liệu đầu vào thuộc vào lớp 1. Khi sử dụng thư viện sklearn Logistic Regression, ta có thể lấy được các giá trị xác xuất này bằng phương thức predict_proba(). Mặc định, ngưỡng được sử dụng là 0.5, tức là một điểm dữ liệu x sẽ được dự đoán rơi vào lớp 1 nếu giá trị predict_proba(x) lớn hơn 0.5 và ngược lại.
Nếu bây giờ ta coi lớp 1 là lớp Positive, lớp 0 là lớp Negative, câu hỏi đặt ra là làm thế nào để tăng mức độ báo nhầm (FPR) để giảm mức độ bỏ sót (FNR)? Chú ý rằng tăng FNR đồng nghĩa với việc giảm TPR vì tổng của chúng luôn bằng 1.
Một kỹ thuật đơn giản là ta thay giá trị threshold từ 0.5 xuống một số nhỏ hơn. Chẳng hạn nếu chọn threshold = 0.3, thì mọi điểm được dự đoán có xác suất đầu ra lớn hơn 0.3 sẽ được dự đoán là thuộc lớp Positive. Nói cách khác, tỉ lệ các điểm được phân loại là Positive sẽ tăng lên, kéo theo cả False Positive Rate và True Positive Rate cùng tăng lên (cột thứ nhất trong ma trận tăng lên). Từ đây suy ra cả FNR và TNR đều giảm.
Ngược lại, nếu ta muốn bỏ sót còn hơn báo nhầm, tất nhiên là ở mức độ nào đó, như bài toán xác định email rác chẳng hạn, ta cần tăng threshold lên một số lớn hơn 0.5. Khi đó, hầu hết các điểm dữ liệu sẽ được dự đoán thuộc lớp 0, tức Negative, và cả TNF và FNR đều tăng lên, tức TPR và FPR giảm xuống.
Như vậy, ứng với mỗi giá trị của threshold, ta sẽ thu được một cặp (FPR, TPR). Biểu diễn các điểm (FPR, TPR) trên đồ thị khi thay đổi threshold từ 0 tới 1 ta sẽ thu được một đường được gọi là Receiver Operating Characteristic curve hay ROC curve. (Chú ý rằng khoảng giá trị của threshold không nhất thiết từ 0 tới 1 trong các bài toán tổng quát. Khoảng giá trị này cần được đảm bảo có trường hợp TPR/FPR nhận giá trị lớn nhất hay nhỏ nhất mà nó có thể đạt được).
Dưới đây là một ví dụ với hai lớp dữ liệu. Lớp thứ nhất là lớp Negative có 20 điểm dữ liệu, 30 điểm còn lại thuộc lớp Positive. Giả sử mô hình đang xét cho các đầu ra của dữ liệu (xác suất) được lưu ở biến scores.
# generate simulated data
n0, n1 = 20, 30
score0 = np.random.rand(n0)/2
label0 = np.zeros(n0, dtype = int)
score1 = np.random.rand(n1)/2 + .2
label1 = np.ones(n1, dtype = int)
scores = np.concatenate((score0, score1))
y_true = np.concatenate((label0, label1))
print('True labels:')
print(y_true)
print('\nScores:')
print(scores)
True labels:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1]
Scores:
[ 0.16987517 0.27608323 0.10851568 0.13395249 0.24878687 0.29100097
0.21036182 0.48215779 0.01930099 0.30927599 0.26581374 0.15141354
0.26298063 0.10405583 0.30773121 0.39830016 0.04868077 0.17290186
0.28717646 0.3340749 0.4174846 0.27292017 0.68740357 0.62108568
0.20781968 0.43056031 0.67816027 0.47037842 0.23118192 0.68862749
