
Trước Deep Learning, bài toán phân loại ảnh (các loại dữ liệu khác cũng tương tự) thường được chia thành 2 bước: Feature Engineering và Train a Classifier. Hai bước này thường được tách rời nhau. Với Feature Engineering, các phương pháp thường được sử dụng cho ảnh là SIFT (Scale Invariant Feature Transform), SURF (Speeded-Up Robust Features), HOG (Histogram of Oriented Gradients), LBP (Local Binary Pattern), etc. Các Classifier thường được sử dụng là multi-class SVM, Softmax Regression, Discriminative Dictionary Learning, Random Forest, etc.
Các phương pháp Feature Engineering nêu trên thường được gọi là các hand-crafted features (feature được tạo thủ công) vì nó chủ yếu dựa trên các quan sát về đặc tính riêng của ảnh. Các phương pháp này cho kết quả khá ấn tượng trong một số trường hợp. Tuy nhiên, chúng vẫn còn nhiều hạn chế vì quá trình tìm ra các features và các classifier phù hợp vẫn là riêng biệt.
(Tôi đã từng đề cập tới vấn đề này trong các mô hình end-to-end)
Những năm gần đây, Deep Learning phát triển cực nhanh dựa trên lượng dữ liệu training khổng lồ và khả năng tính toán ngày càng được cải tiến của các máy tính. Các kết quả cho bài toán phân loại ảnh ngày càng được nâng cao. Bộ cơ sở dữ liệu thường được dùng nhất là ImageNet với 1.2M ảnh cho 1000 classes khác nhau. Rất nhiều các mô hình Deep Learning đã giành chiến thắng trong các cuộc thi ILSVRC (ImageNet Large Scale Visual Recognition Challenge). Có thể kể ra một vài: AlexNet, ZFNet, GoogLeNet, ResNet, VGG.
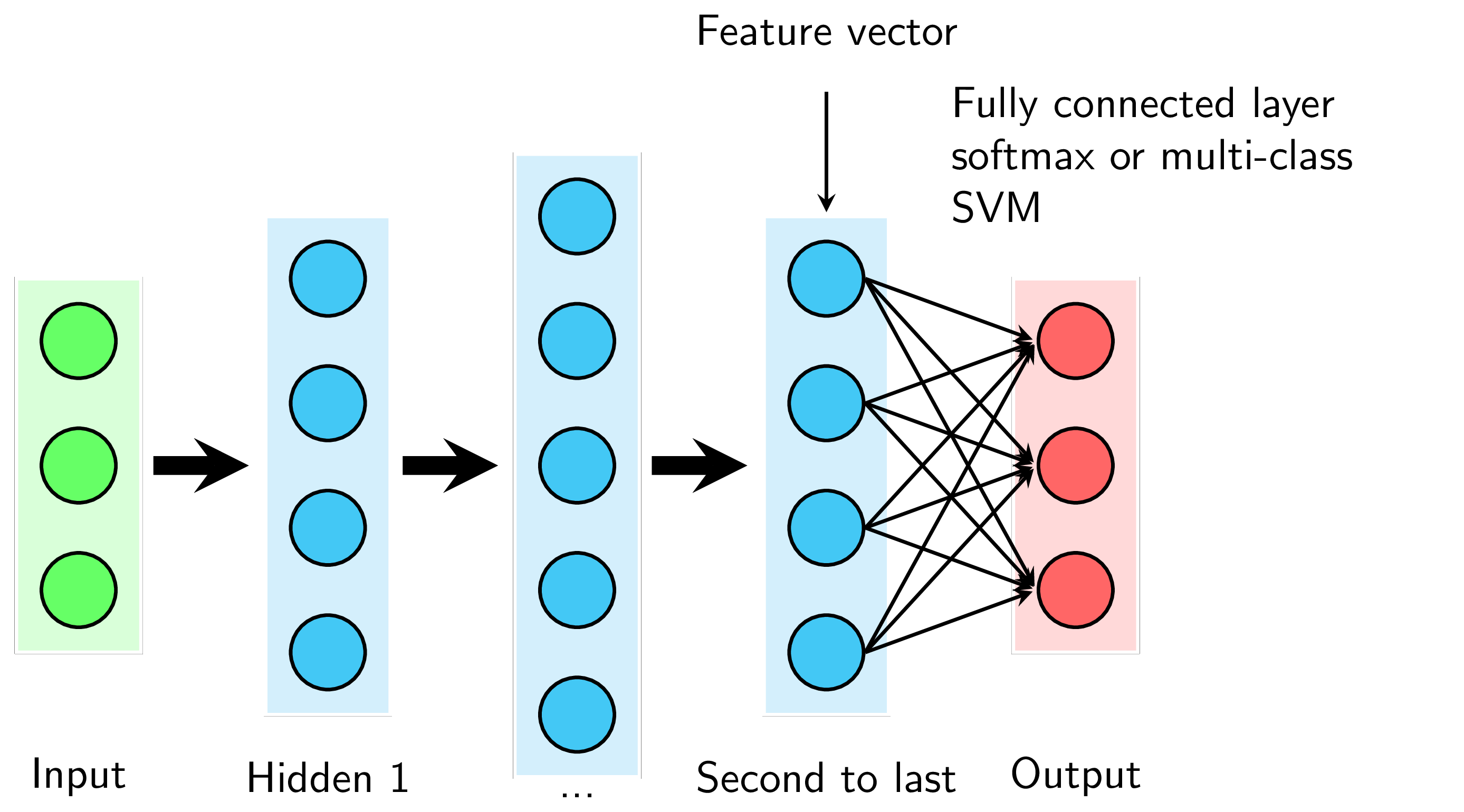
Nhìn chung, các mô hình này đều bao gồm rất nhiều layers. Các layers phía trước thường là các Convolutional layers kết hợp với các nonlinear activation functions và pooling layers (và được gọi chung là ConvNet). Layer cuối cùng là một Fully Connected Layer và thường là một Softmax Regression (Xem Hình 1). Số lượng units ở layer cuối cùng bằng với số lượng classes (với ImageNet là 1000). Vì vậy output ở layer gần cuối cùng (second to last layer) có thể được coi là feature vectors và Softmax Regression chính là Classifier được sử dụng.
