
Trong trang này:
-
- Naive Bayes Classifier
-
- Các phân phối thường dùng cho \(p(x_i | c)\)
- 2.1 Gaussian Naive Bayes
- 2.2. Multinomial Naive Bayes
- 2.3. Bernoulli Naive Bayes
- Các phân phối thường dùng cho \(p(x_i | c)\)
-
- Ví dụ
- 3.1. Bắc hay Nam
- 3.2. Bắc hay Nam với sklearn
- 3.3. Naive Bayes Classifier cho bài toán Spam Filtering
- Ví dụ
-
- Tóm tắt
-
- Tài liệu tham khảo
Bạn được khuyến khích đọc Bài 31: Maximum Likelihood và Maximum A Posteriori estimation trước khi đọc bài này
1. Naive Bayes Classifier
Xét bài toán classification với \(C\) classes \(1, 2, \dots, C\). Giả sử có một điểm dữ liệu \(\mathbf{x} \in \mathbb{R}^d\). Hãy tính xác suất để điểm dữ liệu này rơi vào class \(c\). Nói cách khác, hãy tính:
\[ p(y = c |\mathbf{x}) ~~~ (1) \] hoặc viết gọn thành \(p(c|\mathbf{x})\).
Tức tính xác suất để đầu ra là class \(c\) biết rằng đầu vào là vector \(\mathbf{x}\).
Biểu thức này, nếu tính được, sẽ giúp chúng ta xác định được xác suất để điểm dữ liệu rơi vào mỗi class. Từ đó có thể giúp xác định class của điểm dữ liệu đó bằng cách chọn ra class có xác suất cao nhất:
\[ c = \arg\max_{c \in \{1, \dots, C\}} p(c | \mathbf{x}) ~~~~ (2) \]
Biểu thức \((2)\) thường khó được tính trực tiếp. Thay vào đó, quy tắc Bayes thường được sử dụng:
\[
\begin{eqnarray}
c & = & \arg\max_c p(c | \mathbf{x}) & (3) \
& = & \arg\max_c \frac{p(\mathbf{x} | c) p(c)}{p(\mathbf{x})} ~~~& 4)\
& = & \arg\max_c p(\mathbf{x} | c) p(c) & (5)\
\end{eqnarray}
\]
Từ \((3)\) sang \((4)\) là vì quy tắc Bayes. Từ \((4)\) sang \((5)\) là vì mẫu số \(p(\mathbf{x})\) không phụ thuộc vào \(c\).
Tiếp tục xét biểu thức \((5)\), \(p(c)\) có thể được hiểu là xác suất để một điểm rơi vào class \(c\). Giá trị này có thể được tính bằng MLE, tức tỉ lệ số điểm dữ liệu trong tập training rơi vào class này chia cho tổng số lượng dữ liệu trong tập training; hoặc cũng có thể được đánh giá bằng MAP estimation. Trường hợp thứ nhất thường được sử dụng nhiều hơn.
Thành phần còn lại \(p(\mathbf{x} | c)\), tức phân phối của các điểm dữ liệu trong class \(c\), thường rất khó tính toán vì \(\mathbf{x}\) là một biến ngẫu nhiên nhiều chiều, cần rất rất nhiều dữ liệu training để có thể xây dựng được phân phối đó. Để giúp cho việc tính toán được đơn giản, người ta thường giả sử một cách đơn giản nhất rằng các thành phần của biến ngẫu nhiên \(\mathbf{x}\) là độc lập với nhau, nếu biết \(c\) (given \(c\)). Tức là:
\[ p(\mathbf{x} | c) = p(x_1, x_2, \dots, x_d | c) = \prod_{i = 1}^d p(x_i | c) ~~~~~ (6) \]
Giả thiết các chiều của dữ liệu độc lập với nhau, nếu biết \(c\), là quá chặt và ít khi tìm được dữ liệu mà các thành phần hoàn toàn độc lập với nhau. Tuy nhiên, giả thiết ngây ngô này lại mang lại những kết quả tốt bất ngờ. Giả thiết về sự độc lập của các chiều dữ liệu này được gọi là Naive Bayes (xin không dịch). Cách xác định class của dữ liệu dựa trên giả thiết này có tên là Naive Bayes Classifier (NBC).