0.24559788 0.58645887 0.69637251 0.5247967 0.24265087 0.60485646
0.54800088 0.69565411 0.20509934 0.39638029 0.30860676 0.6267616
0.42360257 0.5507021 0.50313701 0.67614457 0.60108083 0.25201502
0.27830655 0.58669514]
Nhìn chung, các điểm thuộc lớp 1 có score cao hơn. Thư viện sklearn sẽ giúp chúng ta tính các thresholds cũng như FPR và TPR tương ứng:
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_true, scores, pos_label = 1)
print('Thresholds:')
print(thresholds)
Thresholds:
[ 0.69637251 0.50313701 0.48215779 0.4174846 0.39830016 0.39638029
0.30927599 0.30860676 0.28717646 0.27830655 0.27608323 0.27292017
0.26298063 0.25201502 0.24878687 0.23118192 0.21036182 0.20509934
0.01930099]
print('False Positive Rate:')
print(fpr)
False Positive Rate:
[ 0. 0. 0.05 0.05 0.1 0.1 0.2 0.2 0.35 0.35 0.4 0.4
0.5 0.5 0.55 0.55 0.6 0.6 1. ]
print('True Positive Rate:')
tpr
True Positive Rate:
array([ 0.03333333, 0.53333333, 0.53333333, 0.66666667, 0.66666667,
0.7 , 0.7 , 0.73333333, 0.73333333, 0.76666667,
0.76666667, 0.8 , 0.8 , 0.83333333, 0.83333333,
0.93333333, 0.93333333, 1. , 1. ])
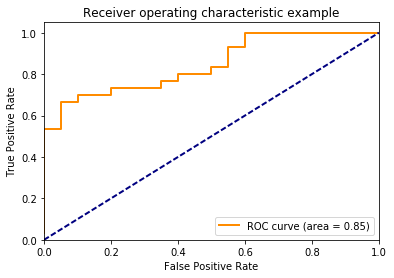
Như vậy, ứng với threshold = 0.69637251, fpr = 0 và tpr = 0.03. Đây không phải là một ngưỡng tốt vì mặc dụ False Positive Rate thấp, True Positive Rate cũng rất thấp. Chúng ta luôn muốn rằng FPR thấp và TPR cao.
ROC cho bài toán này được minh hoạ như dưới đây:
import matplotlib.pyplot as plt
from itertools import cycle
plt.figure()
lw = 2
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % auc(fpr, tpr))
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
|
Hình 2: Ví dụ về Receiver Operating Characteristic curve và Area Under the Curve. |
4.3. Area Under the Curve
Dựa trên ROC curve, ta có thể chỉ ra rằng một mô hình có hiệu quả hay không. Một mô hình hiệu quả khi có FPR thấp và TPR cao, tức tồn tại một điểm trên ROC curve gần với điểm có toạ độ (0, 1) trên đồ thị (góc trên bên trái). Curve càng gần thì mô hình càng hiệu quả.
Có một thông số nữa dùng để đánh giá mà tôi đã sử dụng ở trên được gọi là Area Under the Curve hay AUC. Đại lượng này chính là diện tích nằm dưới ROC curve màu cam. Giá trị này là một số dương nhỏ hơn hoặc bằng 1. Giá trị này càng lớn thì mô hình càng tốt.
Chú ý: Cross validation cũng có thể được thực hiện bằng cách xác định ROC curve và AUC lên [validation set].
5. Precision và Recall
5.1 Định nghĩa
Với bài toán phân loại mà tập dữ liệu của các lớp là chênh lệch nhau rất nhiều, có một phép đó hiệu quả thường được sử dụng là Precision-Recall.
Trước hết xét bài toán phân loại nhị phân. Ta cũng coi một trong hai lớp là positive, lớp còn lại là negative.
