
Trong trang này:
1. Giới thiệu
Cho tới thời điểm này, kế hoạch viết về phần Machine Learning cơ bản của tôi đã thực hiện được 1 nửa. Trong nửa đầu của blog, các bạn đã làm quen (lại) rất nhiều với Đại số tuyến tính và Tối ưu.
Nhìn chung, tôi đều viết các thuật toán Machine Learning dưới dạng các bài toán tối ưu và cách giải mỗi bài toán đó.
Các bài viết trong nửa đầu có thể chia thành các Phần:
-
Bài 1-6: Làm quen với Machine Learning. Một vài thuật toán Machine Learning cơ bản chưa cần nhiều tới tối ưu.
-
Bài 7-8: Gradient Descent. Thuật toán tối ưu đơn giản mà hiệu quả cho các bài toán tối ưu không ràng buộc.
-
Bài 9-15: Neural Networks. Phần này giúp các bạn nắm được các thành phần cơ bản của một Neural Network và các Networks cơ bản nhất, chủ yếu cho các bài toán classification. Các bài toán tối ưu đều là không ràng buộc, các hàm mất mát hầu hết là không lồi, nghiệm tìm được là các local optimal.
-
Bài 16-18: Convex Optimization. Phần này bắt đầu sâu hơn một chút về Tối ưu. Định nghĩa về tập lồi, hàm lồi, bài toán tối ưu lồi và bài toán đối ngẫu. Đây là nền tảng cho rất nhiều thuật toán cơ bản Machine Learning sau này.
-
Bài 19-22: Support Vector Machine. Đây là một trong những thuật toán đẹp nhất và ‘intuitive’ nhất trong Machine Learning. Nếu bạn vào wiki tìm ‘Machine Learning’ thì sẽ thấy hình đại diện chính là SVM và Kernel SVM. Một trong những điều lý thú của SVM là bài toán tối ưu là lồi và nghiệm tìm được là duy nhất, cũng là global optimal.
-
Bài 23-25: Recommendation Systems. Đây là một lớp các bài toán thực tế và quan trọng của Machine Learning. Tôi chủ động thêm phần này vào vì làm giảm lượng toán đã đề cập quá nhiều trong Phần 4 và 5. Các thuật toán và bài toán trong phần này khá đơn giản nhưng kết quả khá tốt.
-
Bài 26-29: Dimensionality Reduction. Phần này cũng rất quan trọng trong Machine Learning. PCA gần như được dùng trong hầu hết các bài toán ML, trong khi LDA hiệu quả trong các bài toán classification. SVD, sau này các bạn sẽ thấy, được dùng rất nhiều vì những tính chất đẹp của nó.
Trong nửa còn lại, tôi sẽ đi vào một mảng lớn khác của ML trong đó các kiến thức về xác suất thống kê được áp dụng rất nhiều, tôi tạm gọi phần này là Bayesian Machine Learning. Các bạn sẽ từ từ được ôn lại kiến thức về Xác Suất Thống Kê và làm quen với các thuật toán Machine Learning cơ bản khác.
Trong bài viết này, tôi sẽ ôn tập lại những kiến thức về Xác Suất thường được sử dụng trong Machine Learning. Mục 2 sẽ nhắc lại về biến ngẫu nhiên, xác suất đồng thời, xác suất biên, xác suất có điều kiện, và quy tắc Bayes. Mục 3 sẽ nhác lại một vài phân bố xác suất thường dùng.
Phần này được viết dựa trên Chương 2 và 3 của cuốn Computer Vision: Models, Learning, and Inference - Simon J.D. Prince.
2. Xác Suất
2.1. Random variables
Một biến ngẫu nhiên (random variable) \(x\) là một đại lượng dùng để đo những đại lượng không xác định. Biến này có thể ký hiệu kết quả/đầu ra (outcome) của một thí nghiệm (ví dụ như tung đồng xu) hoặc một đại lượng biến đổi trong tự nhiên (ví dụ như nhiệt độ trong ngày). Nếu chúng ta quan sát rất nhiều đầu ra \( \{x_i\}_{i=1}^I\) của các thí nghiệm này, ta có thể nhận được những giá trị khác nhau ở mỗi thí nghiệm. Tuy nhiên, sẽ có những giá trị xảy ra nhiều lần hơn những giá trị khác. Thông tin về đầu ra được đo bởi phân phối xác suất (probability distribution) \(p(x)\) của biến ngẫu nhiên.