NBC, nhờ vào tính đơn giản một cách ngây thơ, có tốc độ training và test rất nhanh. Việc này giúp nó mang lại hiệu quả cao trong các bài toán large-scale.
Ở bước training, các phân phối \(p(c)\) và \(p(x_i | c), i = 1, \dots, d\) sẽ được xác định dựa vào training data. Việc xác định các giá trị này có thể dựa vào Maximum Likelihood Estimation hoặc Maximum A Posteriori.
Ở bước test, với một điểm dữ liệu mới \(\mathbf{x}\), class của nó sẽ được xác đinh bởi:
\[ c = \arg\max_{c \in \{1, \dots, C\}} p(c) \prod_{i=1}^d p(x_i | c) ~~~~~ (7) \]
Khi \(d\) lớn và các xác suất nhỏ, biểu thức ở vế phải của \((7)\) sẽ là một số rất nhỏ, khi tính toán có thể gặp sai số. Để giải quyết việc này, \((7)\) thường được viết lại dưới dạng tương đương bằng cách lấy \(\log\) của vế phải: \[ c = \arg\max_{c \in \{1, \dots, C\}} = \log(p(c)) + \sum_{i=1}^d \log(p(x_i | c)) ~~~~ (7.1) \]
Việc này không ảnh hưởng tới kết quả vì \(\log\) là một hàm đồng biến trên tập các số dương.
Mặc dù giả thiết mà Naive Bayes Classifiers sử dụng là quá phi thực tế, chúng vẫn hoạt động khá hiệu quả trong nhiều bài toán thực tế, đặc biệt là trong các bài toán phân loại văn bản, ví dụ như lọc tin nhắn rác hay lọc email spam. Trong phần sau của bài viết, chúng ta cùng xây dựng một bộ lọc email spam tiếng Anh đơn giản.
Cả việc training và test của NBC là cực kỳ nhanh khi so với các phương pháp classification phức tạp khác. Việc giả sử các thành phần trong dữ liệu là độc lập với nhau, nếu biết class, khiến cho việc tính toán mỗi phân phối \(p(\mathbf{x}_i|c)\) trở nên cực kỳ nhanh.
Mỗi giá trị \(p(c), c = 1, 2, \dots, C\) có thể được xác định như là tần suất xuất hiện của class \(c\) trong training data.
Việc tính toán \(p(\mathbf{x_i} | c) \) phụ thuộc vào loại dữ liệu. Có ba loại được sử dụng phổ biến là: Gaussian Naive Bayes, Multinomial Naive Bayes, và Bernoulli Naive .
2. Các phân phối thường dùng cho \(p(x_i | c)\)
Mục này chủ yếu được dịch từ tài liệu của thư viện sklearn.
2.1 Gaussian Naive Bayes
Mô hình này được sử dụng chủ yếu trong loại dữ liệu mà các thành phần là các biến liên tục.
Với mỗi chiều dữ liệu \(i\) và một class \(c\), \(x_i\) tuân theo một phân phối chuẩn có kỳ vọng \(\mu_{ci}\) và phương sai \(\sigma_{ci}^2\):
\[ p(x_i|c) = p(x_i | \mu_{ci}, \sigma_{ci}^2) = \frac{1}{\sqrt{2\pi \sigma_{ci}^2}} \exp\left(- \frac{(x_i - \mu_{ci})^2}{2 \sigma_{ci}^2}\right) ~~~~ (8) \]
Trong đó, bộ tham số \(\theta = \{\mu_{ci}, \sigma_{ci}^2\}\) được xác định bằng Maximum Likelihood:
\[ (\mu_{ci}, \sigma_{ci}^2) = \arg\max_{\mu_{ci}, \sigma_{ci}^2} \prod_{n = 1}^N p(x_i^{(n)} | \mu_{ci}, \sigma_{ci}^2) ~~~~ (9) \]
Đây là cách tính của thư viện sklearn. Chúng ta cũng có thể đánh giá các tham số bằng MAP nếu biết trước priors của \(\mu_{ci}\) và \(\sigma^2_{ci}\)
2.2. Multinomial Naive Bayes
Mô hình này chủ yếu được sử dụng trong phân loại văn bản mà feature vectors được tính bằng Bags of Words. Lúc này, mỗi văn bản được biểu diễn bởi một vector có độ dài \(d\) chính là số từ trong từ điển. Giá trị của thành phần thứ \(i\) trong mỗi vector chính là số lần từ thứ \(i\) xuất hiện trong văn bản đó.
