
Trong trang này:
- 1. Giới thiệu
- 2. Maximum Likelihood Estimation
- 3. Maximum a Posteriori
- 4. Tóm tắt
- 5. Tài liệu tham khảo
1. Giới thiệu
Những sự kiện có xác suất cao là những sự kiện có khả năng xảy ra hơn.
Câu nói nói cũng như không này là khơi nguồn cho rất nhiều các thuật toán Machine Learning có liên quan đến xác suất.
Cách giải quyết bài toán Machine Learning có thể viết gọn lại thành 3 bước chính: Modeling, Learning và Inference. (Xem Computer Vision: Models, Learning, and Inference)
Modeling là việc đi tìm môt mô hình thích hợp cho bài toán cần giải quyết. Với bài toán Linear Regression, modeling chính là việc mô hình dữ liệu đầu ra (output) như là tổ hợp tuyến tính của dữ liệu đầu vào (input). Với bài toán k-means clustering, modeling chính là việc quan sát ra rằng các clusters thường được mô tả bởi các centroids (hoặc centers) và mỗi điểm được xếp vào cluster tương ứng với centroid gần nó nhất. Trong bài toán Support Vector Machine cho dữ liệu linearly separable, modeling chính là bước quan sát thấy rằng đường thẳng phân chia hai classes phải là đường làm cho margin đạt giá trị lớn nhất. Việc đi tìm ra mô hình nào phù hợp cho bài toán chính là bước Modeling.
Learning là bước tiến hành tối ưu các tham số của mô hình. Mỗi model được mô hình bởi một bộ các tham số (parameters). Với Linear Regression, tham số mô hình là bộ vector hệ số và bias \((\mathbf{w}, b)\). Với K-means clustering, tham số mô hình có thể được coi là các clusters. Với Support Vector Machine, tham số mô hình có thể là vector hệ số và bias mô tả đường thằng \((\mathbf{w}, b)\). Việc đi tìm các tham số cho mô hình thường được thực hiện bằng việc giải một bài toán tối ưu. Quá trình giải bài toán tối ưu, hay chính là quá trình đi tìm tham số của mô hình, chính là quá trình Learning. Sau bước Learning này, chúng ta thu được các trained parameters.
Inference là bước dự đoán ouput của mô hình dựa trên các trained parameters. Với Linear Regression, Inference chính là việc tính \(y = \mathbf{w}^T\mathbf{x} + b\) dựa trên bộ các tham số đã được huấn luyện \((\mathbf{w}, b)\). Với K-means clustering, việc Inference chính là việc đi tìm centroid gần nhất. Với Support Vector Machine, Inference chính là việc xác định class của một dữ liệu mới dựa vào công thức \(y = \text{sgn}(\mathbf{w}^T\mathbf{x} + b)\). So với hai bước Modeling và Learning, Inference thường đơn giản hơn.
Như đã đề cập, ở nửa sau của blog, tôi sẽ giới thiệu rất nhiều các mô hình thống kê. Trong các mô hình này, việc Modeling là việc đi tìm một mô hình thống kê (statistical model) phù hợp với từng loại dữ liệu và bài toán. Việc Learning là việc đi tìm các tham số cho mô hình thống kê đó. Việc Inference có thể coi là việc tính xác suất để xảy ra mỗi giá trị ở đầu ra khi biết các giá trị ở đầu vào và model được mô tả bởi các trained parameters.
Các Mô Hình Thống Kê (Statistical Models) thường là sự kết hợp của các phân phối xác suất đơn giản. Với Bernoulli distribution, tham số là biến \(\lambda\). Với Multivariate Normal Distribution, tham số là mean vector \(\mu\) và ma trận hiệp phương sai \(\Sigma\). Với một mô hình thông kê bất kỳ, ký hiệu \(\theta\) là tập hợp tất cả các tham số của mô hình đó. Learning chính là quá trình đánh giá (estimate) bộ tham số \(\theta\) sao cho dữ liệu sẵn có và mô hình khớp với nhau nhất. Quá trình đó còn được gọi là parameter estimation.
Có hai cách đánh giá tham số thường được dùng trong Statistical Machine Learning. Cách thứ nhất chỉ dựa trên dữ liệu đã biết trong tập traing (training data), được gọi là Maximum Likelihood Estimation hay ML Estimation hoặc MLE. Cách thứ hai không những dựa trên training data mà còn dựa trên những thông tin đã biết của các tham số. Những thông tin này có thể có được bằng cảm quan của người xây dựng mô hình. Cảm quan càng rõ ràng, càng hợp lý thì khả năng thu được bộ tham số tốt là càng cao. Chẳng hạn, thông tin biết trước của \(\lambda\) trong Bernoulli distribution là việc nó là một số trong đoạn \([0, 1]\). Với bài toán tung đồng xu, với \(\lambda\) là xác suất có được mặt head, ta dự đoán được rằng giá trị này nên là một số gần với \(0.5\). Cách đánh giá tham số thứ hai này được gọi là Maximum A Posteriori Estimation hay MAP Estimation.
Trong bài viết này, tôi sẽ trình bày về ý tưởng và cách giải quyết bài toán đánh giá tham số mô hình theo MLE hoặc MAP Estimation. Và như thường lệ, chúng ta sẽ cùng thực hiện mộ vài ví dụ đơn giản.