Một biến ngẫu nhiên có thể là rời rạc (discrete) hoặc liên tục (continuous). Một biến ngẫu nhiên rời rạc sẽ lấy giá trị trong một tập hợp cho trước. Ví dụ tung đồng xu thì có hai khả năng là head và tail (tên gọi này bắt nguồn từ đồng xu Mỹ, một mặt có hình mặt người, được gọi là head, trái ngược với mặt này được gọi là mặt tail, cách gọi này hay hơn cách gọi xấp ngửa vì ta không có quy định rõ ràng thế nào là xấp ngay ngửa).Tập các giá trị này có thể là có thứ tự (khi tung xúc xắc) hoặc không có thứ tự (unorderd), ví dụ khi đầu ra là các giá trị nắng, mưa, bão, etc. Mỗi đầu ra có một giá trị xác suất tương ứng với nó. Các giá trị xác suất này không âm và có tổng bằng một:
\[ \text{if}~ x ~\text{is discrete:}\quad \sum_{x} p(x) = 1 ~~~~ (1) \]
Biến ngẫu nhiên liên tục lấy các giá trị là tập con của các số thực. Những giá trị này có thể là hữu hạn, ví dụ thời gian làm bài của mỗi thí sinh trong một bài thi 180 phút, hoặc vô hạn, ví dụ thời gian để chiếc xe bus tiếp theo tới. Không như biến ngẫu nhiên rời rạc, xác suất để đầu ra bằng chính xác một giá trị nào đó, theo lý thuyết, là bằng 0. Thay vào đó, ta có thể hình dung xác suất để đầu ra nằm trong một khoảng giá trị nào đó; và việc này được mô tả bởi hàm mật đô xác suất (probability density function - pdf). Hàm mật độ xác suất luôn cho giá trị dương, và tích phân của nó trên toàn miền possible outcome phải bằng 1.
\[ \text{if}~ x ~\text{is continuous:}\quad \int p(x)dx = 1 ~~~~ (2) \] Để giảm thiểu ký hiệu, hàm mật độ xác suất của một biến ngẫu nhiên liên tục \(x\) cũng được ký hiệu là \(p(x)\).
Chú ý: Nếu \(x\) là biến ngẫu nhiên rời rạc, \(p(x)\) luôn luôn nhỏ hơn hoặc bằng 1. Trong khi đó, nếu \(x\) là biến ngẫu nhiên liên tục, \(p(x)\) có thể nhận giá trị dương bất kỳ, điều này vẫn đảm bảo là tích phân của hàm mật độ xác suất theo toàn bộ giá trị có thể có của \(x\) bằng 1. Với biến ngẫu nhiên rời rạc, \(p(x)\) được hiểu là mật độ xác suất tại \(x\).
2.2. Joint probability
Xét hai biến ngẫu nhiên \(x\) và \(y\). Nếu ta quan sát rất nhiều cặp đầu ra của \(x\) và \(y\), thì có những tổ hợp hai đầu ra xảy ra thường xuyên hơn những tổ hợp khác. Thông tin này được biểu diễn bằng một phân phối được gọi là joint probability của \(x\) và \(y\), và được viết là \(p(x, y)\). Dấu phẩy trong \(p(x, y)\) có thể đọc là và, vậy \(p(x, y)\) là xác suất của \(x\) và \(y\). \(x\) và \(y\) có thể là hai biến ngẫu nhiên rời rạc, liên tục, hoặc một rời rạc, một liên tục. Luôn nhớ rằng tổng các xác suất trên mọi cặp giá trị có thể xảy ra \((x, y)\) bằng 1.
\[ \begin{eqnarray} \text{both are discrete} \quad \quad & \sum_{x, y} p(x, y) &=& 1 \newline \text{both are continuous} & \int p(x, y) dx dy &=& 1\newline x ~\text{is discrete}, ~ y ~\text{is continuous} & \sum_{x} \int p(x, y) dy = \int \left(\sum_{x} p(x, y) \right)dy &=& 1 \end{eqnarray} \]
Xét ví dụ trong Hình 1, phần có nền màu lục nhạt. \(x\) là biến ngẫu nhiên chỉ điểm thi môn Toán của học sinh trong một trường trong kỳ thi Quốc gia, \(y\) là biến ngẫu nhiên chỉ điểm thi môn Vật Lý cũng trong kỳ thi đó. \(p(x = x^*, y = y^*)\) là tỉ lệ giữa tần suất số học sinh được \(x^*\) điểm trong môn Toán và \(y^*\) điểm trong môn Vật Lý và toàn bộ số học sinh. Tỉ lệ này có thể coi là xác suất khi số học sinh trong trường là lớn. Ở đây \(x^*\) và \(y^*\) là các số xác định. Thông thường, xác suất này được viết gọn lại thành \(p(x^*, y^*)\), và \(p(x, y)\) được dùng như một hàm tổng quát để mô tả các xác suất. Giả sử thêm rằng điểm các môn là các số tự nhiên từ 1 đến 10.
Các ô vuông màu lam thể hiện xác suất \(p(x, y)\) với diện tích ô vuông càng to thể hiện xác suất đó càng lớn. Chú ý rằng tổng các xác suất này bằng 1.
Các bạn có thể thấy rằng xác suất để một học sinh được 10 điểm một Toán và 1 điểm môn Lý rất thấp, điều tương tự xảy ra với 10 điểm môn Lý và 1 điểm môn Toán. Ngược lại, xác suất để một học sinh được khoảng 7 điểm cả hai môn là cao nhất.