Khi đó, \(p(x_i |c) \) tỉ lệ với tần suất từ thứ \(i\) (hay feature thứ \(i\) cho trường hợp tổng quát) xuất hiện trong các văn bản của class \(c\). Giá trị này có thể được tính bằng cách: \[ \lambda_{ci} = p(x_i | c) = \frac{N_{ci}}{N_c} ~~~~ (10) \] Trong đó:
-
\(N_{ci}\) là tổng số lần từ thứ \(i\) xuất hiện trong các văn bản của class \(c\), nó được tính là tổng của tất cả các thành phần thứ \(i\) của các feature vectors ứng với class \(c\).
-
\(N_c\) là tổng số từ (kể cả lặp) xuất hiện trong class \(c\). Nói cách khác, nó bằng tổng độ dài của toàn bộ các văn bản thuộc vào class \(c\). Có thể suy ra rằng \(N_c = \sum_{i = 1}^d N_{ci}\), từ đó \(\sum_{i=1}^d \lambda_{ci} = 1\).
Cách tính này có một hạn chế là nếu có một từ mới chưa bao giờ xuất hiện trong class \(c\) thì biểu thức \((10)\) sẽ bằng 0, điều này dẫn đến vế phải của \((7)\) bằng 0 bất kể các giá trị còn lại có lớn thế nào. Việc này sẽ dẫn đến kết quả không chính xác (xem thêm ví dụ ở mục sau).
Để giải quyết việc này, một kỹ thuật được gọi là Laplace smoothing được áp dụng:
\[ \hat{\lambda}_{ci} = \frac{N_{ci} + \alpha}{N_{c} + d\alpha} ~~~~~~ (11) \]
Với \(\alpha\) là một số dương, thường bằng 1, để tránh trường hợp tử số bằng 0. Mẫu số được cộng với \(d\alpha\) để đảm bảo tổng xác suất \(\sum_{i=1}^d \hat{\lambda}_{ci} = 1\).
Như vậy, mỗi class \(c\) sẽ được mô tả bởi bộ các số dương có tổng bằng 1: \(\hat{\lambda}_c = \{\hat{\lambda}_{c1}, \dots, \hat{\lambda}_{cd}\}\).
2.3. Bernoulli Naive Bayes
Mô hình này được áp dụng cho các loại dữ liệu mà mỗi thành phần là một giá trị binary - bẳng 0 hoặc 1. Ví dụ: cũng với loại văn bản nhưng thay vì đếm tổng số lần xuất hiện của 1 từ trong văn bản, ta chỉ cần quan tâm từ đó có xuất hiện hay không.
Khi đó, \(p(x_i | c) \) được tính bằng: \[ p(x_i | c) = p(i | c)^{x_i} (1 - p(i | c) ^{1 - x_i} \] với \(p(i | c)\) có thể được hiểu là xác suất từ thứ \(i\) xuất hiện trong các văn bản của class \(c\).