Xét Hình 3 dưới đây:
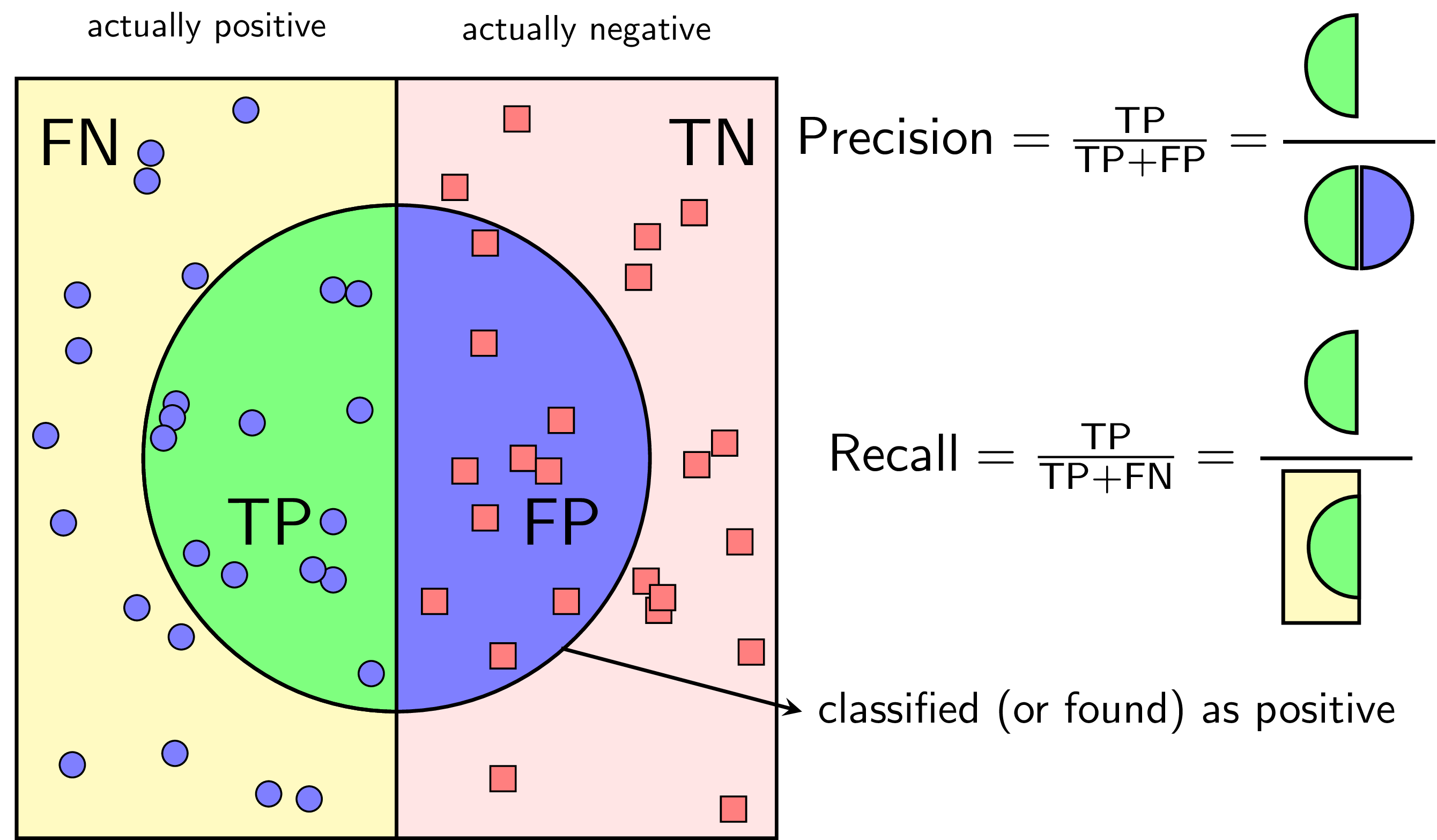
Với một cách xác định một lớp là positive, Precision được định nghĩa là tỉ lệ số điểm true positive trong số những điểm được phân loại là positive (TP + FP).
Recall được định nghĩa là tỉ lệ số điểm true positive trong số những điểm thực sự là positive (TP + FN).
Một cách toán học, Precison và Recall là hai phân số có tử số bằng nhau nhưng mẫu số khác nhau:
\[
\begin{eqnarray}
\text{Precision} &=& \frac{\text{TP}}{\text{TP} + \text{FP}} \
\text{Recall} &=& \frac{\text{TP}}{\text{TP} + \text{FN}}
\end{eqnarray}
\]
Bạn đọc có thể nhận thấy rằng TPR và Recall là hai đại lượng bằng nhau. Ngoài ra, cả Precision và Recall đều là các số không âm nhỏ hơn hoặc bằng một.