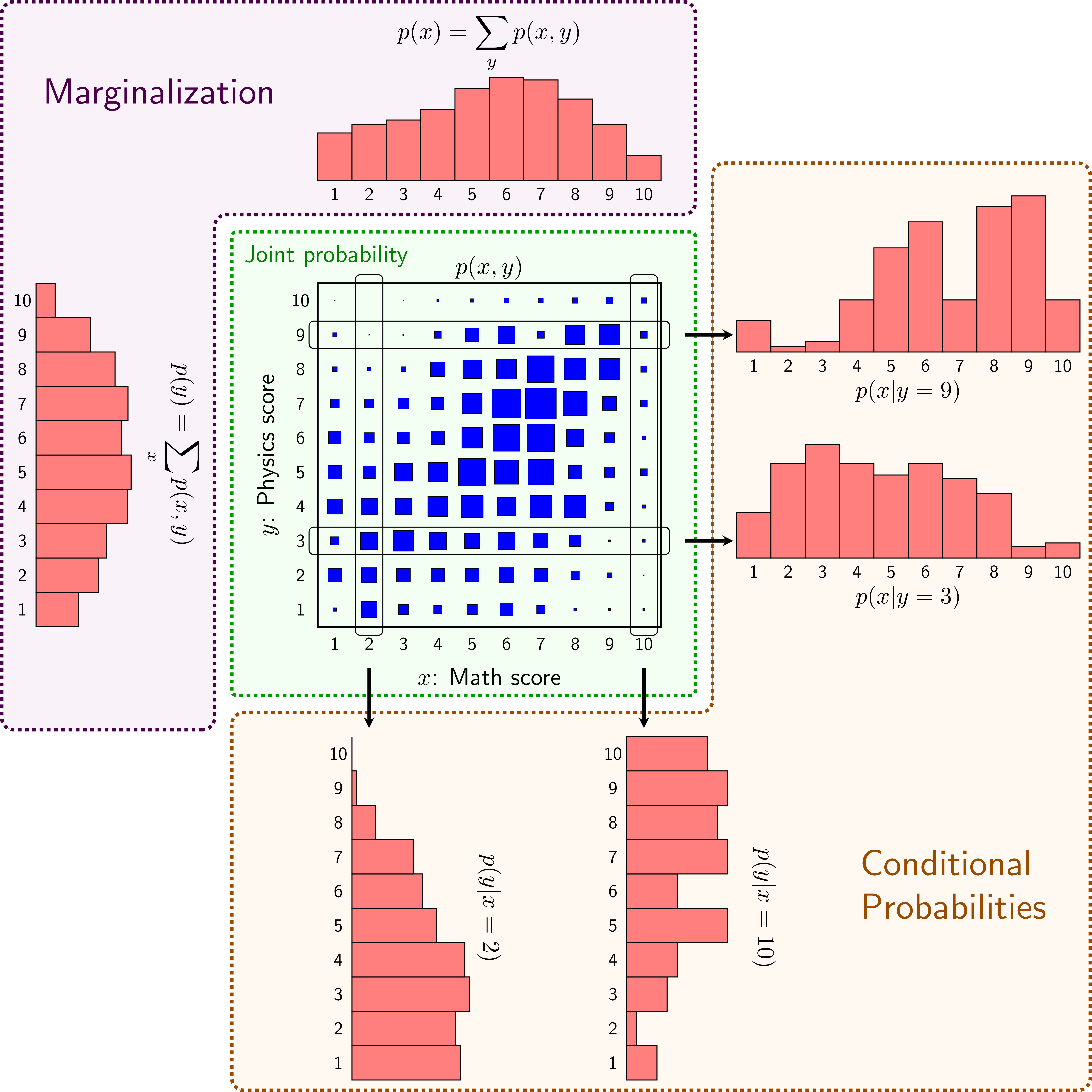
Thông thường, chúng ta sẽ làm việc với các bài toán ở đó joint probability xác định trên nhiều hơn 2 biến ngẫu nhiên. Chẳng hạn, \(p(x, y, z)\) thể hiện joint probability của 3 biến ngẫu nhiên \(x,y\) và \(z\). Khi có nhiều biến ngẫu nhiên, ta có thể viết chúng dưới dạng vector. Ta có thể viết \(p(\mathbf{x})\) để thể hiện joint probability của biến ngẫu nhiên nhiều chiều \(\mathbf{x} = [x_1, x_2, \dots, x_n]^T\). Khi có nhiều tập các biến ngẫu nhiên, ví dụ \(\mathbf{x}\) và \(\mathbf{y}\), ta có thể biết \(p(\mathbf{x}, \mathbf{y})\) để thể hiện joint probability của tất cả các thành phần trong hai biến ngẫu nhiên nhiều chiều này.