3. Ví dụ
3.1. Bắc hay Nam
Giả sử trong tập training có các văn bản \(\text{d1, d2, d3, d4}\) như trong bảng dưới đây. Mỗi văn bản này thuộc vào 1 trong 2 classes: \(\text{B}\) (Bắc) hoặc \(\text{N}\) (Nam). Hãy xác định class của văn bản \(\text{d5}\).
| Document | Content | Class | |
|---|---|---|---|
| Training | \(\text{d1}\) | \(\text{hanoi pho chaolong hanoi}\) | \(\text{B}\) |
| \(\text{d2}\) | \(\text{hanoi buncha pho omai}\) | \(\text{B}\) | |
| \(\text{d3}\) | \(\text{pho banhgio omai}\) | \(\text{B}\) | |
| \(\text{d4}\) | \(\text{saigon hutiu banhbo pho}\) | \(\text{N}\) | |
| Test | \(\text{d5}\) | \(\text{hanoi hanoi buncha hutiu}\) | ? |
Ta có thể dự đoán rằng \(\text{d5}\) thuộc class Bắc.
Bài toán này có thể được giải quyết bởi hai mô hình: Multinomial Naive Bayes và Bernoulli Naive Bayes. Tôi sẽ làm ví dụ minh hoạ với mô hình thứ nhất và thực hiện code cho cả hai mô hình. Việc mô hình nào tốt hơn phụ thuộc vào mỗi bài toán. Chúng ta có thể thử cả hai để chọn ra mô hình tốt hơn.
Nhận thấy rằng ở đây có 2 class \(\text{B}\) và \(\text{N}\), ta cần đi tìm \(p(\text{B})\) và \(p(\text{N})\). à dựa trên tần số xuất hiện của mỗi class trong tập training. Ta sẽ có:
\[ p(\text{B}) = \frac{3}{4}, ~~~~~ p(\text{N}) = \frac{1}{4} ~~~~~~ (8) \]
Tập hợp toàn bộ các từ trong văn bản, hay còn gọi là từ điển, là: \(V = \{\text{hanoi, pho, chaolong, buncha, omai, banhgio, saigon, hutiu, banhbo}\}\). Tổng cộng số phần tử trong từ điển là \(|V| = 9\).
Hình dưới đây minh hoạ quá trình Training và Test cho bài toán này khi sử dụng Multinomial Naive Bayes, trong đó có sử dụng Laplace smoothing với \(\alpha = 1\).
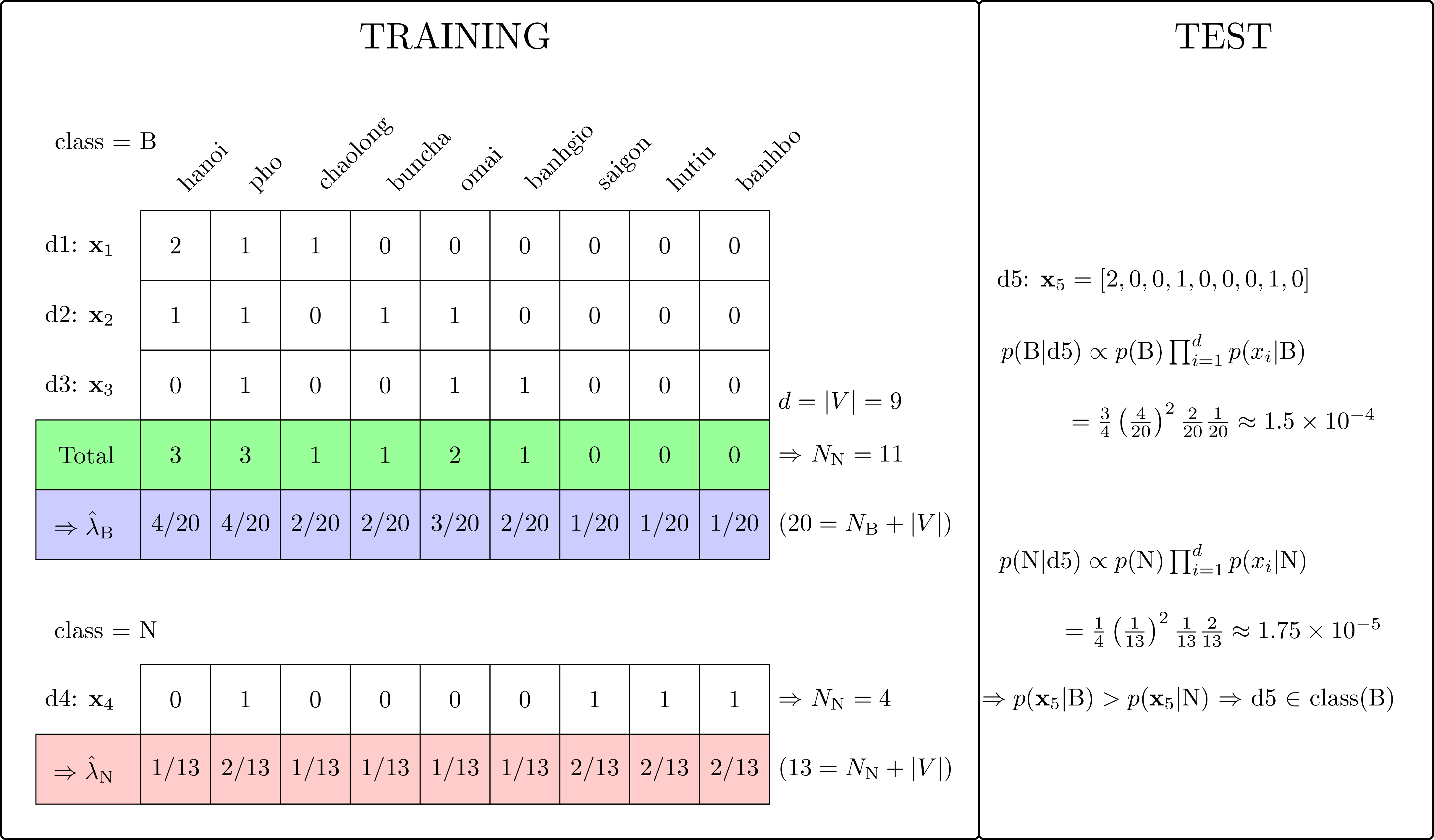