2. Maximum Likelihood Estimation
2.1. Ý tưởng
Giả sử có các điểm dữ liệu \(\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_N\). Giả sử thêm rằng ta đã biết các điểm dữ liệu này tuân theo một phân phối nào đó được mô tả bởi bộ tham số \(\theta\).
Maximum Likelihood Estimation là việc đi tìm bộ tham số \(\theta\) sao cho xác suất sau đây đạt giá trị lớn nhất:
\[ \theta = \max_{\theta} p(\mathbf{x}_1, \dots, \mathbf{x}_N | \theta) ~~~~ (1) \]
Biểu thức \((1)\) có ý nghĩa như thế nào và vì sao việc này có lý?
Giả sử rằng ta đã biết mô hình rồi, và mô hình này được mô tả bởi bộ tham số \(\theta\). Thế thì, \(p(\mathbf{x}_1 | \theta)\) chính là xác suất xảy ra sự kiện \(\mathbf{x}_1\) biết rằng mô hình là (được mô tả bởi) \(\theta\) (đây là một conditional probability). Và \(p(\mathbf{x}_1, \dots, \mathbf{x}_N | \theta)\) chính là xác suất để toàn bộ các sự kiện \(\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_N\) xảy ra đồng thời (nó là một joint probability), xác suất đồng thời này còn được gọi là likelihood. Ở đây, likelihood chính là hàm mục tiêu.
Bởi vì sự đã rồi, tức dữ liệu training bản thân nó đã là như thế rồi, xác suất đồng thời này cần phải càng cao càng tốt. Việc này cũng giống như việc đã biết kết quả, và ta cần đi tìm nguyên nhân sao cho xác suất xảy ra kết quả này càng cao càng tốt.
Maximum Likelihood chính là việc đi tìm bộ tham số \(\theta\) sao cho Likelihood là lớn nhất.
2.2. Independence Assumption và log-likelihood
Việc giải trực tiếp bài toán \((1)\) thường là phức tạp vì việc đi tìm mô hình xác suất đồng thời cho toàn bộ dữ liệu là ít khi khả thi. Một cách tiếp cận phổ biến là giả sử đơn giản rằng các điểm dữ liệu \(\mathbf{x}_n\) là độc lập với nhau, nếu biết tham số mô hình \(\theta\) (độc lập có điều kiện). Nói cách khác, ta xấp xỉ likelihood trong \((1)\) bởi: \[ p(\mathbf{x}_1, \dots, \mathbf{x}_N | \theta) \approx \prod_{n = 1}^N p(\mathbf{x}_n |\theta) ~~~~ (2) \]
(Nhắc lại rằng hai sự kiện \(x, y\) là độc lập nếu xác suất đồng thời của chúng bằng tích xác suất của từng sự kiện: \(p(x, y) = p(x)p(y)\). Và khi là xác suất có điều kiện: \(p(x, y | z) = p(x|z)p(y|z)\))
Lúc đó, bài toán \((1)\) có thể được giải quyết bằng cách giải bài toán tối ưu sau:
\[ \theta = \max_{\theta} \prod_{n=1}^N p(\mathbf{x}_n| \theta) ~~~~ (3) \]
Việc tối ưu hoá một tích thường phức tạp hơn việc tối ưu một tổng, vì vậy việc tối đa hàm mục tiêu thường được chuyển về việc tối đa \(\log\) của hàm mục tiêu. Ôn lại một chút:
-
\(\log\) của một tích bằng tổng của các \(\log\).
-
vì rằng \(\log\) là một hàm đồng biến, một biểu thức sẽ là lớn nhất nếu \(\log\) của nó là lớn nhất, và ngược lại.
Bài toán Maximum Likelihood được đưa về bài toán Maximum Log-likelihood: \[ \theta = \max_{\theta} \sum_{n = 1}^N \log\left(p(\mathbf{x}_n | \theta)\right) ~~~~ (4) \]
Bạn vẫn chưa hiểu? Không lo, bây giờ chúng ta sẽ làm một vài ví dụ.
2.3. Ví dụ
2.3.1. Ví dụ 1: Bernoulli distribution
Bài toán: giả sử tung một đồng xu \(N\) lần và nhận được \(n\) mặt head. Tính xác suất có một mặt head khi tung đồng xu đó ở lần tiếp theo.
Lời giải: Một cách trực quan nhất, ta có thể dự đoán được rằng xác suất đó chính là \(\lambda = \frac{n}{N}\). Tuy nhiên, là một người muốn biết ngọn ngành vấn đề, bạn có thể chưa cảm thấy thuyết phục, và muốn biết liệu có cơ sở toán học vững chắc hơn chứng minh việc đó không.
Việc này có thể thực hiện bằng Maximum Likelihood.