2.3. Marginalization
Nếu biết joint probability của nhiều biến ngẫu nhiên, ta cũng có thể xác định được phân bố xác suất của từng biến bằng cách lấy tổng (với biến ngẫu nhiên rời rạc) hoặc tích phân (với biến ngẫu nhiên liên tục) theo tất cả các biến còn lại:
\[ \begin{eqnarray} p(x) &=& \sum_{y}p(x, y) \quad & (3) \newline p(y) &=& \sum_{x}p(x, y) & (4) \end{eqnarray} \] Và với biến liên tục: \[ \begin{eqnarray} p(x) &=& \int p(x, y)dy \quad & (5)\newline p(y) &=& \int p(x, y)dx & (6) \end{eqnarray} \]
Với nhiều biến hơn, chẳng hạn 4 biến rời rạc \(x, y, z, w\): \[ \begin{eqnarray} p(x) &=& \sum_{ y, z, w}p(x, y, z, w) \quad & (7) \newline p(x, y) &=& \sum_{z, w}p(x, y, z, w) & (8) \end{eqnarray} \] Cách xác định xác suất của một biến dựa trên joint probability được gọi là marginalization. Và phân phối đó được gọi là marginal probability.
Từ đây trở đi, nếu không nói gì thêm, tôi sẽ dùng ký hiệu \(\sum\) để chỉ chung cho cả hai loại biến. Nếu biến ngẫu nhiên là liên tục, bạn đọc ngầm hiểu rằng dấu \(\sum\) cần được thay bằng dấu tích phân \(\int\), biến lấy vi phân chính là biến được viết dưới dấu \(\sum\). Chẳng hạn, trong \((8)\), nếu \(z\) là liên tục, \(w\) là rời rạc, công thức đúng sẽ là:
\[ p(x, y) = \sum_{w}\left( \int p(x, y, z, w)dz \right) = \int \left( \sum_{w} p(x, y, z, w)\right) dz \]
Quay lại ví dụ trong Hình 1 với hai biến ngẫu nhiên rời rạc \(x, y\). Lúc này, \(p(x)\) được hiểu là xác suất để một học sinh đạt được \(x\) điểm môn toán. Xác suất này được thể hiện ở khu vực có nền màu tím nhạt, phía trên. Có hai cách tính xác suất này, nhắc lại rằng xác suất ở đây thực ra là tỉ lệ giữa số học sinh đạt \(x\) điểm môn toán và toàn bộ số học sinh. Cách thứ nhất, dựa trên cách vừa định nghĩa, là đếm số học sinh được \(x\) điểm môn toán và tổng số học sinh. Cách tính thứ hai là dựa trên Joint probability đã biết về xác suất để một học sinh được \(x\) điểm môn Toán và \(y\) điểm môn Lý. Số lượng học sinh đạt \(x = x^*\) điểm môn Toán sẽ bằng tổng số lượng học sinh đạt \(x = x^*\) điểm môn Toán và \(y\) điểm môn Lý, với \(y\) là một giá trị bất kỳ từ 1 đến 10. Vậy nên để tính xác suất \(p(x)\), ta chỉ cần tính tổng của toàn bộ \(p(x, y)\) với \(y\) chạy từ 1 đến 10. Điều tương tự xảy ra nếu ta muốn tính \(p(y)\) (xem phần bên trái của khu vực nền tím nhạt).
Dựa trên nhận xét này, mỗi giá trị của \(p(x)\) chính bằng tổng các giá trị trong cột thứ \(x\) của Hình vuông trung tâm. Mỗi giá trị của \(p(y)\) sẽ bằng tổng các giá trị trong hàng thứ \(y\) tính từ đưới lên của Hình vuông trung tâm. Chú ý rằng tổng các xác suất luôn bằng 1. Từ hình ta cũng có thể thấy điểm môn Lý tuân theo phân phối chuẩn, đề khá tốt; còn đề thi môn Toán có vẻ hơi dễ vì phổ điểm bị lệch sang phải. Số liệu này chỉ là ví dụ nên các bạn có thể thấy một vài điểm bất thường.
2.4. Conditional probability
Xác suất có điều kiện.
Dựa vào phổ điểm của các học sinh, liệu ta có thể tính được xác suất để một học sinh được điểm 10 môn Lý, biết rằng học sinh đó được điểm 1 môn Toán (ai cũng có quyền hy vọng). Hoặc biết rằng bây giờ đang là tháng 7, tính xác suất để nhiệt độ hôm nay cao hơn 30 độ C.
Xác suất có điều kiện (conditional probability) của một biến ngẫu nhiên \(x\) biết rằng biến ngẫu nhiên \(y\) có giá trị \(y^*\) được ký hiệu là \(p(x| y = y^*)\) (đọc là probability of \(x\) given that \(y\) takes value \(y^*\)).