Chú ý, hai giá trị tìm được \(1.5\times 10^{-4}\) và \(1.75\times 10^{-5}\) không phải là hai xác suất cần tìm mà chỉ là hai đại lượng tỉ lệ thuận với hai xác suất đó. Để tính cụ thể, ta có thể làm như sau:
\[ p(\text{B} | \text{d5}) = \frac{1.5\times 10^{-4}}{1.5\times 10^{-4} + 1.75\times 10^{-5}} \approx 0.8955, ~~~~ p(\text{N} | \text{d5}) = 1 - p(\text{B} | \text{d5}) \approx 0.1045 \]
Bạn đọc có thể tự tính với ví dụ khác: \(\text{d6 = pho hutiu banhbo}\). Nếu bạn và tôi tính ra kết quả giống nhau, chúng ta sẽ thu được: \[ p(\text{B} | \text{d6}) \approx 0.29, ~~~~ p(\text{N} | \text{d6}) \approx 0.71 \]
và suy ra \(\text{d6}\) thuộc vào class Nam.
3.2. Bắc hay Nam với sklearn
Để kiểm tra lại các phép tính toán phía trên, chúng ta cùng giải quyết bài toán này với sklearn.
from __future__ import print_function
from sklearn.naive_bayes import MultinomialNB
import numpy as np
# train data
d1 = [2, 1, 1, 0, 0, 0, 0, 0, 0]
d2 = [1, 1, 0, 1, 1, 0, 0, 0, 0]
d3 = [0, 1, 0, 0, 1, 1, 0, 0, 0]
d4 = [0, 1, 0, 0, 0, 0, 1, 1, 1]
train_data = np.array([d1, d2, d3, d4])
label = np.array(['B', 'B', 'B', 'N'])
# test data
d5 = np.array([[2, 0, 0, 1, 0, 0, 0, 1, 0]])
d6 = np.array([[0, 1, 0, 0, 0, 0, 0, 1, 1]])
## call MultinomialNB
clf = MultinomialNB()
# training
clf.fit(train_data, label)
# test
print('Predicting class of d5:', str(clf.predict(d5)[0]))
print('Probability of d6 in each class:', clf.predict_proba(d6))
Kết quả:
Predicting class of d5: B
Probability of d6 in each class: [[ 0.29175335 0.70824665]]
Nếu sử dụng mô hình Bernoulli Naive Bayes, chúng ta cần thay đổi một chút về feature vectors. Lúc này, các giá trị khác không sẽ đều được đưa về 1 vì ta chỉ quan tâm đến việc từ đó có xuất hiện trong văn bản không.