Chính nhờ việc features và classifier được trained cùng nhau qua deep networks khiến cho các mô hình này đạt kết quả tốt. Tuy nhiên, những mô hình này đều là các Deep Networks với rất nhiều layers. Việc training dựa trên 1.2M bức ảnh của ImageNet cũng tốn rất nhiều thời gian (2-3 tuần).
Với các bài toàn dựa trên tập dữ liệu khác, rất ít khi người ta xây dựng và train lại toàn bộ Network từ đầu, bởi vì có rất ít các cơ sở dữ liệu có kích thước lớn. Thay vào đó, phương pháp thường được dùng là sử dụng các mô hình (nêu phía trên) đã được trained từ trước, và sử dụng một vài kỹ thuật khác để giải quyết bài toán. Phương pháp sử dụng các mô hình có sẵn như thế này được gọi là Transfer Learning.
Như đã đề cập, toàn bộ các layer trừ output layer có thể được coi là một bộ Feature Extractor. Dựa trên nhận xét rằng các bức ảnh đều có những đặc tính giống nhau nào đó, với cơ sở dữ liệu khác, ta cũng có thể sử dụng phần Feature Extractor này để tạo ra các feature vectors. Sau đó, ta thay output layer cũng bằng một Softmax Regression (hoặc multi-class SVM) nhưng với số lượng units bằng với số lượng class ở bộ cơ sở dữ liệu mới. Ta chỉ cần train layer cuối cùng này. Kinh nghiệm thực tế của tôi cho thấy, việc làm này đã tăng kết quả phân lớp lên rất nhiều so với việc sử dụng các hand-crafted features.
Cách làm như trên được gọi là ConvNet as fixed feature extractor, tức ta sử dụng trực tiếp vector ở second to last layer làm feature vector. Nếu tiếp tục tinh chỉnh (Fine-tuning) một chút nữa, kết quả sẽ có thể tốt hơn.
Fine-tuning the ConvNet. Hướng tiếp cận thứ hai là sử dụng các weights đã được trained từ một trong các mô hình ConvNet như là khởi tạo cho mô hình mới với dữ liệu mới và sử dụng Back Propagation để train lại toàn bộ mô hình mới hoặc train lại một số layer cuối (cũng là để tránh overfitting khi mà mô hình quá phức tạp khi dữ liệu không đủ lớn). Việc này được dựa trên quan sát rằng những layers đầu trong ConvNet thường giúp extract những đặc tính chung của ảnh (các cạnh - edges, còn được gọi là low-level features), các layers cuối thường mang những đặc trưng riêng của cơ sở dữ liệu (CSDL) (và được gọi là high-level features). Vì vậy, việc train các layer cuối mang nhiều giá trị hơn.
Dựa trên kích thước và độ tương quan giữa CSDL mới và CSDL gốc (chủ yếu là ImageNet) để train các mô hình có sẵn, CS231n đưa ra một vài lời khuyên:
-
CSDL mới là nhỏ và tương tự như CSDL gốc. Vì CSDL mới nhỏ, việc tiếp tục train model dễ dẫn đến hiện tượng overfitting. Cũng vì hai CSDL là tương tự nhau, ta dự đoán rằng các high-level features là tương tự nhau. Vậy nên ta không cần train lại model mà chỉ cần train một classifer dựa trên feature vectors ở đầu ra ở layer gần cuối.
-
CSDL mới là lớn và tương tự như CSDL gốc. Vì CSDL này lớn, overfitting ít có khả năng xảy ra hơn, ta có thể train mô hình thêm một chút nữa (toàn bộ hoặc chỉ một vài layers cuối).
-
CSDL mới là nhỏ và rất khác với CSDL gốc. Vì CSDL này nhỏ, tốt hơn hết là dùng các classifier đơn giản (các linear classifiers) để tránh overfitting). Nếu muốn train thêm, ta cũng chỉ nên train các layer cuối. Hoặc có một kỹ thuật khác là coi đầu ra của một layer xa layer cuối hơn làm các feature vectors.
-
CSDL mới là lớn và rất khác CSDL gốc. Trong trường hợp này, ta vẫn có thể sử dụng mô hình đã train như là điểm khởi tạo cho mô hình mới, không nên train lại từ đầu.
Có một điểm đáng chú ý nữa là khi tiếp tục train các mô hình này, ta chỉ nên chọn learning rate nhỏ để các weights mới không đi quá xa so với các weights đã được trained ở các mô hình trước.
Đọc thêm
[1] Introduction to SIFT (Scale-Invariant Feature Transform) - OpenCV
[2] Introduction to SURF (Speeded-Up Robust Features) - OpenCV
[3] Histogram of Oriented Gradients - OpenCV
[5] Transfer Learning - Machine Learning’s Next Frontier
[6] Transfer learning & The art of using Pre-trained Models in Deep Learning