Conditional probability \(p(x | y = y^*)\) có thể được tính dựa trên joint probobability \(p(x, y)\). Quay lại Hình 1 với vùng có nền màu nâu nhạt. Nếu biết rằng \(y = 9\), xác suất \(p(x | y = 9)\) có thể tính được dựa trên hàng thứ 9 của hình vuông trung tâm, tức hàng \(p(x, y = 9)\). Trong hàng này, những ô vuông lớn hơn thể hiện xác suất lớn hơn. Tương ứng như thế, \(p(x | y = 9) \) cũng lớn nếu \(p(x, y= 9)\) lớn. Chú ý rằng tổng các xác suất \(\sum_{x} p(x, y = 9)\) nhỏ hơn 1 và bằng tổng các xác suất trên hàng thứ 9 này. Để có đúng xác suất, tức tổng các xác suất có điều kiện bằng 1, ta cần chia mỗi đại lượng \(p(x, y = 9)\) cho tổng của toàn hàng này. Tức là:
\[ \displaystyle p(x | y = 9) = \frac{p(x, y = 9)}{\sum_x p(x, y = 9)} = \frac{p(x, y = 9)}{p(y = 9)} \] Tổng quát: \[ \displaystyle p(x|y = y^*) = \frac{p(x, y = y^*)}{\sum_{x} p(x, y = y^*)} = \frac{p(x, y = y^*)}{p(y = y^*)} ~~~~ (9) \] ở đây ta đã sử dụng công thức marginal probability ở \((4)\) cho mẫu số. Thông thường, ta có thể viết xác suất có điều kiện mà không cần chỉ rõ giá trị \(y = y^*\) và có công thức gọn hơn: \[ p(x |y) = \frac{p(x, y)}{p(y)}~~~ (10) \] Tương tự: \[ p(y | x) = \frac{p(y, x)}{p(x)} \]
và ta sẽ có quan hệ: \[ p(x, y) = p(x|y)p(y) = p(y | x) p(x) ~~~ (11) \]
Khi có nhiều hơn hai biến ngẫu nhiên, ta có các công thức: \[ \begin{eqnarray} p(x, y, z, w) & = & p(x, y, z | w) p(w) & (12)\newline & = & p(x, y | z, w)p(z, w) = p(x, y | z, w) p(z | w) p(w) \quad & (13) \newline & = & p(x | y, z, w)p(y | z, w) p(z | w) p(w) & (14) \end{eqnarray} \]
Công thức \((14)\) có dạng chuỗi (chain) và được sử dụng nhiều sau này.
2.5. Quy tắc Bayes
Công thức \((11)\) biểu diễn joint probability theo hai cách. Từ đây ta có thể suy ra quan hệ giữa hai conditional probabilities \(p(x |y)\) và \(p(y | x)\): \[ p(y |x) p(x) = p(x | y) p(y) \] Biến đối một chút: \[ \displaystyle \begin{eqnarray} p(y | x) & = & \frac{p(x |y) p(y)}{p(x)} & (15)\newline & = & \frac{p(x |y) p(y)}{\sum_{y} p(x, y)} & (16)\newline & = & \frac{p(x |y) p(y)}{\sum_{y} p(x | y) p(y)} \quad & (17) \end{eqnarray} \] ở đây, mẫu số của \((16)\) và \((17)\) đã lần lượt sử dụng các công thức về marginal \((3)\) và conditional probability \((11)\). Từ \((17)\) ta có thể thấy rằng \(p(y | x)\) hoàn toàn có thể tính được nếu ta biết mọi \(p(x | y)\) và \(p(y)\). Tuy nhiên, việc tính trực tiếp xác suất này thường là phức tạp. Thay vào đó, ta có thể đi tìm mô hình phù hợp của \(p(\mathbf{x} | y)\) trên training data sao cho những gì đã thực sự xảy ra có xác suất cao nhất có thể (Chỗ này có thể hơi khó hình dung, tôi sẽ nói cụ thể về việc này trong bài tiếp theo). Dựa trên training data, các tham số của mô hình này có thể tìm được qua một bài toán tối ưu.
Ba công thức \((15) - (17)\) thường được gọi là Quy tắc Bayes (Bayes’ rule). Quy tắc này rất quan trọng trong Machine Learning!
Trong Machine Learning, chúng ta thường mô tả quan hệ giữa hai biến \(x\) và \(y\) dưới dạng xác suất có điều kiện \(p(x|y)\). Ví dụ, biết rằng đầu vào là một bức ảnh ở dạng vector \(\mathbf{x}\), xác suất để bức ảnh chứa một chiếc xe là bao nhiêu. Khi đó, ta phải tính \(p(y | \mathbf{x})\).
2.6. Independence
Nếu biết giá trị của một biến ngẫu nhiên \(x\) không mang lại thông tin về việc suy ra giá trị của biến ngẫu nhiên \(y\) (và ngược lại), thì ta nói rằng hai biến ngẫu nhiên là độc lập (independence). Chẳng hạn, chiều cao của một học sinh và điểm thi môn Toán của học sinh đó có thể coi là hai biến ngẫu nhiên độc lập.