from __future__ import print_function
from sklearn.naive_bayes import BernoulliNB
import numpy as np
# train data
d1 = [1, 1, 1, 0, 0, 0, 0, 0, 0]
d2 = [1, 1, 0, 1, 1, 0, 0, 0, 0]
d3 = [0, 1, 0, 0, 1, 1, 0, 0, 0]
d4 = [0, 1, 0, 0, 0, 0, 1, 1, 1]
train_data = np.array([d1, d2, d3, d4])
label = np.array(['B', 'B', 'B', 'N']) # 0 - B, 1 - N
# test data
d5 = np.array([[1, 0, 0, 1, 0, 0, 0, 1, 0]])
d6 = np.array([[0, 1, 0, 0, 0, 0, 0, 1, 1]])
## call MultinomialNB
clf = BernoulliNB()
# training
clf.fit(train_data, label)
# test
print('Predicting class of d5:', str(clf.predict(d5)[0]))
print('Probability of d6 in each class:', clf.predict_proba(d6))
Kết quả:
Predicting class of d5: B
Probability of d6 in each class: [[ 0.16948581 0.83051419]]
Ta thấy rằng, với bài toán nhỏ này, cả hai mô hình đều cho kết quả giống nhau (xác suất tìm được khác nhau nhưng không ảnh hưởng tới quyết định cuối cùng).
3.3. Naive Bayes Classifier cho bài toán Spam Filtering
Dữ liệu trong ví dụ này được lấy trong Exercise 6: Naive Bayes - Machine Learning - Andrew Ng.
Trong ví dụ này, dữ liệu đã được xử lý, và là một tập con của cơ sở dữ liệu Ling-Spam Dataset.
Mô tả dữ liệu:
Tập dữ liệu này bao gồm tổng cộng 960 emails tiếng Anh, được tách thành tập training và test theo tỉ lệ 700:260, 50% trong mỗi tập là các spam emails.
Dữ liệu trong cơ sở dữ liệu này đã được xử lý khá đẹp. Các quy tắc xử lý như sau:
-
Loại bỏ stop words: Những từ xuất hiện thường xuyên như ‘and’, ‘the’, ‘of’, … được loại bỏ.
-
Lemmatization: Những từ có cùng ‘gốc’ được đưa về cùng loại. Ví dụ, ‘include’, ‘includes’, ‘included’ đều được đưa chung về ‘include’. Tất cả các từ cũng đã được đưa về dạng ký tự thường (không phải HOA).
-
Loại bỏ non-words: Số, dấu câu, ký tự ‘tabs’, ký tự ‘xuống dòng’ đã được loại bỏ.
Dưới đây là một ví dụ của 1 email không phải spam, trước khi được xử lý:
Subject: Re: 5.1344 Native speaker intuitions
The discussion on native speaker intuitions has been extremely interesting,
but I worry that my brief intervention may have muddied the waters. I take
it that there are a number of separable issues. The first is the extent to
which a native speaker is likely to judge a lexical string as grammatical
or ungrammatical per se. The second is concerned with the relationships
between syntax and interpretation (although even here the distinction may
not be entirely clear cut).
và sau khi được xử lý:
re native speaker intuition discussion native speaker intuition extremely
interest worry brief intervention muddy waters number separable issue first
extent native speaker likely judge lexical string grammatical ungrammatical
per se second concern relationship between syntax interpretation although
even here distinction entirely clear cut
Và đây là một ví dụ về spam email sau khi được xử lý:
financial freedom follow financial freedom work ethic extraordinary desire
earn least per month work home special skills experience required train
personal support need ensure success legitimate homebased income
opportunity put back control finance life ve try opportunity past
fail live promise
Chúng ta thấy rằng trong đoạn này có các từ như: financial, extraordinary, earn, opportunity, … là những từ thường thấy trong các email spam.