Thật vậy, giả sử \(\lambda\) là xác suất để nhận được một mặt head. Đặt \(x_1, x_2, \dots, x_N\) là các đầu ra nhận được, trong đó có \(n\) giá trị bằng 1 tương ứng với mặt head và \(m = N - n\) giá trị bằng 0 tương ứng với mặt tail. Ta có thể suy ra ngay: \[ \sum_{i=1}^N x_i = n, ~~N - \sum_{i=1}^N x_i = N - n = m \]
Có thể nhận thấy việc nhận được mặt head hay tail khi tung đồng xu tuân theo Bernoulli distribution:
\[ p(x_i | \lambda) = \lambda^{x_i} ( 1- \lambda)^{1 - x_i} \]
Khi đó tham số mô hình \(\lambda\) có thể được đánh giá bằng việc giải bài toán tối ưu:
\[
\begin{eqnarray}
\lambda & = & \arg\max_{\lambda}\left[ p(x_1, x_2, \dots, x_N | \lambda)\right] \
& = & \arg\max_{\lambda} \left[\prod_{i = 1}^N p(x_i | \lambda)\right] & (5) \
& = & \arg\max_{\lambda} \left[\prod_{i=1}^N \lambda^{x_i} ( 1- \lambda)^{1 - x_i}\right] & (6)\
& = & \arg\max_{\lambda} \left[\lambda^{\sum_{i=1}^N x_i} (1 - \lambda)^{N - \sum_{i=1}^N x_i}\right] & (7) \
& = & \arg\max_{\lambda} \left[\lambda^{n} (1 - \lambda)^{m}\right] & (8)\
& = & \arg\max_{\lambda} \left[ n\log(\lambda) + m\log(1 - \lambda) \right] & (9)
\end{eqnarray}
\]
ở trên, tôi đã giả sử rằng kết quả của mỗi lần tung đồng xu là độc lập với nhau. Từ \((8)\) sang \((9)\) ta đã lấy \(\log\) của hàm mục tiêu.
Tới đây, bài toán tối ưu \((9)\) có thể được giải bằng cách lấy đạo hàm của hàm mục tiêu bằng 0. Tức \(\lambda\) là nghiệm của phương trình:
\[
\begin{eqnarray}
\frac{n}{\lambda} - \frac{m}{1 - \lambda} & = & 0 \
\Leftrightarrow \frac{n}{\lambda} & = & \frac{m}{1 - \lambda} \
\Leftrightarrow \lambda & = & \frac{n}{n + m} = \frac{n}{N}
\end{eqnarray}
\]
Vậy kết quả ta khẳng định ở trên là có cơ sở.
2.3.2. Ví dụ 2: Categorical distribution
Một ví dụ khác khó hơn một chút.
Bài toán: giả sử tung một viên xúc xắc 6 mặt có xác suất rơi vào các mặt có thể không đều nhau. Giả sử trong \(N\) lần tung, số lượng xuất hiện các mặt thứ nhất, thứ hai,…, thứ sáu lần lượt là \(n_1, n_2, \dots, n_6\) lần với \(\sum_{i=1}^6 n_i = N\). Tính xác suất rơi vào mỗi mặt ở lần tung tiếp theo.
Lời giải:
Bài toán này có vẻ phức tạp hơn bài toán trên một chút, nhưng ta cũng có thể dự đoán được đánh giá tốt nhất của xác suất rơi vào mặt thứ \(i\) là \(\lambda_i = \frac{n_i}{N}\).
Mã hoá mỗi quan sát đầu ra thứ \(i\) bởi một vector 6 chiều \(\mathbf{x}_i \in \{0, 1\}^6\) trong đó các phần tử của nó bằng 0 trừ phần tử tương ứng với mặt quan sát được là bằng 1. (Cách làm này giống với one-hot encoding). Ta cũng có thể suy ra: \[ \begin{eqnarray} \sum_{i=1}^N x^j_i = n_j, ~ \forall j = 1, 2, \dots, 6 \end{eqnarray} \] trong đó \(x^j_i\) là thành phần thứ \(j\) của vector \(\mathbf{x}_i\).
Có thể thấy rằng xác suất rơi vào mỗi mặt tuân theo Categorical distribution với các tham số \(\lambda_j > 0, j = 1, 2, \dots, 6\) (ta bỏ qua trường hợp tầm thường khi có một \(\lambda_j = 0\)). Ta dùng \(\lambda\) để thể hiện cho cả 6 tham số này. Với các tham số này, xác suất để sự kiện \(\mathbf{x}_i\) xảy ra là:
\[ \begin{eqnarray} p(\mathbf{x}_i | \lambda) = \prod_{j = 1}^6 \lambda_j^{x_i^j} \end{eqnarray} \]
Khi đó, vẫn với giả sử về sự độc lập giữa các lần tung xúc xắc, đánh giá bộ tham số \(\lambda\) dựa trên Maximum log-likelihood ta có:
\[
\begin{eqnarray}
\lambda & = & \arg\max_{\lambda} \left[ p(\mathbf{x}_1, \dots, \mathbf{x}_N | \lambda) \right]\
& = & \arg\max_{\lambda} \left[ \prod_{i=1}^N p(\mathbf{x}_i | \lambda) \right] & (10) \
& = & \arg\max_{\lambda} \left[ \prod_{i=1}^N \prod_{j = 1}^6 \lambda_j^{x_i^j} \right] & (11) \
& = & \arg\max_{\lambda} \left[ \prod_{j = 1}^6 \lambda_j^{\sum_{i=1}^N x_i^j} \right] & (12) \
& = & \arg\max_{\lambda} \left[ \prod_{j = 1}^6 \lambda_j^{n_j} \right] & (13) \
& = & \arg\max_{\lambda} \left[ \sum_{j=1}^6 n_j\log(\lambda_j) \right] & (14) \
\end{eqnarray}
\]
Khác với bài toán \((9)\) một chút, chúng ta không được quên điều kiện \(\sum_{j=1}^6 \lambda_j = 1\). Vậy ta có bài toán tối ưu có ràng buộc:
\[
\begin{eqnarray}
\max_{\lambda} & \sum_{j=1}^6 n_j\log(\lambda_j) \
\text{subject to:} & \sum_{j=1}^6 \lambda_j = 1~~~~~~~~ (15)
\end{eqnarray}
\]
Bài toán tối ưu này có thể được giải bằng phương pháp nhân tử Lagrange.