Khi hai biến ngẫu nhiên \(x\) và \(y\) là độc lập, ta sẽ có: \[ \begin{eqnarray} p(x | y) &=& p(x) \quad & (18) \newline p(y | x) &=& p(y) & (19) \end{eqnarray} \]
Thay vào biểu thức Conditional Probability trong \((11)\), ta có: \[ p(x, y) = p(x | y) p(y) = p(x) p(y) ~~~ (20) \]
2.7. Kỳ vọng
Kỳ vọng (expectation) của một biến ngẫu nhiên được định nghĩa là: \[ \begin{eqnarray} \text{E}[x] = \sum_x x p(x) \quad & \text{if}~ x ~ \text{is discrete} \quad & (21)\newline \text{E}[x] = \int x p(x) dx \quad & \text{if}~ x ~ \text{is continuous} & (22) \end{eqnarray} \]
Giả sử \(f(.)\) là một hàm số trả về một giá trị với mỗi giá trị \(x^*\) của biến ngẫu nhiên \(x\). Khi đó, nếu \(x\) là biến ngẫu nhiên rời rạc, ta sẽ có: \[ \text{E}[f(x)] = \sum_x f(x) p(x) ~~~ (23) \]
Công thức cho biến ngẫu nhiên liên tục cũng được viết tương tự.
Với joint probability: \[ \text{E}[f(x, y)] = \sum_{x,y} f(x, y) p(x, y) dx dy ~~~ (24) \]
Có 3 quy tắc cần nhớ về kỳ vọng:
-
Kỳ vọng của một hằng số theo một biến ngẫu nhiên \(x\) bất kỳ bằng chính hằng số đó: \[ \text{E}[\alpha] = \alpha ~~~ (25) \]
-
Kỳ vọng có tính chất tuyến tính: \[ \begin{eqnarray} \text{E}[\alpha x] & = & \alpha \text{E}[x] \quad & (26)\newline \text{E}[f(x) + g(x)] & = & \text{E}[f(x)] + \text{E}[g(x)] & (27) \end{eqnarray} \]
-
Kỳ vọng của tích hai biến ngẫu nhiên bằng tích kỳ vọng của hai biến đó nếu hai biến ngẫu nhiên đó là độc lập. Điều ngược lại không đúng, tôi sẽ bàn nếu có dịp:
\[ \text{E}[f(x) g(y)] = \text{E}[f(x)] \text{E}[g(y)] ~~~ (28) \]
3. Một vài phân phối thường gặp
3.1. Bernoulli distribution
Bernoulli distribution là một phân bố rời rạc mô tả biến ngẫu nhiên nhị phân: nó mô tả trường hợp khi đầu ra chỉ nhận một trong hai giá trị \(x \in \{0, 1\}\). Hai giá trị này có thể là head và tail khi tung đồng xu; có thể là fraud transaction và normal transaction trong bài toán xác định giao dịch lừa đảo trong tín dụng; có thể là người và không phải người trong bài toán tìm xem trong một bức ảnh có người hay không.
Bernoulli distribution được mô tả bằng một tham số \(\lambda \in [0, 1]\) và là xác suất để \(x = 1\). Phân bố của mỗi đầu ra sẽ là: \[ p(x = 1) = \lambda, ~~~~ p(x = 0) = 1 - p(x = 1) = 1 - \lambda ~~~ (29) \]
Hai đẳng thức này thường được viết gọn lại: \[ p(x) = \lambda^x (1 - \lambda)^{1 - x} ~~~~ (29) \]
với giả định rằng \(0 ^0 = 1\).
Có thể bạn chưa quen với cách viết này, hồi đầu tôi cũng hơi ngạc nhiên. Nhưng bạn cứ thử thay \(x\) bằng 0 và 1 vào là sẽ hiểu.
Bernoulli distribution được ký hiệu ngắn gọn dưới dạng: \[ p(x) = \text{Bern}_x [\lambda] ~~~~~ (30) \]
3.2. Categorical distribution
Cũng là biến ngẫu nhiên rời rạc, nhưng trong hầu hết các trường hợp, đầu ra có thể là một trong nhiều hơn hai giá trị khác nhau. Ví dụ, một bức ảnh có thể chứa một chiếc xe, một người, hoặc một con mèo. Khi đó, ta dùng phân bố tổng quát của Bernoulli distribution và được gọi là Categorical distribution. Các đầu ra được mô tả bởi 1 phần tử trong tập \(\{1, 2, \dots, K\}\).
Nếu có \(K\) đầu ra có thể đạt được, Categorical distribution sẽ được mô tả bởi \(K\) tham số, viết dưới dạng vector: \(\lambda = [\lambda_1, \lambda_2, \dots, \lambda_K]\) với các \(\lambda_k\) không âm và có tổng bằng 1. Mỗi giá trị \(\lambda_k\) thể hiện xác suất để đầu ra nhận giá trị \(k\): \[ p(x = k) = \lambda_k \] Viết gọn lại: \[ p(x) = \text{Cat}_x [\lambda] \]
Biểu diễn theo cách khác, ta có thể coi như đầu ra là một vector ở dạng one-hot vector, tức \(\mathbf{x} \in \{\mathbf{e}_1, \mathbf{e}_2, \dots, \mathbf{e}_K\}\) với \(\mathbf{e}_k\) là vector đơn vị thứ \(k\), tức tất cả các phần tử bằng 0, trừ phần tử thứ \(k\) bằng 1. Khi đó, ta sẽ có: \[ p(\mathbf{x} = \mathbf{e}_k) = \prod_{j=1}^K \lambda_j^{x_j} = \lambda_k ~~~~ (31) \] Cách viết này được sử dụng rất nhiều trong Machine Learning.