Trong ví dụ này, chúng ta sẽ sử dụng Multinomial Naive Bayes.
Để cho bài toán được đơn giản hơn, tôi tiếp tục sử dụng dữ liệu đã được xử lý, có thể được download ở đây: ex6DataPrepared.zip. Trong folder sau khi giải nén, chúng ta sẽ thấy các files:
test-features.txt
test-labels.txt
train-features-50.txt
train-features-100.txt
train-features-400.txt
train-features.txt
train-labels-50.txt
train-labels-100.txt
train-labels-400.txt
train-labels.txt
tương ứng với các file chứa dữ liệu của tập training và tập test. File train-features-50.txt chứa dữ liệu của tập training thu gọn với chỉ có tổng cộng 50 training emails.
Mỗi file *labels*.txt chứa nhiều dòng, mỗi dòng là một ký tự 0 hoặc 1 thể hiện email là non-spam hoặc spam.
Mỗi file *features*.txt chứa nhiều dòng, mỗi dòng có 3 số, ví dụ:
1 564 1
1 19 2
trong đó số đầu tiên là chỉ số của email, bắt đầu từ 1; số thứ hai là thứ tự của từ trong từ điển (tổng cộng 2500 từ); số thứ ba là số lượng của từ đó trong email đang xét. Dòng đầu tiên nói rằng trong email thứ nhất, từ thứ 564 trong từ điển xuất hiện 1 lần. Cách lưu dữ liệu như thế này giúp tiết kiệm bộ nhớ vì 1 email thường không chứa hết tất cả các từ trong từ điển mà chỉ chứa một lượng nhỏ, ta chỉ cần lưu các giá trị khác không.
Nếu ta biểu diễn feature vector của mỗi email là một vector hàng có độ dài bằng độ dài từ điển (2500) thì dòng thứ nhất nói rằng thành phần thứ 564 của vector này bằng 1. Tương tự, thành phần thứ 19 của vector này bằng 1. Nếu không xuất hiện, các thành phần khác được mặc định bằng 0.
Dựa trên các thông tin này, chúng ta có thể tiến hành lập trình với thư viện sklearn.
Khai báo thư viện và đường dẫn tới files:
## packages
from __future__ import division, print_function, unicode_literals
import numpy as np
from scipy.sparse import coo_matrix # for sparse matrix
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.metrics import accuracy_score # for evaluating results
# data path and file name
path = 'ex6DataPrepared/'
train_data_fn = 'train-features.txt'
test_data_fn = 'test-features.txt'
train_label_fn = 'train-labels.txt'
test_label_fn = 'test-labels.txt'
Hàm số đọc dữ liệu từ file data_fn với labels tương ứng label_fn. Chú ý rằng số lượng từ trong từ điển là 2500.
Dữ liệu sẽ được lưu trong một ma trận mà mỗi hàng thể hiện một email. Ma trận này là một ma trận sparse nên chúng ta sẽ sử dụng hàm scipy.sparse.coo_matrix.
nwords = 2500
def read_data(data_fn, label_fn):
## read label_fn
with open(path + label_fn) as f:
content = f.readlines()
label = [int(x.strip()) for x in content]
## read data_fn
with open(path + data_fn) as f:
content = f.readlines()
# remove '\n' at the end of each line
content = [x.strip() for x in content]
dat = np.zeros((len(content), 3), dtype = int)
for i, line in enumerate(content):
a = line.split(' ')
dat[i, :] = np.array([int(a[0]), int(a[1]), int(a[2])])
# remember to -1 at coordinate since we're in Python
# check this: https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.coo_matrix.html
# for more information about coo_matrix function
data = coo_matrix((dat[:, 2], (dat[:, 0] - 1, dat[:, 1] - 1)),\
shape=(len(label), nwords))
return (data, label)
Đọc training data và test data, sử dụng class MultinomialNB trong sklearn để xây dựng mô hình và dự đoán đầu ra cho test data.