Lagrangian của bài toán này là: \[ \mathcal{L}(\lambda, \mu) = \sum_{j=1}^6 n_j\log(\lambda_j) + \mu (1- \sum_{j=1}^6 \lambda_j) \]
Nghiệm của bài toán là nghiệm của hệ đạo hàm của \(\mathcal{L}(.)\) theo từng biến bằng 0:
\[
\begin{eqnarray}
\frac{\partial \mathcal{L}(\lambda, \mu)}{\partial \lambda_j} & = & \frac{n_j}{\lambda_j} - \mu & = & 0, ~~ \forall j = 1, 2, \dots, 6 ~~~~ (16) \
\frac{\partial \mathcal{L}(\lambda, \mu)}{\partial \mu} & = & 1-\sum_{j=1}^6 \lambda_j & = & 0 ~~~~ (17)
\end{eqnarray}
\]
Từ \((16)\) ta có \(\lambda_j = \frac{n_j}{\mu}\). Thay vào \((17)\): \[ \sum_{j=1}^6 \frac{n_j}{\mu} = 1 \Rightarrow \mu = \sum_{j=1}^6 n_j = N \]
Từ đó ta có đánh giá: \[ \lambda_j = \frac{n_j}{N}, ~~\forall j = 1, 2, \dots, 6 \]
Qua hai ví dụ trên ta thấy Maximum Likelihood cho kết quả hợp lý.
2.3.3. Ví dụ 3: Univariate normal distribution
Bài toán: Khi thực hiện một phép đo, giả sử rằng rất khó để có thể đo chính xác độ dài của một vật. Thay vào đó, người ta thường đo vật đó nhiều lần rồi suy ra kết quả, với giả thiết rằng các phép đo là độc lập với nhau và kết quả mỗi phép đo là một phân phối chuẩn. Đánh giá chiều dài của vật đó.
Lời giải:
Vì ta biết rằng kết quả phép đo tuân theo phân phối chuẩn nên ta sẽ cố gắng đi xây dựng phân phối chuẩn đó. Chiều dài của vật có thể được coi là giá trị mà hàm mật độ xác suất đạt giá trị cao nhất. Trong phân phối chuẩn, ta biết rằng đó chính là kỳ vọng của phân phối đó. Chú ý rằng kỳ vọng của phân phối và kỳ vọng của dữ liệu quan sát được có thể không bằng nhau, chúng chỉ xấp xỉ bằng nhau khi mà số lượng phép đó là một số rất lớn.
Tuy nhiên, nếu đánh giá kỳ vọng của phân phối như cách làm dưới đây sử dụng Maximum Likelihood, ta sẽ thấy rằng kỳ vọng của dữ liệu chính là đánh giá tốt nhất cho kỳ vọng của phân phối.
Thật vậy, giả sử các kích thước quan sát được là \(x_1, x_2, \dots, x_N\). Ta cần đi tìm một phân phối chuẩn, tức một giá trị kỳ vọng \(\mu\) và phương sai \(\sigma^2\), sao cho các giá trị \(x_1, x_2, \dots, x_N\) là likely nhất.
Ta đã biết rằng, hàm mật độ xác suất tại \(x_i\) của một phân phối chuẩn có kỳ vọng \(\mu\) và phương sai \(\sigma^2\) là: \[ p(x_i | \mu, \sigma^2) = \frac{1}{\sqrt{2\pi \sigma^2}} \exp\left(-\frac{(x_i - \mu)^2}{2\sigma^2}\right) \]
Vậy, để đánh giá \(\mu\) và \(\sigma\), ta sử dụng Maximum likelihood với giả thiết rằng kết quả các phép đo là độc lập:
\[
\begin{eqnarray}
\mu, \sigma & = & \arg\max_{\mu, \sigma} \left[ \prod_{i=1}^N p(x_i | \mu, \sigma^2)\right] & (18)\
& = & \arg\max_{\mu, \sigma} \left[ \frac{1}{(2\pi \sigma^2)^{N/2}} \exp\left(-\frac{\sum_{i=1}^N (x_i - \mu)^2}{2\sigma^2} \right) \right] & (19)\
& = & \arg\max_{\mu, \sigma}\left[ -N\log(\sigma) - \frac{\sum_{i=1}^N (x_i - \mu)^2}{2\sigma^2}\right] \triangleq \arg\max_{\mu, \sigma} J(\mu, \sigma)(20)
\end{eqnarray}
\]
Ta đã lấy \(\log\) của hàm bên trong dấu ngoặc vuông của \((19)\) để được \((20)\), phần hằng số có chứa \(2\pi\) cũng được bỏ đi vì nó không ảnh hưởng tới kết quả.