3.3. Univariate normal distribution (Phân phối chuẩn một biến)
Phân phối chuẩn 1 biến (univariate normal hoặc Gaussian distribution) được định nghĩa trên các biến liên tục nhận giá trị \(x \in (-\infty, \infty)\).
Phân phối này được mô tả bởi hai tham số: mean \(\mu\) và variance \(\sigma^2\). Giá trị \(\mu\) có thể là bất kỳ số thực nào, thể hiện vị trí của peak, tức tại đó mà hàm mật độ xác suất đạt giá trị cao nhất. Giá trị \(\sigma^2\) là một giá trị dương, với \(\sigma\) thể hiện độ rộng của phân bố này. \(\sigma\) lớn chứng tỏ khoảng giá trị đầu ra biến đổi mạnh, và ngược lại.
Hàm mật độ xác suất của phân phối này được định nghĩa là: \[ p(x) = \frac{1}{\sqrt{2\pi \sigma^2}}\exp \left( -\frac{(x - \mu)^2}{2\sigma^2}\right)~~~~ (32) \] Dạng gọn hơn: \[ p(x) = \text{Norm}_x [\mu, \sigma^2] \]
Ví dụ về đồ thị hàm mật độ xác suất của univariate normal distribution được cho trên Hình 2a).

a) |

b) |
3.4. Multivariate normal distribution
Đây là trường hợp tổng quát của normal distribution khi biến là nhiều chiều, giả sử là \(D\) chiều. Có hai tham số mô tả phân phối này: mean vector \(\mu \in \mathbb{R}^D\) và covariance matrix \(\Sigma \in \mathbb{S}_{++}^D \) là một ma trận đối xứng xác định dương.
Hàm mật độ xác suất có dạng: \[ p(\mathbf{x}) = \frac{1}{(2\pi)^{D/2} |\Sigma|^{1/2}} \exp \left(\frac{1}{2} (\mathbf{x} - \mu)^T \Sigma^{-1} (\mathbf{x} - \mu)\right) ~~~ (33) \] với \(|\Sigma|\) là định thức của ma trận hiệp phương sai \(\Sigma\).
Hoặc viết gọn: \[ p(\mathbf{x}) = \text{Norm}_{\mathbf{x}}[\mu, \Sigma] \]
Ví dụ về hàm mật độ xác suất của một bivariate normal distribution (2 biến) được cho trên Hình 2b). Các level-sets của mặt này đều là các hình Ellipse đồng tâm.
3.5. Beta distribution
Beta distribution là một phân phối liên tục được định nghĩa trên một biến ngẫu nhiên \(\lambda \in [0, 1]\). Phân phối này phù hợp với miệc mô tả sự biến động (uncertainty) của tham số \(\lambda\) trong Bernoulli distribution. Nhắc lại, Beta distribution được dùng để mô tả tham số cho một distribution khác. Các bạn sẽ thấy rõ hơn trong một ví dụ ở bài tiếp theo.
Beta distribution được mô tả bởi hai tham số dương \(\alpha, \beta \in (0, \infty)\). Hàm mật độ xác suất của nó là: \[ p(\lambda) = \frac{\Gamma(\alpha + \beta)}{\Gamma(\alpha) \Gamma(\beta)} \lambda^{\alpha - 1} ( 1 - \lambda) ^{\beta - 1} ~~~ (34) \]
với \(\Gamma(.)\) là gamma function: \[ \Gamma(z) = \int_0^{\infty} t^{z-1}\exp(-t) dt \] và có liên quan tới giai thừa khi \(z\) là số tự nhiên: \[ \Gamma[z] = (z-1)! \]
Tôi giới thiệu gamma function để bạn đọc tham khảo. Trên thực tế, việc tính giá trị của gamma function không thực sự quan trọng vì nó chỉ mang tính chuẩn hoá để tổng xác suất bằng 1.