Precision cao đồng nghĩa với việc độ chính xác của các điểm tìm được là cao. Recall cao đồng nghĩa với việc True Positive Rate cao, tức tỉ lệ bỏ sót các điểm thực sự positive là thấp.
Ví dụ nhỏ dưới đây thể hiện cách tính Precision và Recall dựa vào Confusion Matrix cho bài toán phân loại nhị phân.
from __future__ import print_function
import numpy as np
# confusion matrix to precision + recall
def cm2pr_binary(cm):
p = cm[0,0]/np.sum(cm[:,0])
r = cm[0,0]/np.sum(cm[0])
return (p, r)
# example of a confusion matrix for binary classification problem
cm = np.array([[100., 10], [20, 70]])
p,r = cm2pr_binary(cm)
print("precition = {0:.2f}, recall = {1:.2f}".format(p, r))
precition = 0.83, recall = 0.91
Khi Precision = 1, mọi điểm tìm được đều thực sự là positive, tức không có điểm negative nào lẫn vào kết quả. Tuy nhiên, Precision = 1 không đảm bảo mô hình là tốt, vì câu hỏi đặt ra là liệu mô hình đã tìm được tất cả các điểm positive hay chưa. Nếu một mô hình chỉ tìm được đúng một điểm positive mà nó chắc chắn nhất thì ta không thể gọi nó là một mô hình tốt.
Khi Recall = 1, mọi điểm positive đều được tìm thấy. Tuy nhiên, đại lượng này lại không đo liệu có bao nhiêu điểm negative bị lẫn trong đó. Nếu mô hình phân loại mọi điểm là positive thì chắc chắn Recall = 1, tuy nhiên dễ nhận ra đây là một mô hình cực tồi.
Một mô hình phân lớp tốt là mô hình có cả Precision và Recall đều cao, tức càng gần một càng tốt. Có hai cách đo chất lượng của bộ phân lớp dựa vào Precision và Reall: Precision-Recall curve và F-score.
5.2. Precision-Recall curve và Average precision
Tương tự như ROC curve, chúng ta cũng có thể đánh giá mô hình dựa trên việc thay đổi một ngưỡng và quan sát giá trị của Precision và Recall. Khái niệm Area Under the Curve (AUC) cũng được định nghĩa tương tự. Với Precision-Recall Curve, AUC còn có một tên khác là Average precision (AP).
Giả sử có \(N\) ngưỡng để tính precision và recall, với mỗi ngưỡng cho một cặp giá trị precision, recall là \(P_n, R_n,~ n= 1, 2, \dots, N\). Precision-Recall curve được vẽ bằng cách vẽ từng điểm có toạ độ \((R_n, P_n)\) trên trục toạ độ và nối chúng với nhau. AP được xác định bằng: \[ \text{AP} = \sum_{n}(R_{n} - R_{n-1})P_n \]
ở đó \((R_{n} - R_{n-1})P_n\) chính là diện tích hình chữ nhật có chiều rộng \((R_{n} - R_{n-1})\) và chiều cao \(P_n\), đây cũng gần với cách tính tích phân dựa trên cách tính diện tích của từng hình chữ nhật nhỏ. (Nếu bạn đọc còn nhớ khái niệm diện tích hình thang cong thì sẽ tưởng tượng ra.)
Xem thêm Precision-Recall–scikit-learn.
5.3. F1-score
$F_1$ score, hay F1-score, là harmonic mean của precision và recall (giả sử rằng hai đại lượng này khác không): \[ \frac{2}{F_1} = \frac{1}{\text{precision}} + \frac{1}{\text{recall}} ~ \text{hay} ~ F_1 = 2\frac{1}{\frac{1}{\text{precision}} + \frac{1}{\text{recall}}} = 2\frac{\text{precion}\cdot{recall}}{\text{precision} + \text{recall}} \]
\(F-1\)-score có giá trị nằm trong nửa khoảng \((0, 1]\). \(F_1\) càng cao, bộ phân lớp càng tốt. Khi cả recall và precision đều bằng 1 (tốt nhất có thể), \(F_1 = 1\). Khi cả recall và precision đều thấp, ví dụ bằng 0.1, \(F_1 = 0.1\). Dưới đây là một vài ví dụ về \(F_1\)
| precision | recall | \(F_1\) |
|---|---|---|
| 1 | 1 | 1 |
| 0.1 | 0.1 | 0.1 |
| 0.5 | 0.5 | 0.5 |
| 1 | 0.1 | 0.182 |
| 0.3 | 0.8 | 0.36 |
Như vậy, một bộ phân lớp với precision = recall = 0.5 tốt hơn một bộ phân lớp khác với precision = 0.3, recall = 0.8 theo cách đo này.