Một lần nữa, để tìm \(\mu\) và \(\sigma\), ta giải hệ phương trình đạo hàm của \(J(\mu, \sigma)\) theo mỗi biến bằng 0:
\[
\begin{eqnarray}
\frac{\partial J}{\partial \mu} & = & \frac{1}{\sigma^2}\sum_{i=1}^N(x_i - \mu) = 0 & (21) \
\frac{\partial J}{\partial \sigma} & = & -\frac{N}{\sigma} + \frac{1}{\sigma^3} \sum_{i=1}^N (x_i - \mu)^2 & (22)
\end{eqnarray}
\]
Từ đó ta có:
\[
\begin{eqnarray}
\mu & = & \frac{\sum_{i=1}^N x_i}{N} & (23)\
\sigma^2 & = & \frac{\sum_{i=1}^N (x_i - \mu)^2}{N} & (24)
\end{eqnarray}
\]
Đây chính là công thức đánh giá hai giá trị kỳ vọng và phương sai của dữ liệu mà chúng ta quen dùng.
2.3.4. Ví dụ 4: Multivariate normal distribution
Bài toán: Giả sử tập dữ liệu ta thu được là các giá trị nhiều chiều \(\mathbf{x}_1, \dots, \mathbf{x}_N\). Giả sử thêm rằng dữ liệu này tuân theo phân phối chuẩn nhiều chiều. Hãy đánh giá các tham số, vector kỳ vọng \(\mu\) và ma trận hiệp phương sai \(\Sigma\), của phân phối này dựa trên Maximum Likelihood, giả sử rằng các \(\mathbf{x}_1, \dots, \mathbf{x}_N\) là độc lập.
Lời giải:
Việc chứng minh các công thức:
\[
\begin{eqnarray}
\mu & = & \frac{\sum_{i=1}^N \mathbf{x}_i}{N} \
\Sigma & = & \frac{1}{N}\sum_{i=1}^N (\mathbf{x} - \mu)(\mathbf{x} - \mu)^T
\end{eqnarray}
\]
xin được dành lại cho bạn đọc như một bài tập nhỏ. Dưới đây là một vài gợi ý:
- Hàm mật độ xác suất của phân phối chuẩn nhiều chiều là: \[ p(\mathbf{x} | \mu, \Sigma) = \frac{1}{(2\pi)^{D/2} |\Sigma|^{1/2}} \exp \left(-\frac{1}{2} (\mathbf{x} - \mu)^T \Sigma^{-1} (\mathbf{x} - \mu)\right) ~~~ (33) \] Chú ý rằng ma trận hiệp phương sai \(\Sigma\) là ma trận xác định dương nên có nghịch đảo.
- Một vài đạo hàm theo ma trận: \[ \nabla_{\Sigma} \log |\Sigma| = (\Sigma^{-1})^T \triangleq \Sigma^{-T}~~~ \text{(transpose of inversion)} \]
\[ \nabla_{\Sigma} (\mathbf{x}_i - \mu)^T \Sigma^{-1} (\mathbf{x}_i-\mu) = -\Sigma^{-T}(\mathbf{x}_i - \mu)(\mathbf{x}_i - \mu)^T\Sigma^{-T} \] (Xem thêm Matrix Calculus, mục D.2.1 và D.2.4.)
3. Maximum a Posteriori
3.1. Ý tưởng
Quay lại với ví dụ 1 về tung đồng xu. Nếu tung 5 lần và chỉ nhận được 1 mặt head, theo Maximum Likelihood, xác suất để có một mặt head được đánh giá là \(1/5\). Nếu tung đồng xu 5000 lần và nhận được 1000 lần head, ta có thể đánh giá xác suất của head là \(1/5\) và việc đánh giá này là đáng tin. Tuy nhiên, vì chỉ có 5 kết quả, thật khó để kết luận rằng kết quả là \(1/5\). Nếu kết luận ngay kết quả là \(1/5\), rất có thể chúng ta đã bị overfitting.
Khi có quá ít dữ kiện, tương ứng với hiện tượng có quá ít dữ liệu trong training (low-training) chúng ta cần phải tự suy ra một vài giả thiết của các tham số. Chẳng hạn, với việc tung đồng xu, giả thiết của chúng ta là xác suất nhận được mặt head phải gần \(1/2\).
Maximum A Posteriori (MAP) ra đời nhằm giải quyết vấn đề này. Trong MAP, chúng ta giới thiệu một giả thiết biết trước, được gọi là prior, của tham số \(\theta\). Từ những kinh nghiệm trước đây, chúng ta có thể suy ra các khoảng giá trị và phân bố của tham số.
Ngược với MLE, trong MAP, chúng ta sẽ đánh giá tham số như là một conditional probability của dữ liệu: \[ \theta = \arg\max_{\theta} \underbrace{p(\theta | \mathbf{x}_1, \dots, \mathbf{x}_N)}_{\text{posterior}} ~~~~~~~ (34) \]
Biểu thức \(p(\theta | \mathbf{x}_1, \dots, \mathbf{x}_N) \) còn được gọi là posterior probability của \(\theta\). Chính vì vậy mà việc đánh giá \(\theta\) theo \((34)\) được gọi là Maximum A Posteriori.