Dạng gọn của Beta distribution: \[ p(\lambda) = \text{Beta}_{\lambda}[\alpha, \beta] \]
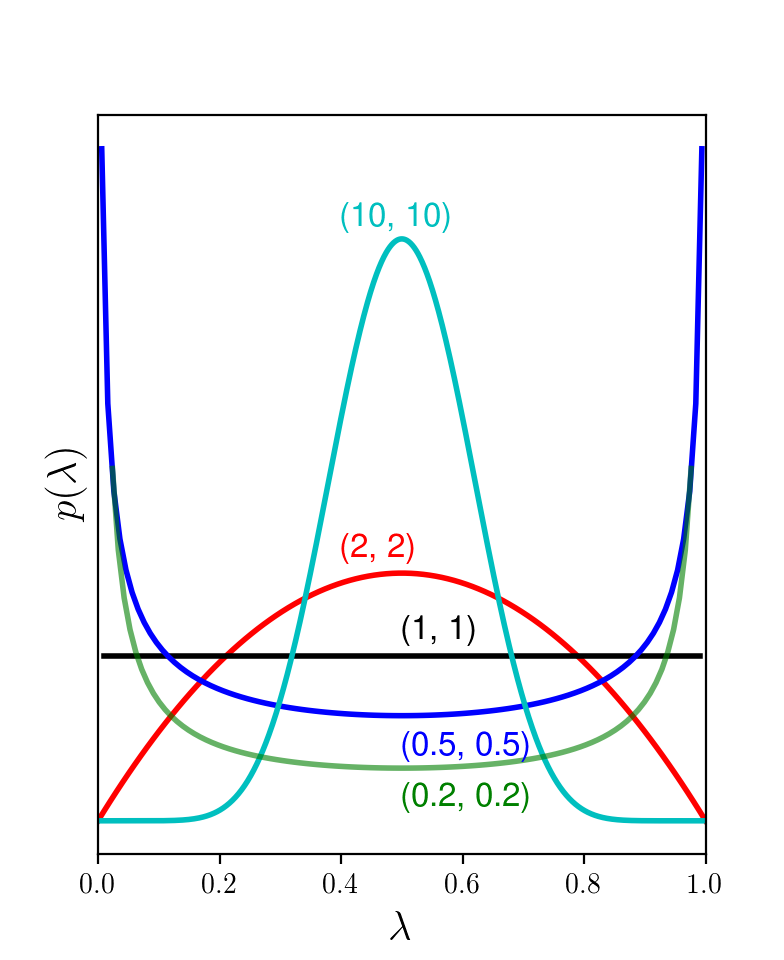
Hình 3 minh hoạ các hàm mật độ xác suất của Beta distribution với các cặp giá trị \((\alpha, \beta)\) khác nhau.
a) |

b) |

c) |
-
Trong Hình 3a), \(\alpha =\beta\). Đồ thị là đối xứng qua đường thẳng \(\lambda = 0.5\). Khi \(\alpha = \beta = 1\), thay vào \((34)\) ta thấy \(p(\lambda) = 1\) với mọi \(\lambda\). Trong trường hợp này, Beta distribution trở thành uniform distribution (phân phối đều). Khi \(\alpha = \beta > 1\), các hàm số đạt giá trị cao tại gần trung tâm, tức là khả năng cao là \(\lambda\) sẽ nhận giá trị xung quanh điểm 0.5. Khi \(\alpha = \beta < 1\), hàm số đạt giá trị cao tại các điểm gần 0 và 1. Điều này chứng tỏ Bernoulli distribution tương ứng với các \(\lambda\) này bị thiên lệch nhiều.
-
Trong hình 3b), khi \(\alpha < \beta\), ta thấy rằng đồ thị có xu hướng lệch trái. Các giá trị \((\alpha, \beta)\) này nên được sử dụng nếu ta dự đoán rằng \(\lambda\) là một số nhỏ hơn \(0.5\).
-
Trong Hình 3c), khi \(\alpha > \beta\), điều ngược lại xảy ra.
3.6. Dirichlet distribution
Dirichlet distribution chính là trưởng hợp tổng quát của Beta distribution khi được dùng để mô tả tham số của Categorical distribution (nhắc lại rằng Categorical distribution là trường hợp tổng quát của Bernoulli distribution).
Dirichlet distribution được định nghĩa trên \(K\) biến liên tục \(\lambda_1, \dots, \lambda_K\) trong đó các \(\lambda_k\) không âm và có tổng bằng 1. Bởi vậy, nó phù hợp để mô tả tham số của Categorical distribution.
Có \(K\) tham số dương để mô tả một Dirichlet distribution: \(\alpha_1, \dots, \alpha_K\).
Hàm mật độ xác suất: \[ p(\lambda_1, \dots, \lambda_K) = \frac{\Gamma(\sum_{k=1}^K \alpha_k)}{\prod_{k=1}^K\Gamma(\alpha_k)} \prod_{k=1}^K \lambda_k^{\alpha_k - 1}~~~ (35) \]
Viết gọn: \[ p(\lambda_1, \dots, \lambda_K) = \text{Dir}_{\lambda_1, \dots, \lambda_K}[\alpha_1, \dots, \alpha_K] \]
4. Thảo luận
Về Xác suất thống kê, còn rất nhiều điều chúng ta cần lưu ý. Tạm thời, tôi ôn tập lại những kiến thức này để phục vụ cho một số bài viết tiếp theo. Khi nào có phần nào cần nhắc lại, tôi sẽ ôn tập thêm cho các bạn.
5. Tài liệu tham khảo
[1] Chapter 2, 3 của Computer Vision: Models, Learning, and Inference - Simon J.D. Prince