Trường hợp tổng quát của \(F_1\) score là \(F_{\beta}\) score: \[ F_{\beta} = ( 1 + \beta^2)\frac{\text{precision}\cdot\text{recall}}{\beta^2\cdot\text{precision} + \text{recall}} \]
\(F_1\) chính là một trường hợp đặc biệt của \(F_{\beta}\) khi \(\beta = 1\). Khi \(\beta >1\), recall được coi trọng hơn precision, khi \(\beta < 1\), precision được coi trọng hơn. Hai đại lượng \(\beta\) thường được sử dụng là \(\beta = 2\) và \(\beta = 0.5\).
5.4. Precision-recall cho bài toán phân lớp nhiều lớp
Cũng giống như ROC curve, precision-recall curve ban đầu được định nghĩa cho bài toán phân lớp nhị phân. Để có thể áp dụng các phép đo này cho bài toán multi-class classification, các đại lượng đầu ra (ground truth và predicted output) cần được đưa về dạng nhị phân.
Bằng trực giác, ta có thể đưa bài toán phân lớp nhiều lớp về bài toán phân lớp nhị phân bằng cách xem xét từng lớp. Với mỗi lớp, ta coi dữ liệu thuộc lớp đó có label là positive, tất cả các dữ liệu còn lại có label là negative. Sau đó, giá trị Precision, Recall, và PR curve được áp dụng lên từng lớp. Với mỗi lớp, ta sẽ nhận được một cặp giá trị precision và recall. Với các bài toán có ít lớp dữ liệu, ta có thể minh hoạ PR curve cho từng lớp trên cùng một đồ thị. Tuy nhiên, với các bài toán có rất nhiều lớp dữ liệu, việc này đôi khi không khả thi. Thay vào đó, hai phép đánh giá dựa trên Precision-Recall được sử dụng là micro-average và macro-average.
5.4.1. Micro-average
Xét ví dụ bài toán với 3 lớp dữ liệu, bộ phân lớp cho các tham số FP, TP, FN của mỗi lớp là:
tp1, fp1, fn1 = 10, 5, 3
tp2, fp2, fn2 = 17, 7, 10
tp3, fp3, fn3 = 25, 2, 4
from __future__ import print_function
def PR(tp, fp, fn):
P = float(tp)/(tp + fp)
R = float(tp)/(tp + fn)
return (P, R)
(P1, R1) = PR(tp1, fp1, fn1)
(P2, R2) = PR(tp2, fp2, fn2)
(P3, R3) = PR(tp3, fp3, fn2)
print('(P1, R1) = (%.2f, %.2f)'%(P1, R1))
print('(P2, R2) = (%.2f, %.2f)'%(P2, R2))
print('(P3, R3) = (%.2f, %.2f)'%(P3, R3))
(P1, R1) = (0.67, 0.77)
(P2, R2) = (0.71, 0.63)
(P3, R3) = (0.93, 0.71)
Micro-average precision và Micro-average recall đơn giản được tính bằng:
\[
\begin{eqnarray}
\text{micro-average precision} &=& \frac{\sum_{c=1}^C\text{TP}c}{\sum_{c=1}^C(\text{TP}c + \text{FP}c)}\
\text{micro-average recall} &=& \frac{\sum_{c=1}^C\text{TP}c}{\sum_{c=1}^C(\text{TP}c + \text{FN}c)}
\end{eqnarray}
\]
với \(\text{TP}c, \text{FP}c, \text{FN}c\) lần lượt là TP, FP, FN của class \(c\).