Thông thường, hàm tối ưu trong \((34)\) khó xác định dạng một cách trực tiếp. Chúng ta thường biết điều ngược lại, tức nếu biết tham số, ta có thể tính được hàm mật độ xác suất của dữ liệu. Vì vậy, để giải bải toán MAP, ta thường sử dụng Bayes’ rule. Bài toán MAP thường được biến đổi thành:
\[
\begin{eqnarray}
\theta & = & \arg\max_{\theta} p(\theta | \mathbf{x}_1, \dots, \mathbf{x}_N) \
& = & \arg\max_{\theta} \left[ \frac{\overbrace{p(\mathbf{x}_1, \dots, \mathbf{x}_N | \theta)}^{\text{likelihood}} \overbrace{p(\theta)}^{\text{prior}}}{\underbrace{p(\mathbf{x}_1, \dots, \mathbf{x}_N)}_{\text{evidence}}} \right] & (35)\
& = & \arg\max_{\theta} \left[ p(\mathbf{x}_1, \dots, \mathbf{x}_N | \theta) p(\theta) \right] & (36) \
& = & \arg\max_{\theta} \left[ \prod_{i=1}^N p(\mathbf{x}_i | \theta) p(\theta) \right] & (37)
\end{eqnarray}
\]
Đẳng thức \((35)\) xảy ra là do Bayes’ rule.
Đẳng thức \((36)\) xảy ra vì mẫu số của \((35)\) không phụ thuộc vào tham số \(\theta\).
Đẳng thức \((37)\) xảy ra nếu chúng ta giả thiết về sự độc lập giữa các \(\mathbf{x}_i\). Chú ý rằng giả thiết độc lập thường xuyên được sử dụng.
Như vậy, điểm khác biệt lớn nhất giữa hai bài toán tối ưu MLE và MAP là việc hàm mục tiêu của MAP có thêm \(p(\theta)\), tức phân phối của \(\theta\). Phân phối này chính là những thông tin ta biết trước về \(\theta\) và được gọi là prior. Ta có kết luận: posteriori tỉ lệ thuận với tích của likelihood và prior.
Việc lựa chọn các prior như thế nào, chúng ta cùng làm quen với khái niệm mới: Conjugate prior.
3.2. Conjugate prior
Khi nhân một phân phối \(p_1\) một phân phối \(p_2\) khác, kết quả thu được tỉ lệ thuận với một phân phối có dạng giống như phân phối \(p_2\), ta nói \(p_2\) là conjugate distribution của \(p_1\). Nếu điều này xảy ra, việc tối ưu bài toán MAP sẽ trở nên tương tự như việc tôi ưu bài toán MLE vì nghiệm có cấu trúc giống nhau.
Nếu posterior distribution \(p(\theta | \mathbf{X})\) và likelihood \(p(\mathbf{X} |\theta)\) có cùng họ (family), thì prior distribution là conjugate distribution của likelihood distribution.
Tôi sẽ không đi sâu vào phần này, bạn đọc có thể đọc thêm Conjugate prior. Tôi sẽ nêu một vài cặp các conjugate distributions:
-
Nếu likelihood function là một Gaussian (phân phối chuẩn), và prior cho vector kỳ vọng cũng là một Gaussian, thế thì posterior distribution cũng là một Gaussian. Ta nói rằng Gaussian family conjugate với chính nó (hoặc còn gọi là self-conjugate).
-
Nếu likelihood function là một Gaussian (phân phối chuẩn), và prior cho phương sai là một gamma distribution, thì posterior distribution cũng là một Gaussian. Ta nói rằng gamma distribution là conjugate prior cho độ chính xác của Gaussian. Chú ý rằng phương sai có thể được coi là một biến giúp đo độ chính xác của mô hình. Phương sai càng nhỏ thì độ chính xác càng cao.
-
Beta distribution là conjugate của Bernoulli distribution.
-
Dirichlet distribution là conjugate của Categorical distribution.
3.3. Hyperparameters
Chúng ta sẽ cùng xem xét một ví dụ nhỏ với Bernoulli distribution: \[ p(x | \lambda) = \lambda^x ( 1 - \lambda)^{1 - x} \]
Và conjugate của nó, Beta distribution, có hàm mật độ xác suất:
\[ p(\lambda) = \frac{\Gamma(\alpha + \beta)}{\Gamma(\alpha) \Gamma(\beta)} \lambda^{\alpha - 1} ( 1 - \lambda) ^{\beta - 1} \] Bỏ qua thừa số hằng số chỉ mang mục đích chuẩn hoá cho tích phân của hàm mật độ xác suất bằng 1, ta có thể nhận thấy rằng phần còn lại của Beta distribution có cùng họ với Bernoulli distribution.
Cụ thể, nếu sử dụng Beta distribution làm prior cho tham số \(\lambda\), và bỏ qua phần thừa số hằng số, posterior sẽ có dạng:
\[
\begin{eqnarray}
p(\lambda | x) & \propto & p(x | \lambda) p(\lambda) \
& \propto & \lambda^{x + \alpha - 1}(1 - \lambda)^{1 - x + \beta - 1} ~~~ (38)
\end{eqnarray}
\]
trong đó, \(\propto\) là ký hiệu của tỉ lệ với.
Nhận thấy rằng \((38)\) vẫn có dạng của một Bernoulli distribution. Chính vì vậy mà Beta distribution được gọi là một conjugate prior cho Bernoulli distribution.