(train_data, train_label) = read_data(train_data_fn, train_label_fn)
(test_data, test_label) = read_data(test_data_fn, test_label_fn)
clf = MultinomialNB()
clf.fit(train_data, train_label)
y_pred = clf.predict(test_data)
print('Training size = %d, accuracy = %.2f%%' % \
(train_data.shape[0],accuracy_score(test_label, y_pred)*100))
Training size = 700, accuracy = 98.08%
Vậy là có tới 98.08% các email được phân loại đúng. Chúng ta tiếp tục thử với các bộ dữ liệu training nhỏ hơn:
train_data_fn = 'train-features-100.txt'
train_label_fn = 'train-labels-100.txt'
test_data_fn = 'test-features.txt'
test_label_fn = 'test-labels.txt'
(train_data, train_label) = read_data(train_data_fn, train_label_fn)
(test_data, test_label) = read_data(test_data_fn, test_label_fn)
clf = MultinomialNB()
clf.fit(train_data, train_label)
y_pred = clf.predict(test_data)
print('Training size = %d, accuracy = %.2f%%' % \
(train_data.shape[0],accuracy_score(test_label, y_pred)*100))
Training size = 100, accuracy = 97.69%
train_data_fn = 'train-features-50.txt'
train_label_fn = 'train-labels-50.txt'
test_data_fn = 'test-features.txt'
test_label_fn = 'test-labels.txt'
(train_data, train_label) = read_data(train_data_fn, train_label_fn)
(test_data, test_label) = read_data(test_data_fn, test_label_fn)
clf = MultinomialNB()
clf.fit(train_data, train_label)
y_pred = clf.predict(test_data)
print('Training size = %d, accuracy = %.2f%%' % \
(train_data.shape[0],accuracy_score(test_label, y_pred)*100))
Training size = 50, accuracy = 97.31%
Ta thấy rằng thậm chí khi tập training là rất nhỏ, 50 emails tổng cộng, kết quả đạt được đã rất ấn tượng.
Nếu bạn muốn tiếp tục thử mô hình BernoulliNB:
clf = BernoulliNB(binarize = .5)
clf.fit(train_data, train_label)
y_pred = clf.predict(test_data)
print('Training size = %d, accuracy = %.2f%%' % \
(train_data.shape[0],accuracy_score(test_label, y_pred)*100))
Training size = 50, accuracy = 69.62%
Ta thấy rằng trong bài toán này, MultinomialNB hoạt động hiệu quả hơn.
4. Tóm tắt
-
Naive Bayes Classifiers (NBC) thường được sử dụng trong các bài toán Text Classification.
-
NBC có thời gian training và test rất nhanh. Điều này có được là do giả sử về tính độc lập giữa các thành phần, nếu biết class.
-
Nếu giả sử về tính độc lập được thoả mãn (dựa vào bản chất của dữ liệu), NBC được cho là cho kết quả tốt hơn so với SVM và logistic regression khi có ít dữ liệu training.
-
NBC có thể hoạt động với các feature vector mà một phần là liên tục (sử dụng Gaussian Naive Bayes), phần còn lại ở dạng rời rạc (sử dụng Multinomial hoặc Bernoulli).
-
Khi sử dụng Multinomial Naive Bayes, Laplace smoothing thường được sử dụng để tránh trường hợp 1 thành phần trong test data chưa xuất hiện ở training data.
5. Tài liệu tham khảo
[1] Text Classification and Naive Bayes - Stanford
[2] Exercise 6: Naive Bayes - Machine Learning - Andrew Ng
[4] 6 Easy Steps to Learn Naive Bayes Algorithm (with code in Python)