Tức TP được tính là tổng của toàn bộ TP của mỗi lớp. Tương tự với FP và FN. Với ví dụ trên, micro-average precision và recall tính được là:
total_tp = tp1 + tp2 + tp3
total_fp = fp1 + fp2 + fp3
total_fn = fn1 + fn2 + fn3
micro_ap = float(total_tp)/(total_tp + total_fp)
micro_ar = float(total_tp)/(total_tp + total_fn)
print('(micro_ap, micro_ar) = (%.2f, %.2f)' % (micro_ap, micro_ar))
(micro_ap, micro_ar) = (0.79, 0.75)
Micro-average F-Score cũng được tính tương tự như F-score nhưng dựa trên micro-average precision và micro-average recall.
5.4.2. Macro-average
Macro-average precision là trung bình cộng của các precision theo class, tương tự với Macro-average recall. Với ví dụ trên, ta có
macro_ap = (P1 + P2 + P3)/3
macro_ar = (R1 + R2 + R3)/3
print('(micro_ap, micro_ar) = (%.2f, %.2f)' % (macro_ap, macro_ar))
(micro_ap, micro_ar) = (0.77, 0.70)
Macro-average F-Score cũng được tính tương tự như F-score nhưng dựa trên macro-average precision và macro-average recall.
6. Tóm tắt
-
Accuracy là tỉ lệ giữa số điểm được phân loại đúng và tổng số điểm. Accuracy chỉ phù hợp với các bài toán mà kích thước các lớp dữ liệu là tương đối như nhau.
-
Confusion matrix giúp có cái nhìn rõ hơn về việc các điểm dữ liệu được phân loại đúng/sai như thế nào.
-
True Positive (TP): số lượng điểm của lớp positive được phân loại đúng là positive.
-
True Negative (TN): số lượng điểm của lớp negative được phân loại đúng là negative.
-
False Positive (FP): số lượng điểm của lớp negative bị phân loại nhầm thành positive.
-
False Negative (FN): số lượng điểm của lớp positiv bị phân loại nhầm thành negative
-
True positive rate (TPR), false negative rate (FNR), false positive rate (FPR), true negative rate (TNR):
| Predicted | Predicted |
| as Positive | as Negative |
------------------|--------------------|--------------------|
Actual: Positive | TPR = TP/(TP + FN) | FNR = FN/(TP + FN) |
------------------|--------------------|--------------------|
Actual: Negative | FPR = FP/(FP + TN) | TNR = TN/(FP + TN) |
------------------|--------------------|--------------------|
-
Khi kích thước các lớp dữ liệu là chênh lệch (imbalanced data hay skew data), precision và recall thường được sử dụng: \[ \begin{eqnarray} \text{Precision} &=& \frac{\text{TP}}{\text{TP} + \text{FP}} \
\text{Recall} &=& \frac{\text{TP}}{\text{TP} + \text{FN}} \end{eqnarray} \] -
\(F_1\) score: \[ F_1 = 2\frac{1}{\frac{1}{\text{precision}} + \frac{1}{\text{recall}}} = 2\frac{\text{precion}\cdot\text{recall}}{\text{precision} + \text{recall}} \]
-
Micro-average precision, micro-average recall: \[ \begin{eqnarray} \text{micro-average precision} &=& \frac{\sum_{c=1}^C\text{TP}c}{\sum_{c=1}^C(\text{TP}c + \text{FP}c)}\
\text{micro-average recall} &=& \frac{\sum_{c=1}^C\text{TP}c}{\sum_{c=1}^C(\text{TP}c + \text{FN}c)} \end{eqnarray} \] với \(\text{TP}c, \text{FP}c, \text{FN}c\) lần lượt là TP, FP, FN của class \(c\). -
Micro-average precision, macro-average recall là trung bình cộng của các precision, recall cho từng lớp. Micro-average (macro-average) \(F_1\) scores cũng được tính dựa trên các micro-average (macro-average) precision, recall tương ứng.
7. Tài liệu tham khảo
[1] Sklearn: Receiver Operating Characteristic (ROC)
[2] Receiver Operating Characteristic (ROC) with cross validation
[3] A systematic analysis of performance measures for classification tasks