Trong ví dụ này, tham số \(\lambda\) phụ thuộc vào hai tham số khác là \(\alpha\) và \(\beta\). Để tránh nhầm lẫn, hai tham số \((\alpha, \beta)\) được gọi là siêu tham số (hyperparameters).
Quay trở lại ví dụ về bài toán tung đồng xu \(N\) lần có \(n\) lần nhận được mặt head và \(m = N - n\) lần nhận được mặt tail. Nếu sử dụng MLE, ta nhận được đánh giá \(\lambda = n/M\). Nếu sử dụng MAP với prior là một \(\text{Beta}[\alpha, \beta]\) thì sao:
Bài toán tối ưu MAP:
\[
\begin{eqnarray}
\lambda & = & \arg\max_{\lambda} \left[p(x_1, \dots, x_N | \lambda) p(\lambda) \right] \
& = & \arg\max_{\lambda} \left[\left(\prod_{i=1}^N \lambda^{x_i} ( 1- \lambda)^{1 - x_i}\right) \lambda^{\alpha - 1} ( 1 - \lambda)^{\beta - 1} \right] \
& = & \arg\max_{\lambda} \left[ \lambda^{\sum_{i = 1}^N x_i + \alpha - 1} ( 1- \lambda)^{N - \sum_{i=1}^N x_i + \beta - 1} \right] \
& = & \arg\max_{\lambda} \left[ \lambda^{n + \alpha - 1} ( 1- \lambda)^{m + \beta - 1} \right] ~~~ (39)
\end{eqnarray}
\]
Bài toán tối ưu \((39)\) chính là bài toán tối ưu \((8)\) với tham số thay đổi một chút. Tương tự như \((8)\), nghiệm của \((39)\) có thể được suy ra là:
\[ \lambda = \frac{n + \alpha - 1}{N + \alpha + \beta - 2} ~~~ (40) \]
Chính việc chọn prior phù hợp, ở đây là conjugate prior, mà posterior và likelihood có dạng giống nhau, khiến cho việc tối ưu bài toán MAP được thuận lợi.
Việc còn lại là chọn cặp hyperparameters \(\alpha\) và \(\beta\).
Chúng ta cùng xem lại hình dạng của Beta distribution và nhận thấy rằng khi \(\alpha = \beta > 1\), ta có hàm mật độ xác suất của Beta distribution đối xứng qua điểm 0.5 và đạt giá trị cao nhất tại 0.5. Xét Hình 1, ta nhận thấy rằng khi \(\alpha = \beta > 1\) thì \(\lambda\) có xu hướng đi về điểm 0.5, xu hướng này càng mạnh nên giá trị của chúng càng cao.
Nếu ta chọn \(\alpha = \beta = 1\), ta thấy đây là uniform distribution vì đồ thị hàm mật độ xác suất là 1 đường thẳng. Lúc này, xác suất của \(\lambda\) tại mọi vị trí trong khoảng \([0, 1]\) là như nhau. Thực chất, nếu ta thay \(\alpha = \beta = 1\) vào \((40)\) ta sẽ thu được \(\lambda = n/N\), chính là đánh giá thu được bằng MLE. MLE là một trường hợp đặc biệt của MAP khi prior là một uniform distribution.
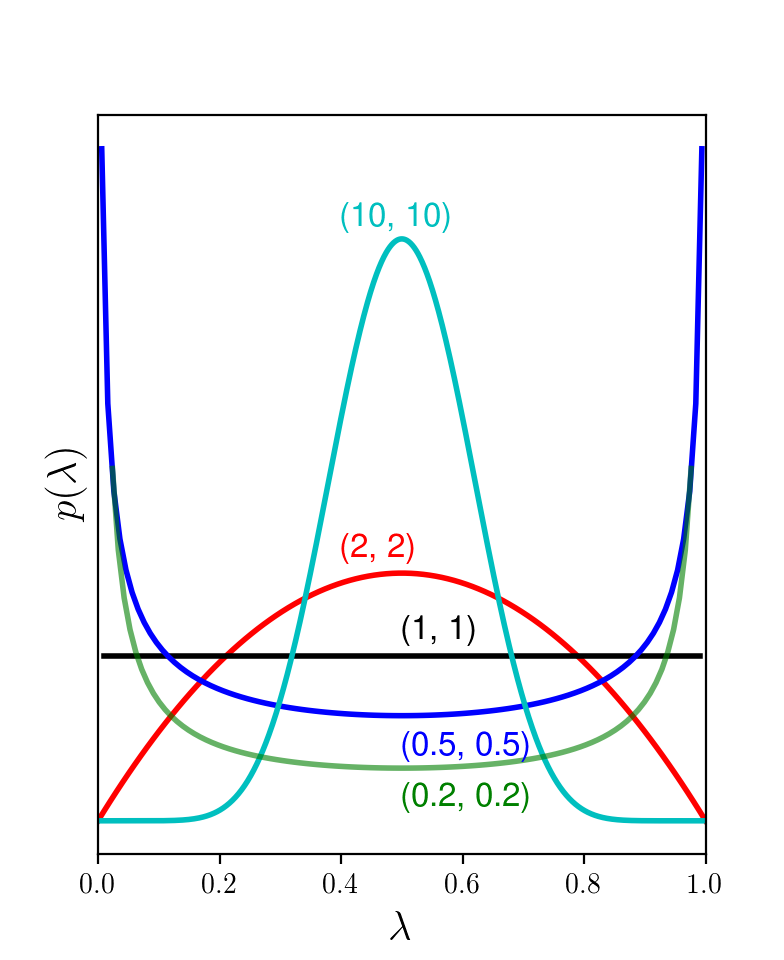
|
Hình 1: Đồ thị hàm mật độ xác suất của Beta distribution khi \(\alpha = \beta\) và nhận các giá trị khác nhau. Khi cả hai giá trị này lớn, xác suất để \(\lambda\) gần 0.5 sẽ cao hơn. |
Nếu ta chọn \(\alpha = \beta = 2\), ta sẽ thu được: \[ \lambda= \frac{n + 1}{N + 2} \]
Chẳng hạn khi \(N = 5, n = 1\) như trong ví dụ. MLE cho kết quả \(\lambda = 1/5\), MAP sẽ cho kết quả \(\lambda = 2/6 = 1/3\).
Nếu chọn \(\alpha = \beta = 10\) ta sẽ có \(\lambda = (1 + 9)/(5 + 18) = 10/23\). Ta thấy rằng khi \(\alpha = \beta\) và càng lớn thì ta sẽ thu được \(\lambda\) càng gần \(1/2\). Điều này có thể dễ nhận thấy vì prior nhận giá trị rất cao tại 0.5 khi các hyperparameters \(\alpha = \beta\) lớn.
3.4. MAP giúp tránh overfitting
Việc chọn các hyperparameter thường được dựa trên thực nghiệm, bằng cross-validation chẳng hạn. Việc thử nhiều bộ tham số rồi chọn ra bộ tốt nhất là việc mà các kỹ sư machine learning thường xuyên phải đối mặt. Cũng giống như chọn regularization parameter để tránh overfitting vậy.
Rõ ràng MAP cho chúng ta các kết quả linh hoạt (flexible) với sự thay đổi của hyperparameters. Và là một cách để tránh overfitting.
Nếu viết lại bài toán MAP dưới dạng:
\[
\begin{eqnarray}
\theta & = & \arg\max_{\theta} p(\mathbf{X}| \theta) p(\theta) \
& = & \arg\max_{\lambda} \left[ \log \underbrace{p(\mathbf{X}| \theta)}_{\text{likelihood}} + \log \underbrace{p(\theta)}_{\text{prior}} \right]
\end{eqnarray}
\]
ta có thể thấy rằng đây giống như kỹ thuật regularization với \(\log\) của likelihood được coi như phần loss chính, \(\log\) của prior đóng vai trò như phần regularization. Nếu không có regularization, ta được bài toán Maximum (log-)likelihood.
4. Tóm tắt
-
Khi sử dụng các mô hình thống kê Machine Learning, chúng ta thường xuyên phải đi đánh giá các tham số của mô hình, đại diện cho các tham số của các phân phối xác suất. Tập hợp tham số mô hình thường được ký hiệu là \(\theta\). Có hai phương pháp phổ biến được sử dụng để đánh giá \(\theta\) là Maximum Likelihood Estimation (MLE) và Maximum A Posteriori Estimation (MAP).
-
Với MLE, việc xác định tham số \(\theta\) được thực hiện bằng cách đi tìm các tham số sao cho xác suất của training data (sự thật), hay còn gọi là likelihood, là lớn nhất, : \[ \theta = \arg\max_{\theta} p(\mathbf{x}_1, \dots, \mathbf{x}_N |\theta) \]
-
Để giải bài toán tối ưu này, giả thiết các dữ liệu \(\mathbf{x}_i\) độc lập thường được sử dụng. Và bài toán MLE trở thành: \[ \theta = \arg\max_{\theta} \prod_{i=1}^N p(\mathbf{x}_i | \theta) \]
- Với MAP, các tham số được đánh giá bằng cách tối đa posterior: \[ \theta = \arg\max_{\theta} p(\theta | \mathbf{x}_1, \dots, \mathbf{x}_N) \]
-
Để giải bài toán này, ta thường sử dụng Bayes’ rule và giả thiết độc lập của dữ liệu: \[ \theta = \arg\max_{\theta} \left[\prod_{i=1}^N p(\mathbf{x}_i | \theta) p(\theta) \right] \] Hàm mục tiêu chính là tích của likelihood và prior.
-
Prior thường được chọn dựa trên các thông tin biết trước của tham số, và phân phối được chọn thường là các conjugate distribution với likelihood, tức các distribution khiến việc nhân thêm prior vẫn giữ được cấu trúc giống như likelihood.
-
MAP có thể được coi là một phương pháp giúp tránh overfitting (hoặc overconfidence). MAP thường mang lại hiệu quả cao hơn MLE với trường hợp có ít dữ liệu training.
- Trong bài tiếp theo, chúng ta sẽ thấy rõ ưu điểm của MAP trong một trong 10 thuật toán cần biết trong Machine Learning - Naive Bayes Classifier. Mời bạn đón đọc.
5. Tài liệu tham khảo
[1] Chapter 4, 6 của Computer Vision: Models, Learning, and Inference - Simon J.D. Prince
[2] Conjugate prior